Initial commit
This commit is contained in:
@@ -0,0 +1,61 @@
|
||||
---
|
||||
|
||||
slug: /vector-data-type
|
||||
---
|
||||
|
||||
# Overview of vector data types
|
||||
|
||||
seekdb provides vector data types to support AI vector search applications. By using vector data types, you can store and query an array of floating-point numbers, such as `[0.1, 0.3, -0.9, ...]`. Before using vector data, you need to be aware of the following:
|
||||
|
||||
* Both dense and sparse vector data are supported, and all data elements must be single-precision floating-point numbers.
|
||||
|
||||
* Element values in vector data cannot be NaN (not a number) or Inf (infinity); otherwise, a runtime error will be thrown.
|
||||
|
||||
* You must specify the vector dimension when creating a vector column, for example, `VECTOR(3)`.
|
||||
|
||||
* Creating dense/sparse vector indexes is supported. For details, see [vector index](../200.vector-index/200.dense-vector-index.md).
|
||||
|
||||
* Vector data in seekdb is stored in array form.
|
||||
|
||||
* Both dense and sparse vectors support [hybrid search](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001970893).
|
||||
|
||||
## Syntax
|
||||
|
||||
A dense vector value can contain any number of floating-point numbers up to 16,000. The syntax is as follows:
|
||||
|
||||
```sql
|
||||
-- Dense vector
|
||||
'[<float>, <float>, ...]'
|
||||
```
|
||||
|
||||
A sparse vector is based on the MAP data type and contains unordered key-value pairs. The syntax is as follows:
|
||||
|
||||
```sql
|
||||
-- Sparse vector
|
||||
'{<uint:float>, <uint:float>...}'
|
||||
```
|
||||
|
||||
Examples of creating vector columns and indexes are as follows:
|
||||
|
||||
```sql
|
||||
-- Create a dense vector column and index
|
||||
CREATE TABLE t1(
|
||||
c1 INT,
|
||||
c2 VECTOR(3),
|
||||
PRIMARY KEY(c1),
|
||||
VECTOR INDEX idx1(c2) WITH (distance=L2, type=hnsw)
|
||||
);
|
||||
```
|
||||
|
||||
```sql
|
||||
-- Create a sparse vector column
|
||||
CREATE TABLE t2 (
|
||||
c1 INT,
|
||||
c2 SPARSEVECTOR
|
||||
);
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Create vector indexes](../200.vector-index/200.dense-vector-index.md)
|
||||
* [Use SQL functions](../250.vector-function.md)
|
||||
@@ -0,0 +1,391 @@
|
||||
---
|
||||
|
||||
slug: /vector-sdk-refer
|
||||
---
|
||||
|
||||
# Compatibility
|
||||
|
||||
This topic describes the data model mappings, SDK interface compatibility, and concept mappings between seekdb's vector search feature and Milvus.
|
||||
|
||||
## Concept mappings
|
||||
|
||||
To help users familiar with Milvus quickly get started with seekdb's vector storage capabilities, we analyze the similarities and differences between the two systems and provide a mapping of related concepts.
|
||||
|
||||
### Data models
|
||||
|
||||
| **Data model layer** | **Milvus** | **seekdb** | **Description** |
|
||||
|------------|---------|-----------|-----------|
|
||||
| First layer | Shards | Partition | Milvus specifies partition rules by setting some columns as `partition_key` in the schema definition.<br/>seekdb supports range/range columns, list/list columns, hash, key, and subpartitioning strategies. |
|
||||
| Second layer | Partitions | ≈Tablet | Milvus enhances read performance by chunking the same shard (shards are usually partitioned by primary key) based on other columns.<br />seekdb implements this by sorting keys within a partition. |
|
||||
| Third layer | Segments | MemTable+SSTable | Both have a minor compaction mechanism. |
|
||||
|
||||
### SDKs
|
||||
|
||||
This section introduces the conceptual differences between seekdb's vector storage SDK (pyobvector) and Milvus's SDK (pymilvus).
|
||||
|
||||
pyobvector supports two usage modes:
|
||||
|
||||
1. pymilvus MilvusClient lightweight compatible mode: This mode is compatible with common interfaces of Milvus clients. Users familiar with Milvus can easily use this mode without concept mapping.
|
||||
|
||||
2. SQLAlchemy extension mode: This mode can be used as a vector feature extension of python SQLAlchemy, retaining the operation mode of a relational database. Concept mapping is required.
|
||||
|
||||
For more information about pyobvector's APIs, see [pyobvector Python SDK API reference](900.vector-search-supported-clients-and-languages/200.vector-pyobvector.md).
|
||||
|
||||
The following table describes the concept mappings between pyobvector's SQLAlchemy extension mode and pymilvus:
|
||||
|
||||
| **pymilvus** | **pyobvector** | **Description** |
|
||||
|---------|------------|---------------|
|
||||
| Database | Database | Database |
|
||||
| Collection | Table | Table |
|
||||
| Field | Column | Column |
|
||||
| Primary Key | Primary Key | Primary key |
|
||||
| Vector Field | Vector Column | Vector column |
|
||||
| Index | Index | Index |
|
||||
| Partition | Partition | Partition |
|
||||
| DataType | DataType | Data type |
|
||||
| Metric Type | Distance Function | Distance function |
|
||||
| Search | Query | Query |
|
||||
| Insert | Insert | Insert |
|
||||
| Delete | Delete | Delete |
|
||||
| Update | Update | Update |
|
||||
| Batch | Batch | Batch operations |
|
||||
| Transaction | Transaction | Transaction |
|
||||
| NONE | Not supported| NULL value |
|
||||
| BOOL | Boolean | Corresponds to the MySQL TINYINT type |
|
||||
| INT8 | Boolean | Corresponds to the MySQL TINYINT type |
|
||||
| INT16 | SmallInteger | Corresponds to the MySQL SMALLINT type |
|
||||
| INT32 | Integer | Corresponds to the MySQL INT type |
|
||||
| INT64 | BigInteger | Corresponds to the MySQL BIGINT type |
|
||||
| FLOAT | Float | Corresponds to the MySQL FLOAT type |
|
||||
| DOUBLE | Double | Corresponds to the MySQL DOUBLE type |
|
||||
| STRING | LONGTEXT | Corresponds to the MySQL LONGTEXT type |
|
||||
| VARCHAR | STRING | Corresponds to the MySQL VARCHAR type |
|
||||
| JSON | JSON | For differences and similarities in JSON operations, see [pyobvector Python SDK API reference](900.vector-search-supported-clients-and-languages/200.vector-pyobvector.md). |
|
||||
| FLOAT_VECTOR | VECTOR | Vector type |
|
||||
| BINARY_VECTOR | Not supported | |
|
||||
| FLOAT16_VECTOR | Not supported | |
|
||||
| BFLOAT16_VECTOR | Not supported | |
|
||||
| SPARSE_FLOAT_VECTOR | Not supported | |
|
||||
| dynamic_field | Not needed | The hidden `$meta` metadata column in Milvus.<br/>In seekdb, you can explicitly create a JSON-type column. |
|
||||
|
||||
## Compatibility with Milvus
|
||||
|
||||
### Milvus SDK
|
||||
|
||||
Except `load_collection()`, `release_collection()`, and `close()`, which are supported through SQLAlchemy, all operations listed in the following tables are supported.
|
||||
|
||||
**Collection operations**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| create_collection() | Creates a vector table based on the given schema. |
|
||||
| get_collection_stats() | Queries table statistics, such as the number of rows. |
|
||||
| describe_collection() | Provides detailed metadata of a vector table. |
|
||||
| has_collection() | Checks whether a table exists. |
|
||||
| list_collections() | Lists existing tables. |
|
||||
| drop_collection() | Drops a table. |
|
||||
|
||||
**Field and schema definition**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| create_schema() | Creates a schema in memory and adds column definitions. |
|
||||
| add_field() | The call sequence is: create_schema->add_field->...->add_field<br/>You can also manually build a FieldSchema list and then use the CollectionSchema constructor to create a schema. |
|
||||
|
||||
**Vector indexes**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| list_indexes() | Lists all indexes. |
|
||||
| create_index() | Supports creating multiple vector indexes in a single call. First, use prepare_index_params to initialize an index parameter list object, call add_index multiple times to set multiple index parameters, and finally call create_index to create the indexes. |
|
||||
| drop_index() | Drops a vector index. |
|
||||
| describe_index() | Gets the metadata (schema) of an index. |
|
||||
|
||||
**Vector indexes**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| search() | ANN query interface:<ul><li>collection_name: the table name</li><li>data: the query vectors</li><li>filter: filtering operation, equivalent to `WHERE`</li><li>limit: top K</li><li>output_fields: projected columns, equivalent to `SELECT`</li><li>partition_names: partition names (not supported in Milvus Lite)</li><li>anns_field: the index column name</li><li>search_params: vector distance function name and index algorithm-related parameters</li></ul> |
|
||||
| query() | Point query with filter, namely `SELECT ... WHERE ids IN (..., ...) AND <filters>`. |
|
||||
| get() | Point query without filter, namely `SELECT ... WHERE ids IN (..., ...)`. |
|
||||
| delete() | Deletes a group of vectors, `DELETE FROM ... WHERE ids IN (..., ...)`. |
|
||||
| insert() | Inserts a group of vectors. |
|
||||
| upsert() | Insert with update on primary key conflict. |
|
||||
|
||||
**Collection metadata synchronization**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| load_collection() | Loads the table structure from the database to the Python application memory, enabling the application to operate the database table in an object-oriented manner. This is a standard feature of an object-relational mapping (ORM) framework. |
|
||||
| release_collection() | Releases the loaded table structure from the Python application memory and releases related resources. This is a standard feature of an ORM framework for memory management. |
|
||||
| close() | Closes the database connection and releases related resources. This is a standard feature of an ORM framework. |
|
||||
|
||||
### pymilvus
|
||||
|
||||
#### Data model
|
||||
|
||||
The data model of Milvus comprises three levels: Shards->Partitions->Segments. Compatibility with seekdb is described as follows:
|
||||
|
||||
* Shards correspond to seekdb's Partition concept.
|
||||
|
||||
* Partitions currently have no corresponding concept in seekdb.
|
||||
|
||||
* Milvus allows you to partition a shard into blocks by other columns to improve read performance (shards are usually partitioned by primary key). seekdb implements this by sorting by primary key within a partition.
|
||||
|
||||
* Segments are similar to [MemTable](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001973721) + [SSTable](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001973722).
|
||||
|
||||
#### Milvus Lite API compatibility
|
||||
|
||||
##### collection operations
|
||||
|
||||
1. Milvus create_collection():
|
||||
|
||||
```python
|
||||
create_collection(
|
||||
collection_name: str,
|
||||
dimension: int,
|
||||
primary_field_name: str = "id",
|
||||
id_type: str = DataType,
|
||||
vector_field_name: str = "vector",
|
||||
metric_type: str = "COSINE",
|
||||
auto_id: bool = False,
|
||||
timeout: Optional[float] = None,
|
||||
schema: Optional[CollectionSchema] = None, # Used for custom setup
|
||||
index_params: Optional[IndexParams] = None, # Used for custom setup
|
||||
**kwargs,
|
||||
) -> None
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* collection_name: compatible, corresponds to table_name.
|
||||
|
||||
* dimension: compatible, vector(dim).
|
||||
|
||||
* primary_field_name: compatible, the primary key column name.
|
||||
|
||||
* id_type: compatible, the primary key column type.
|
||||
|
||||
* vector_field_name: compatible, the vector column name.
|
||||
|
||||
* auto_id: compatible, auto increment.
|
||||
|
||||
* timeout: compatible, seekdb supports it through hint.
|
||||
|
||||
* schema: compatible.
|
||||
|
||||
* index_params: compatible.
|
||||
|
||||
2. Milvus get_collection_stats():
|
||||
|
||||
```python
|
||||
get_collection_stats(
|
||||
collection_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> Dict
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* API is compatible.
|
||||
|
||||
* Return value is compatible: `{ 'row_count': ... }`.
|
||||
|
||||
3. Milvus has_collection():
|
||||
|
||||
```python
|
||||
has_collection(
|
||||
collection_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> Bool
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus has_collection().
|
||||
|
||||
4. Milvus drop_collection():
|
||||
|
||||
```python
|
||||
drop_collection(collection_name: str) -> None
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus drop_collection().
|
||||
|
||||
5. Milvus rename_collection():
|
||||
|
||||
```python
|
||||
rename_collection(
|
||||
old_name: str,
|
||||
new_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> None
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus rename_collection().
|
||||
|
||||
##### Schema-related
|
||||
|
||||
1. Milvus create_schema():
|
||||
|
||||
```python
|
||||
create_schema(
|
||||
auto_id: bool,
|
||||
enable_dynamic_field: bool,
|
||||
primary_field: str,
|
||||
partition_key_field: str,
|
||||
) -> CollectionSchema
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* auto_id: whether the primary key column is auto-increment, compatible.
|
||||
|
||||
* primary_field & partition_key_field: compatible.
|
||||
|
||||
2. Milvus add_field():
|
||||
|
||||
```python
|
||||
add_field(
|
||||
field_name: str,
|
||||
datatype: DataType,
|
||||
is_primary: bool,
|
||||
max_length: int,
|
||||
element_type: str,
|
||||
max_capacity: int,
|
||||
dim: int,
|
||||
is_partition_key: bool,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus add_field().
|
||||
|
||||
##### Insert/Search-related
|
||||
|
||||
1. Milvus search():
|
||||
|
||||
```python
|
||||
search(
|
||||
collection_name: str,
|
||||
data: Union[List[list], list],
|
||||
filter: str = "",
|
||||
limit: int = 10,
|
||||
output_fields: Optional[List[str]] = None,
|
||||
search_params: Optional[dict] = None,
|
||||
timeout: Optional[float] = None,
|
||||
partition_names: Optional[List[str]] = None,
|
||||
**kwargs,
|
||||
) -> List[dict]
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* filter: string expression. For usage examples, see: [Milvus Filtering Explained](https://milvus.io/docs/boolean.md). It is generally similar to SQL's `WHERE` expression.
|
||||
|
||||
* search_params:
|
||||
|
||||
* metric_type: compatible.
|
||||
|
||||
* radius & range filter: related to RNN, currently not supported.
|
||||
|
||||
* group_by_field: groups ANN results, currently not supported.
|
||||
|
||||
* max_empty_result_buckets: used for IVF series indexes, currently not supported.
|
||||
|
||||
* ignore_growing: skips incremental data and directly reads baseline index, currently not supported.
|
||||
|
||||
* partition_names: partition read, supported.
|
||||
|
||||
* kwargs:
|
||||
|
||||
* offset: the number of records to skip in search results, currently not supported.
|
||||
|
||||
* round_decimal: rounds results to specified decimal places, currently not supported.
|
||||
|
||||
2. Milvus get():
|
||||
|
||||
```python
|
||||
get(
|
||||
collection_name: str,
|
||||
ids: Union[list, str, int],
|
||||
output_fields: Optional[List[str]] = None,
|
||||
timeout: Optional[float] = None,
|
||||
partition_names: Optional[List[str]] = None,
|
||||
**kwargs,
|
||||
) -> List[dict]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus get().
|
||||
|
||||
3. Milvus delete()
|
||||
|
||||
```python
|
||||
delete(
|
||||
collection_name: str,
|
||||
ids: Optional[Union[list, str, int]] = None,
|
||||
timeout: Optional[float] = None,
|
||||
filter: Optional[str] = "",
|
||||
partition_name: Optional[str] = "",
|
||||
**kwargs,
|
||||
) -> dict
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus delete().
|
||||
|
||||
4. Milvus insert()
|
||||
|
||||
```python
|
||||
insert(
|
||||
collection_name: str,
|
||||
data: Union[Dict, List[Dict]],
|
||||
timeout: Optional[float] = None,
|
||||
partition_name: Optional[str] = "",
|
||||
) -> List[Union[str, int]]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus insert().
|
||||
|
||||
5. Milvus upsert()
|
||||
|
||||
```python
|
||||
upsert(
|
||||
collection_name: str,
|
||||
data: Union[Dict, List[Dict]],
|
||||
timeout: Optional[float] = None,
|
||||
partition_name: Optional[str] = "",
|
||||
) -> List[Union[str, int]]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus upsert().
|
||||
|
||||
##### Index-related
|
||||
|
||||
1. Milvus create_index()
|
||||
|
||||
```python
|
||||
create_index(
|
||||
collection_name: str,
|
||||
index_params: IndexParams,
|
||||
timeout: Optional[float] = None,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus create_index().
|
||||
|
||||
2. Milvus drop_index()
|
||||
|
||||
```python
|
||||
drop_index(
|
||||
collection_name: str,
|
||||
index_name: str,
|
||||
timeout: Optional[float] = None,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus drop_index().
|
||||
|
||||
## Compatibility with MySQL protocol
|
||||
|
||||
* In terms of request initiation: All APIs are implemented through general query SQL, and there are no compatibility issues.
|
||||
|
||||
* In terms of response result set processing: Only processing of new vector data elements needs to be considered. Currently, string and bytes element parsing are supported. Even if the transmission mode of vector data elements changes in the future, compatibility can be achieved by updating the SDK.
|
||||
@@ -0,0 +1,12 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-supported-clients-and-languages-overview
|
||||
---
|
||||
|
||||
# Supported clients and languages for vector search
|
||||
|
||||
| Client/Language | Version |
|
||||
|---|---|
|
||||
| MySQL client | All versions |
|
||||
| Python SDK | 3.9+ |
|
||||
| Java SDK | 1.8 |
|
||||
@@ -0,0 +1,318 @@
|
||||
---
|
||||
|
||||
slug: /vector-pyobvector
|
||||
---
|
||||
|
||||
# pyobvector Python SDK API reference
|
||||
|
||||
pyobvector is the Python SDK for seekdb's vector storage feature. It provides two operating modes:
|
||||
|
||||
* pymilvus-compatible mode: Operates the database using the MilvusLikeClient object, offering commonly used APIs compatible with the lightweight MilvusClient.
|
||||
|
||||
* SQLAlchemy extension mode: Operates the database using the ObVecClient object, serving as an extension of Python's SDK for relational databases.
|
||||
|
||||
This topic describes the APIs in the two modes and provides examples.
|
||||
|
||||
## MilvusLikeClient
|
||||
|
||||
### Constructor
|
||||
|
||||
```python
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
uri: str = "127.0.0.1:2881",
|
||||
user: str = "root@test",
|
||||
password: str = "",
|
||||
db_name: str = "test",
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
### collection-related APIs
|
||||
|
||||
| API | Description | Example |
|
||||
|------|------|------|
|
||||
| `def create_schema(self, **kwargs) -> CollectionSchema:` | <ul>Creates a `CollectionSchema` object.<li>Parameters are optional, allowing the initialization of an empty schema definition.</li><li>Optional parameters include:</li><ul><li>`fields`: A list of `FieldSchema` objects (see the `add_field` interface below for details).</li><li>`partitions`: Partitioning rules (see the section on defining partition rules using `ObPartition`).</li><li>`description`: Compatible with Milvus, but currently has no practical effect in seekdb.</li></ul></ul> | |
|
||||
| `def create_collection(<br/>self,<br/>collection_name: str,<br/>dimension: Optional[int] = None,<br/>primary_field_name: str = "id",<br/>id_type: Union[DataType, str] = DataType.INT64,<br/>vector_field_name: str = "vector",<br/>metric_type: str = "l2",<br/>auto_id: bool = False,<br/>timeout: Optional[float] = None,<br/>schema: Optional[CollectionSchema] = None, # Used for custom setup<br/>index_params: Optional[IndexParams] = None, # Used for custom setup<br/>max_length: int = 16384,<br/>**kwargs,<br/>)` | Creates a table: <ul><li>collection_name: the table name</li><li>dimension: the vector data dimension</li><li>primary_field_name: the primary field name</li><li>id_type: the primary field data type (only supports VARCHAR and INT types)</li><li>vector_field_name: the vector field name</li><li>metric_type: not used in seekdb, but maintained for API compatibility (because the main table definition does not need to specify a vector distance function)</li><li>auto_id: specifies whether the primary field value increases automatically</li><li>timeout: not used in seekdb, but maintained for API compatibility</li><li>schema: the custom collection schema. When `schema` is not None, the parameters from dimension to metric_type will be ignored</li><li>index_params: the custom vector index parameters</li><li>max_length: the maximum varchar length when the primary field data type is VARCHAR and `schema` is not None</li></ul> | `client.create_collection(<br/>collection_name=test_collection_name,<br/>schema=schema,<br/>index_params=idx_params,<br/>)` |
|
||||
| `def get_collection_stats(<br/>self, collection_name: str, timeout: Optional[float] = None # pylint: disable=unused-argument<br/>) -> Dict:` | Queries the record count of a table.<ul><li>collection_name: the table name</li><li>timeout: not used in seekdb, but maintained for API compatibility</li></ul> | |
|
||||
| `def has_collection(self, collection_name: str, timeout: Optional[float] = None) -> bool` | Verifies whether a table exists.<ul><li>collection_name: the table name</li><li>timeout: not used in seekdb, but maintained for API compatibility</li></ul> | |
|
||||
| `def drop_collection(self, collection_name: str) -> None` | Drops a table.<ul><li>collection_name: the table name</li></ul> | |
|
||||
| `def load_table(self, collection_name: str,)` | Reads the metadata of a table to the SQLAlchemy metadata cache.<ul><li>collection_name: the table name</li></ul> | |
|
||||
|
||||
### CollectionSchema & FieldSchema
|
||||
|
||||
MilvusLikeClient describes the schema of a table by using a CollectionSchema. A CollectionSchema contains multiple FieldSchemas, and a FieldSchema describes the column schema of a table.
|
||||
|
||||
#### Create a CollectionSchema by using the create_schema method of the MilvusLikeClient
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
fields: Optional[List[FieldSchema]] = None,
|
||||
partitions: Optional[ObPartition] = None,
|
||||
description: str = "", # ignored in oceanbase
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* fields: an optional parameter that specifies a list of FieldSchema objects.
|
||||
|
||||
* partitions: partition rules (for more information, see the ObPartition section).
|
||||
|
||||
* description: compatible with Milvus, but currently has no practical effect in seekdb.
|
||||
|
||||
#### Create a FieldSchema and register it to a CollectionSchema
|
||||
|
||||
```python
|
||||
def add_field(self, field_name: str, datatype: DataType, **kwargs)
|
||||
```
|
||||
|
||||
* field_name: the column name.
|
||||
|
||||
* datatype: the column data type. For supported data types, see [Compatibility reference](../800.vector-sdk-refer.md).
|
||||
|
||||
* kwargs: additional parameters for configuring column properties, as shown below:
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
name: str,
|
||||
dtype: DataType,
|
||||
description: str = "",
|
||||
is_primary: bool = False,
|
||||
auto_id: bool = False,
|
||||
nullable: bool = False,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* is_primary: specifies whether the column is a primary key.
|
||||
|
||||
* auto_id: specifies whether the column value increases automatically.
|
||||
|
||||
* nullable: specifies whether the column can be null.
|
||||
|
||||
#### Example
|
||||
|
||||
```python
|
||||
schema = self.client.create_schema()
|
||||
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
|
||||
schema.add_field(field_name="title", datatype=DataType.VARCHAR, max_length=512)
|
||||
schema.add_field(
|
||||
field_name="title_vector", datatype=DataType.FLOAT_VECTOR, dim=768
|
||||
)
|
||||
schema.add_field(field_name="link", datatype=DataType.VARCHAR, max_length=512)
|
||||
schema.add_field(field_name="reading_time", datatype=DataType.INT64)
|
||||
schema.add_field(
|
||||
field_name="publication", datatype=DataType.VARCHAR, max_length=512
|
||||
)
|
||||
schema.add_field(field_name="claps", datatype=DataType.INT64)
|
||||
schema.add_field(field_name="responses", datatype=DataType.INT64)
|
||||
|
||||
self.client.create_collection(
|
||||
collection_name="medium_articles_2020", schema=schema
|
||||
)
|
||||
```
|
||||
|
||||
### Index-related APIs
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def create_index(<br/>self,<br/>collection_name: str,<br/>index_params: IndexParams,<br/>timeout: Optional[float] = None,<br/>**kwargs,<br/>)` | Creates a vector index table based on the constructed IndexParams (for more information about how to use IndexParams, see the prepare_index_params and add_index APIs).<ul><li>collection_name: the table name</li><li>index_params: the index parameters</li><li>timeout: not used in seekdb, but maintained for API compatibility</li><li>kwargs: other parameters, currently not used, maintained for compatibility</li></ul> | |
|
||||
| `def drop_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>timeout: Optional[float] = None,<br/>**kwargs,<br/>)` | Drops an index table.<ul><li>collection_name: the table name</li><li>index_name: the index name</li></ul> | |
|
||||
| `def refresh_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>trigger_threshold: int = 10000,<br/>)` | Refreshes a vector index table to improve read performance. It can be understood as a process of moving incremental data.<ul><li>collection_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the refresh action. A refresh is triggered when the data volume of the index table exceeds the threshold.</li></ul> | An API introduced
|
||||
| `def rebuild_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>trigger_threshold: float = 0.2,<br/>)` | Rebuilds a vector index table to improve read performance. It can be understood as a process of merging incremental data into baseline index data.<ul><li>collection_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the rebuild action. The value range is 0 to 1. A rebuild is triggered when the proportion of incremental data to full data reaches the threshold.</li></ul> | An API introduced by seekdb.<br/>Not compatible with Milvus. |
|
||||
| `def search(<br/>self,<br/>collection_name: str,<br/>data: list,<br/>anns_field: str,<br/>with_dist: bool = False,<br/>filter=None,limit: int = 10,output_fields: Optional[List[str]] = None,<br/>search_params: Optional[dict] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Executes a vector approximate nearest neighbor search.<ul><li>collection_name: the table name</li><li>data: the vector data to be searched</li><li>anns_field: the name of the vector column to be searched</li><li>with_dist: specifies whether to return results with vector distances</li><li>filter: uses vector approximate nearest neighbor search with filter conditions</li><li>limit: top K</li><li>output_fields: the output columns (also known as projection columns)</li><li>search_params: supports only the `metric_type` value of `l2`/`neg_ip` (`for example: search_params = {"metric_type": "neg_ip"}`)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul><ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values.</ul> | `res = self.client.search(<br/>collection_name=test_collection_name,<br/>data=[0, 0, 1],<br/>anns_field="embedding",<br/>limit=5,<br/>output_fields=["id"],<br/>search_params={"metric_type": "neg_ip"}<br/>)<br/>self.assertEqual(<br/> set([r['id'] for r in res]), set([12, 111, 11, 112, 10]))` |
|
||||
| `def query(<br/>self,<br/>collection_name: str,<br/>flter=None,<br/>output_fields: Optional[List[str]] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Reads data records using the specified filter condition.<ul><li>collection_name: the table name</li><li>flter: uses vector approximate nearest neighbor search with filter conditions</li><li>output_fields: the output columns (also known as projection columns)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul><ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values.</ul> | `table = self.client.load_table(collection_name=test_collection_name)<br/>where_clause = [table.c["id"] < 100]<br/>res = self.client.query(<br/> collection_name=test_collection_name,<br/> output_fields=["id"],<br/> flter=where_clause,<br/>)` |
|
||||
| `def get(<br/>self,<br/>collection_name: str,<br/>ids: Union[list, str, int],<br/>output_fields: Optional[List[str]] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Retrieves records based on the specified primary keys `ids`:<ul><li>collection_name: the table name</li><li>ids: a single ID or a list of IDs. Note: The ids parameter of MilvusLikeClient get interface is different from ObVecClient get. For details, see <a href="#DML%20operations">ObVecClient get</a></li><li>output_fields: the output columns (also known as projection columns)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values. | `res = self.client.get(<br/> collection_name=test_collection_name,<br/> output_fields=["id", "meta"],<br/> ids=[80, 12, 112],<br/>)` |
|
||||
| `def delete(<br/>self,<br/>collection_name: str,<br/>ids: Optional[Union[list, str, int]] = None,<br/>timeout: Optional[float] = None, # pylint: disable=unused-argument<br/>flter=None,<br/>partition_name: Optional[str] = "",<br/>**kwargs, # pylint: disable=unused-argument<br/>)` | Deletes data in a collection.<ul><li>collection_name: the table name</li><li>ids: a single ID or a list of IDs</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>flter: uses vector approximate nearest neighbor search with filter conditions</li><li>partition_name: limits the deletion operation to a partition</li></ul> | `self.client.delete(<br/> collection_name=test_collection_name, ids=[12, 112], partition_name="p0"<br/>)` |
|
||||
| `def insert(<br/> self, <br/> collection_name: str, <br/> data: Union[Dict, List[Dict]], <br/> timeout: Optional[float] = None, <br/> partition_name: Optional[str] = ""<br/>)` | Inserts data into a table.<ul><li>collection_name: the table name</li><li>data: the data to be inserted, described in Key-Value form</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_name: limits the insertion operation to a partition</li></ul> | `data = [<br/> {"id": 12, "embedding": [1, 2, 3], "meta": {"doc": "document 1"}},<br/> {<br/> "id": 90,<br/> "embedding": [0.13, 0.123, 1.213],<br/> "meta": {"doc": "document 1"},<br/> },<br/> {"id": 112, "embedding": [1, 2, 3], "meta": None},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": None},<br/>]<br/>self.client.insert(collection_name=test_collection_name, data=data)` |
|
||||
| `def upsert(<br/>self,<br/>collection_name: str,<br/>data: Union[Dict, List[Dict]],<br/>timeout: Optional[float] = None, # pylint: disable=unused-argument<br/>partition_name: Optional[str] = "",<br/>) -> List[Union[str, int]]` | Updates data in a table. If a primary key already exists, updates the corresponding record; otherwise, inserts a new record.<ul><li>collection_name: the table name</li><li>data: the data to be inserted or updated, in the same format as the insert interface</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_name: limits the operation to a specified partition</li></ul> | `data = [<br/> {"id": 112, "embedding": [1, 2, 3], "meta": {'doc':'hhh1'}},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": {'doc':'hhh2'}},<br/>]<br/>self.client.upsert(collection_name=test_collection_name, data=data)` |
|
||||
| `def perform_raw_text_sql(self, text_sql: str):<br/> return super().perform_raw_text_sql(text_sql)` | Executes an SQL statement directly.<ul><li>text_sql: the SQL statement to be executed</li></ul>Return value:<br/>Returns an iterator that provides result sets from SQLAlchemy. | |
|
||||
|
||||
## ObVecClient
|
||||
|
||||
### Constructor
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
uri: str = "127.0.0.1:2881",
|
||||
user: str = "root@test",
|
||||
password: str = "",
|
||||
db_name: str = "test",
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
### Table mode-related operations
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def check_table_exists(self, table_name: str)` | Checks whether a table exists.<ul><li>table_name: the table name</li></ul> | |
|
||||
| `def create_table(<br/>self,<br/>table_name: str,<br/>columns: List[Column],<br/>indexes: Optional[List[Index]] = None,<br/>partitions: Optional[ObPartition] = None,<br/>)` | Creates a table.<ul><li>table_name: the table name</li><li>columns: the column schema of the table, defined using SQLAlchemy</li><li>indexes: a set of index schemas, defined using SQLAlchemy</li><li>partitions: optional partition rules (see the section on using ObPartition to define partition rules)</li></ul> | |
|
||||
| `@classmethod<br/>def prepare_index_params(cls)` | Creates an IndexParams object to record the schema definition of a vector index table.`class IndexParams:<br/> """Vector index parameters for MilvusLikeClient"<br/> def __init__(self):<br/> self._indexes = {}`<br/>The definition of IndexParams is very simple, with only one dictionary member internally<br/>that stores a mapping from a tuple of (column name, index name) to an IndexParam structure.<br/>The constructor of the IndexParam class is:`def __init__(<br/> self,<br/> index_name: str,<br/> field_name: str,<br/> index_type: Union[VecIndexType, str],<br/> **kwargs<br/>)`<ul><li>index_name: the vector index table name</li><li>field_name: the vector column name</li><li>index_type: an enumerated class for vector index algorithm types. Currently, only HNSW is supported.</li></ul>After obtaining an IndexParams by calling `prepare_index_params`, you can register an IndexParam using the `add_index` interface:`def add_index(<br/> self,<br/> field_name: str,<br/> index_type: VecIndexType,<br/> index_name: str,<br/> **kwargs<br/>)`The parameter meanings are the same as those in the IndexParam constructor. | Here is a usage example for creating a vector index: `idx_params = self.client.prepare_index_params()<br/>idx_params.add_index(<br/> field_name="title_vector",<br/> index_type="HNSW",<br/> index_name="vidx_title_vector",<br/> metric_type="L2",<br/> params={"M": 16, "efConstruction": 256},<br/>)<br/>self.client.create_collection(<br/> collection_name=test_collection_name,<br/> schema=schema,<br/> <br/>index_params=idx_params,<br/>)`Note that the `prepare_index_params` function is recommended for use in MilvusLikeClient, not in ObVecClient. In ObVecClient mode, you should use the `create_index` interface to define a vector index table. (For details, see the create_index interface.) |
|
||||
| `def create_table_with_index_params(<br/>self,<br/>table_name: str,<br/>columns: List[Column],<br/>indexes: Optional[List[Index]] = None,<br/>vidxs: Optional[IndexParams] = None,<br/>partitions: Optional[ObPartition] = None,<br/>) | Creates a table and a vector index at the same time using optional index_params.<ul><li>table_name: the table name</li><li>columns: the column schema of the table, defined using SQLAlchemy</li><li>indexes: a set of index schemas, defined using SQLAlchemy</li><li>vidxs: the vector index schema, specified using IndexParams</li><li>partitions: optional partition rules (see the section on using ObPartition to define partition rules)</li></ul> | Recommended for use in MilvusLikeClient, not recommended for use in ObVecClient |
|
||||
| `def create_index(<br/>self,<br/>table_name: str,<br/>is_vec_index: bool,<br/>index_name: str,<br/>column_names: List[str],<br/>vidx_params: Optional[str] = None,<br/>**kw,<br/>)` | Supports creating both normal indexes and vector indexes.<ul><li>table_name: the table name</li><li>is_vec_index: specifies whether to create a normal index or a vector index</li><li>index_name: the index name</li><li>column_names: the columns on which to create the index</li><li>vidx_params: the vector index parameters, for example: `"distance=l2, type=hnsw, lib=vsag"`</li></ul>Currently, seekdb supports only `type=hnsw` and `lib=vsag`. Please retain these settings. The distance can be set to `l2` or `inner_product`. | `self.client.create_index(<br/> test_collection_name,<br/> is_vec_index=True,<br/> index_name="vidx",<br/> column_names=["embedding"],<br/> vidx_params="distance=l2, type=hnsw, lib=vsag",<br/>) |
|
||||
| `def create_vidx_with_vec_index_param(<br/>self,<br/>table_name: str,<br/>vidx_param: IndexParam,<br/>)` | Creates a vector index using vector index parameters.<ul><li>table_name: the table name</li><li>vidx_param: the vector index parameters constructed using IndexParam</li></ul> | |
|
||||
| `def drop_table_if_exist(self, table_name: str)` | Drops a table.<ul><li>table_name: the table name</li></ul> | |
|
||||
| `def drop_index(self, table_name: str, index_name: str)` | Drops an index.<ul><li>table_name: the table name</li><li>index_name: the index name</li></ul> | |
|
||||
| `def refresh_index(<br/>self,<br/>table_name: str,<br/>index_name: str,<br/>trigger_threshold: int = 10000,<br/>)` | Refreshes a vector index table to improve read performance. It can be understood as a process of moving incremental data.<ul><li>table_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the refresh action. A refresh is triggered when the data volume of the index table exceeds the threshold.</li></ul> | |
|
||||
| `def rebuild_index(<br/>self,<br/>table_name: str,<br/>index_name: str,<br/>trigger_threshold: float = 0.2,<br/>)` | Rebuilds a vector index table to improve read performance. It can be understood as a process of merging incremental data into baseline index data.<ul><li>table_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the rebuild action. The value range is 0 to 1. A rebuild is triggered when the proportion of incremental data to full data reaches the threshold.</li></ul> | |
|
||||
|
||||
### DML operations
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def insert(<br/>self,<br/>table_name: str,<br/>data: Union[Dict, List[Dict]],<br/>partition_name: Optional[str] = "",<br/>)` | Inserts data into a table.<ul><li>table_name: the table name</li><li>data: the data to be inserted, described in Key-Value form</li><li>partition_name: limits the insertion operation to a partition</li></ul> | `vector_value1 = [0.748479, 0.276979, 0.555195]<br/>vector_value2 = [0, 0, 0]<br/>data1 = [{"id": i, "embedding": vector_value1} for i in range(10)]<br/>data1.extend([{"id": i, "embedding": vector_value2} for i in range(10, 13)])<br/>data1.extend([{"id": i, "embedding": vector_value2} for i in range(111, 113)])<br/>self.client.insert(test_collection_name, data=data1)` |
|
||||
| `def upsert(<br/>self,<br/>table_name: str,<br/>data: Union[Dict, List[Dict]],<br/>partition_name: Optional[str] = "",<br/>)` | Inserts or updates data in a table. If a primary key already exists, updates the corresponding record; otherwise, inserts a new record.<ul><li>table_name: the table name</li><li>data: the data to be inserted or updated, in Key-Value format</li><li>partition_name: limits the operation to a specified partition</li></ul> | |
|
||||
| `def update(<br/>self,<br/>table_name: str,<br/>values_clause,<br/>where_clause=None,<br/>partition_name: Optional[str] = "",<br/>)` | Updates data in a table. If a primary key is repeated, it will be replaced.<ul><li>table_name: the table name</li><li>values_clause: the values of the columns to be updated</li><li>where_clause: the condition for updating</li><li>partition_name: limits the update operation to some partitions</li></ul> | `data = [<br/> {"id": 112, "embedding": [1, 2, 3], "meta": {'doc':'hhh1'}},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": {'doc':'hhh2'}},<br/>]<br/>client.insert(collection_name=test_collection_name, data=data)<br/>client.update(<br/> table_name=test_collection_name,<br/> values_clause=[{'meta':{'doc':'HHH'}}],<br/> where_clause=[text("id=112")]<br/>)` |
|
||||
| `def delete(<br/>self,<br/>table_name: str,<br/>ids: Optional[Union[list, str, int]] = None,<br/>where_clause=None,<br/>partition_name: Optional[str] = "",<br/>)` | Deletes data from a table.<ul><li>table_name: the table name</li><li>ids: a single ID or a list of IDs</li><li>where_clause: the condition for deletion</li><li>partition_name: limits the deletion operation to some partitions</li></ul> | `self.client.delete(test_collection_name, ids=["bcd", "def"])` |
|
||||
| `def get(<br/>self,<br/>table_name: str,<br/>ids: Optional[Union[list, str, int]],<br/>where_clause = None,<br/>output_column_name: Optional[List[str]] = None,<br/>partition_names: Optional[List[str]] = None,<br/>)` | Retrieves records based on the specified primary keys `ids`.<ul><li>table_name: the table name</li><li>ids: a single ID or a list of IDs. Optional parameter, can be `ids=None` if not provided. The ids parameter of ObVecClient get interface is different from MilvusLikeClient get. For details, see <a href="#Index-related%20APIs">MilvusLikeClient get</a></li><li>where_clause: the condition for retrieval</li><li>output_column_name: a list of output column or projection column names</li><li>partition_names: limits the retrieval operation to some partitions</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | `res = self.client.get(<br/> test_collection_name,<br/> ids=["abc", "bcd", "cde", "def"],<br/> where_clause=[text("meta->'$.page' > 1")],<br/> output_column_name=['id']<br/>) |
|
||||
| `def set_ob_hnsw_ef_search(self, ob_hnsw_ef_search: int)` | Set the efSearch parameter of the HNSW index. This is a session-level variable. The larger the value of ef_search, the higher the recall rate but the poorer the query performance. <ul><li>ob_hnsw_ef_search: the efSearch parameter of the HNSW index</li></ul> | |
|
||||
| `def get_ob_hnsw_ef_search(self) -> int` | Get the efSearch parameter of the HNSW index. | |
|
||||
| `def ann_search(<br/>self,<br/>table_name: str,<br/>vec_data: list,<br/>vec_column_name: str,<br/>distance_func,<br/>with_dist: bool = False,<br/>topk: int = 10,<br/>output_column_names: Optional[List[str]] = None,<br/>extra_output_cols: Optional[List] = None,<br/>where_clause=None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>)` | Executes a vector approximate nearest neighbor search.<ul><li>table_name: the table name</li><li>vec_data: the vector data to be searched</li><li>vec_column_name: the name of the vector column to be searched</li><li>distance_func: the distance function. Provides an extension of SQLAlchemy func, with optional values: `func.l2_distance`/`func.cosine_distance`/`func.inner_product`/`func.negative_inner_product`, representing the l2 distance function, cosine distance function, inner product distance function, and negative inner product distance function, respectively</li><li>with_dist: specifies whether to return results with vector distances</li><li>topk: the number of nearest vectors to retrieve</li><li>output_column_names: a list of output column or projection column names</li><li>extra_output_cols: additional output columns that allow more complex output expressions</li><li>where_clause: the filter condition</li><li>partition_names: limits the query to some partitions</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | `res = self.client.ann_search(<br/> test_collection_name,<br/> vec_data=[0, 0, 0],<br/> vec_column_name="embedding",<br/> distance_func=func.l2_distance,<br/> with_dist=True,<br/> topk=5,<br/> output_column_names=["id"],<br/>) |
|
||||
| `def precise_search(<br/>self,<br/>table_name: str,<br/>vec_data: list,<br/>vec_column_name: str,<br/>distance_func,<br/>topk: int = 10,<br/>output_column_names: Optional[List[str]] = None,<br/>where_clause=None,<br/>**kwargs,<br/>) | Executes a precise neighbor search algorithm.<ul><li>table_name: the table name</li><li>vec_data: the query vector</li><li>vec_column_name: the vector column name</li><li>distance_func: the vector distance function. Provides an extension of SQLAlchemy func, with optional values: func.l2_distance/func.cosine_distance/func.inner_product/func.negative_inner_product, representing the l2 distance function, cosine distance function, inner product distance function, and negative inner product distance function, respectively</li><li>topk: the number of nearest vectors to retrieve</li><li>output_column_names: a list of output column or projection column names</li><li>where_clause: the filter condition</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | |
|
||||
| `def perform_raw_text_sql(self, text_sql: str)` | Executes an SQL statement directly.<ul><li>text_sql: the SQL statement to be executed</li></ul>Return value:<br/>Returns an iterator that provides result sets from SQLAlchemy. | |
|
||||
|
||||
## Define partitioning rules by using ObPartition
|
||||
|
||||
pyobvector supports the following types for range/range columns, list/list columns, hash, key, and subpartitioning:
|
||||
|
||||
* ObRangePartition: specifies to perform range partitioning. Set `is_range_columns` to `True` when you construct this object to create range column partitioning.
|
||||
|
||||
* ObListPartition: specifies to perform list partitioning. Set `is_list_columns` to `True` when you construct this object to create list column partitioning.
|
||||
|
||||
* ObHashPartition: specifies to perform hash partitioning.
|
||||
|
||||
* ObKeyPartition: specifies to perform key partitioning.
|
||||
|
||||
* ObSubRangePartition: specifies to perform sub-range partitioning. Set `is_range_columns` to `True` when you construct this object to create sub-range column partitioning.
|
||||
|
||||
* ObSubListPartition: specifies to perform sub-list partitioning. Set `is_list_columns` to `True` when you construct this object to create sub-list column partitioning.
|
||||
|
||||
* ObSubHashPartition: specifies to perform sub-hash partitioning.
|
||||
|
||||
* ObSubKeyPartition: specifies to perform sub-key partitioning.
|
||||
|
||||
### Example of range partitioning
|
||||
|
||||
```python
|
||||
range_part = ObRangePartition(
|
||||
False,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("p0", 100),
|
||||
RangeListPartInfo("p1", "maxvalue"),
|
||||
],
|
||||
range_expr="id",
|
||||
)
|
||||
```
|
||||
|
||||
### Example of list partitioning
|
||||
|
||||
```python
|
||||
list_part = ObListPartition(
|
||||
False,
|
||||
list_part_infos=[
|
||||
RangeListPartInfo("p0", [1, 2, 3]),
|
||||
RangeListPartInfo("p1", [5, 6]),
|
||||
RangeListPartInfo("p2", "DEFAULT"),
|
||||
],
|
||||
list_expr="col1",
|
||||
)
|
||||
```
|
||||
|
||||
### Example of hash partitioning
|
||||
|
||||
```python
|
||||
hash_part = ObHashPartition("col1", part_count=60)
|
||||
```
|
||||
|
||||
### Example of multi-level partitioning
|
||||
|
||||
```python
|
||||
# Perform range partitioning
|
||||
range_columns_part = ObRangePartition(
|
||||
True,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("p0", 100),
|
||||
RangeListPartInfo("p1", 200),
|
||||
RangeListPartInfo("p2", 300),
|
||||
],
|
||||
col_name_list=["col1"],
|
||||
)
|
||||
# Perform sub-range partitioning
|
||||
range_sub_part = ObSubRangePartition(
|
||||
False,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("mp0", 1000),
|
||||
RangeListPartInfo("mp1", 2000),
|
||||
RangeListPartInfo("mp2", 3000),
|
||||
],
|
||||
range_expr="col3",
|
||||
)
|
||||
range_columns_part.add_subpartition(range_sub_part)
|
||||
```
|
||||
|
||||
## Pure SQLAlchemy API mode
|
||||
|
||||
If you prefer to use a purely SQLAlchemy API for seekdb's vector retrieval functionality, you can obtain a synchronized database engine through the following methods:
|
||||
|
||||
* Method 1: Use ObVecClient to create a database engine
|
||||
|
||||
```python
|
||||
from pyobvector import ObVecClient
|
||||
|
||||
client = ObVecClient(uri="127.0.0.1:2881", user="test@test")
|
||||
engine = client.engine
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
* Method 2: Call the `create_engine` interface of ObVecClient to create a database engine
|
||||
|
||||
```python
|
||||
import pyobvector
|
||||
from sqlalchemy.dialects import registry
|
||||
from sqlalchemy import create_engine
|
||||
|
||||
uri: str = "127.0.0.1:2881"
|
||||
user: str = "root@test"
|
||||
password: str = ""
|
||||
db_name: str = "test"
|
||||
registry.register("mysql.oceanbase", "pyobvector.schema.dialect", "OceanBaseDialect")
|
||||
connection_str = (
|
||||
# mysql+oceanbase indicates using the MySQL standard with seekdb's synchronous driver.
|
||||
f"mysql+oceanbase://{user}:{password}@{uri}/{db_name}?charset=utf8mb4"
|
||||
)
|
||||
engine = create_engine(connection_str, **kwargs)
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
If you want to use asynchronous APIs of SQLAlchemy, you can use seekdb's asynchronous driver:
|
||||
|
||||
```python
|
||||
import pyobvector
|
||||
from sqlalchemy.dialects import registry
|
||||
from sqlalchemy.ext.asyncio import create_async_engine
|
||||
|
||||
uri: str = "127.0.0.1:2881"
|
||||
user: str = "root@test"
|
||||
password: str = ""
|
||||
db_name: str = "test"
|
||||
registry.register("mysql.aoceanbase", "pyobvector", "AsyncOceanBaseDialect")
|
||||
connection_str = (
|
||||
# mysql+aoceanbase indicates using the MySQL standard with seekdb's asynchronous driver.
|
||||
f"mysql+aoceanbase://{user}:{password}@{uri}/{db_name}?charset=utf8mb4"
|
||||
)
|
||||
engine = create_async_engine(connection_str)
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
## More examples
|
||||
|
||||
For more examples, visit the [pyobvector repository](https://github.com/oceanbase/pyobvector).
|
||||
@@ -0,0 +1,470 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-java-sdk
|
||||
---
|
||||
|
||||
# Java SDK API reference
|
||||
|
||||
obvec_jdbc is a Java SDK specifically designed for seekdb vector storage scenarios and JSON Table virtual table scenarios. This topic explains how to use obvec_jdbc.
|
||||
|
||||
## Installation
|
||||
|
||||
You can install obvec_jdbc using either of the following methods.
|
||||
|
||||
### Maven dependency
|
||||
|
||||
Add the obvec_jdbc dependency to the `pom.xml` file of your project.
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.oceanbase</groupId>
|
||||
<artifactId>obvec_jdbc</artifactId>
|
||||
<version>1.0.4</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
### Source code installation
|
||||
|
||||
1. Install obvec_jdbc.
|
||||
|
||||
```bash
|
||||
# Clone the obvec_jdbc repository.
|
||||
git clone https://github.com/oceanbase/obvec_jdbc.git
|
||||
# Go to the obvec_jdbc directory.
|
||||
cd obvec_jdbc
|
||||
# Install obvec_jdbc.
|
||||
mvn install
|
||||
```
|
||||
|
||||
2. Add the dependency.
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.oceanbase</groupId>
|
||||
<artifactId>obvec_jdbc</artifactId>
|
||||
<version>1.0.4</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
## API definition and usage
|
||||
|
||||
obvec_jdbc provides the `ObVecClient` object for working with seekdb's vector search features and JSON Table virtual table functionalities.
|
||||
|
||||
### Use vector search
|
||||
|
||||
#### Create a client
|
||||
|
||||
You can use the following interface definition to construct an ObVecClient object:
|
||||
|
||||
```java
|
||||
# uri: the connection string, which contains the address, port, and name of the database to which you want to connect.
|
||||
# user: the username.
|
||||
# password: the password.
|
||||
public ObVecClient(String uri, String user, String password);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.ObVecClient;
|
||||
|
||||
String uri = "jdbc:oceanbase://127.0.0.1:2881/test";
|
||||
String user = "root@test";
|
||||
String password = "";
|
||||
String tb_name = "JAVA_TEST";
|
||||
|
||||
ObVecClient ob = new ObVecClient(uri, user, password);
|
||||
```
|
||||
|
||||
#### ObFieldSchema class
|
||||
|
||||
This class is used to define the column schema of a table. The constructor is as follows:
|
||||
|
||||
```java
|
||||
# name: the column name.
|
||||
# dataType: the data type.
|
||||
public ObFieldSchema(String name, DataType dataType);
|
||||
```
|
||||
|
||||
The following table describes the data types supported by the class.
|
||||
|
||||
| Data type | Description |
|
||||
|---|---|
|
||||
| BOOL | Equivalent to TINYINT |
|
||||
| INT8 | Equivalent to TINYINT |
|
||||
| INT16 | Equivalent to SMALLINT |
|
||||
| INT32 | Equivalent to INT |
|
||||
| INT64 | Equivalent to BIGINT |
|
||||
| FLOAT | Equivalent to FLOAT |
|
||||
| DOUBLE | Equivalent to DOUBLE |
|
||||
| STRING | Equivalent to LONGTEXT |
|
||||
| VARCHAR | Equivalent to VARCHAR |
|
||||
| JSON | Equivalent to JSON |
|
||||
| FLOAT_VECTOR | Equivalent to VECTOR |
|
||||
|
||||
:::tip
|
||||
For more complex types, constraints, and other functionalities, you can use seekdb JDBC's interface directly instead of using obvec_jdbc.
|
||||
:::
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| String getName() | Obtains the column name. |
|
||||
| ObFieldSchema Name(String name) | Sets the column name and returns the object itself to support chain operations. |
|
||||
| ObFieldSchema DataType(DataType dataType) | Sets the data type. |
|
||||
| boolean getIsPrimary() | Specifies whether the column is the primary key. |
|
||||
| ObFieldSchema IsPrimary(boolean isPrimary) | Specifies whether the column is the primary key. |
|
||||
| ObFieldSchema IsAutoInc(boolean isAutoInc) | Specifies whether the column is auto-increment. <main id="notice" type='notice'><h4>Notice</h4><p>IsAutoInc takes effect only if IsPrimary is true. </p></main> |
|
||||
| ObFieldSchema IsNullable(boolean isNullable) | Specifies whether the column can contain NULL values. <main id="notice" type='notice'><h4>Notice</h4><p>IsNullable is set to false by default, which is different from the behavior in MySQL. </p></main> |
|
||||
| ObFieldSchema MaxLength(int maxLength) | Sets the maximum length for the VARCHAR data type. |
|
||||
| ObFieldSchema Dim(int dim) | Sets the dimension for the VECTOR data type. |
|
||||
|
||||
#### IndexParams/IndexParam
|
||||
|
||||
IndexParam is used to set a single index parameter. IndexParams is used to set a group of vector index parameters, which is used when multiple vector indexes are created on a table.
|
||||
|
||||
:::tip
|
||||
obvec_jdbc supports only the creation of vector indexes. To create other indexes, use seekdb JDBC.
|
||||
:::
|
||||
|
||||
The constructor of IndexParam is as follows:
|
||||
|
||||
```java
|
||||
# vidx_name: the index name.
|
||||
# vector_field_name: the name of the vector column.
|
||||
public IndexParam(String vidx_name, String vector_field_name);
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| IndexParam M(int m) | Sets the maximum number of neighbors for each vector in the HNSW algorithm. |
|
||||
| IndexParam EfConstruction(int ef_construction) | Sets the maximum number of candidate vectors for search during the construction of the HNSW algorithm. |
|
||||
| IndexParam EfSearch(int ef_search) | Sets the maximum number of candidate vectors for search in the HNSW algorithm. |
|
||||
| IndexParam Lib(String lib) | Sets the type of the vector library. |
|
||||
| IndexParam MetricType(String metric_type) | Sets the type of the vector distance function. |
|
||||
|
||||
The constructor of IndexParams is as follows:
|
||||
|
||||
```
|
||||
public IndexParams();
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| void addIndex(IndexParam index_param) | Adds an index definition. |
|
||||
|
||||
#### ObCollectionSchema class
|
||||
|
||||
When creating a table, you need to rely on the configuration of the ObCollectionSchema object. Below are its constructors and interfaces.
|
||||
|
||||
The constructor of ObCollectionSchema is as follows:
|
||||
|
||||
```java
|
||||
public ObCollectionSchema();
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| void addField(ObFieldSchema field) | Adds a column definition. |
|
||||
| void setIndexParams(IndexParams index_params) | Sets the vector index parameters of the table. |
|
||||
|
||||
#### Drop a table
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
public void dropCollection(String table_name);
|
||||
```
|
||||
|
||||
#### Check whether a table exists
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
public boolean hasCollection(String table_name);
|
||||
```
|
||||
|
||||
#### Create a table
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the table to be created.
|
||||
# collection: an ObCollectionSchema object that specifies the schema of the table.
|
||||
public void createCollection(String table_name, ObCollectionSchema collection);
|
||||
```
|
||||
|
||||
You can use ObFieldSchema, ObCollectionSchema, and IndexParams to create a table. Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.DataType;
|
||||
import com.oceanbase.obvec_jdbc.ObCollectionSchema;
|
||||
import com.oceanbase.obvec_jdbc.ObFieldSchema;
|
||||
import com.oceanbase.obvec_jdbc.IndexParam;
|
||||
import com.oceanbase.obvec_jdbc.IndexParams;
|
||||
|
||||
# Define the schema of the table.
|
||||
ObCollectionSchema collectionSchema = new ObCollectionSchema();
|
||||
ObFieldSchema c1_field = new ObFieldSchema("c1", DataType.INT32);
|
||||
c1_field.IsPrimary(true).IsAutoInc(true);
|
||||
ObFieldSchema c2_field = new ObFieldSchema("c2", DataType.FLOAT_VECTOR);
|
||||
c2_field.Dim(3).IsNullable(false);
|
||||
ObFieldSchema c3_field = new ObFieldSchema("c3", DataType.JSON);
|
||||
c3_field.IsNullable(true);
|
||||
collectionSchema.addField(c1_field);
|
||||
collectionSchema.addField(c2_field);
|
||||
collectionSchema.addField(c3_field);
|
||||
|
||||
# Define the index.
|
||||
IndexParams index_params = new IndexParams();
|
||||
IndexParam index_param = new IndexParam("vidx1", "c2");
|
||||
index_params.addIndex(index_param);
|
||||
collectionSchema.setIndexParams(index_params);
|
||||
|
||||
ob.createCollection(tb_name, collectionSchema);
|
||||
```
|
||||
|
||||
#### Create a vector index after table creation
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the table.
|
||||
# index_param: an IndexParam object that specifies the vector index parameters of the table.
|
||||
public void createIndex(String table_name, IndexParam index_param)
|
||||
```
|
||||
|
||||
#### Insert data
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# column_names: an array of column names in the target table.
|
||||
# rows: the data rows. ArrayList<Sqlizable[]>, each row is an Sqlizable array. Sqlizable is a wrapper class that converts Java data types to SQL data types.
|
||||
public void insert(String table_name, String[] column_names, ArrayList<Sqlizable[]> rows);
|
||||
```
|
||||
|
||||
The supported data types for rows include:
|
||||
|
||||
* SqlInteger: wraps integer data.
|
||||
* SqlFloat: wraps floating-point data.
|
||||
* SqlDouble: wraps double-precision data.
|
||||
* SqlText: wraps string data.
|
||||
* SqlVector: wraps vector data.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.SqlInteger;
|
||||
import com.oceanbase.obvec_jdbc.SqlText;
|
||||
import com.oceanbase.obvec_jdbc.SqlVector;
|
||||
import com.oceanbase.obvec_jdbc.Sqlizable;
|
||||
|
||||
ArrayList<Sqlizable[]> insert_rows = new ArrayList<>();
|
||||
Sqlizable[] ir1 = { new SqlVector(new float[] {1.0f, 2.0f, 3.0f}), new SqlText("{\"doc\": \"oceanbase doc 1\"}") };
|
||||
insert_rows.add(ir1);
|
||||
Sqlizable[] ir2 = { new SqlVector(new float[] {1.1f, 2.2f, 3.3f}), new SqlText("{\"doc\": \"oceanbase doc 2\"}") };
|
||||
insert_rows.add(ir2);
|
||||
Sqlizable[] ir3 = { new SqlVector(new float[] {0f, 0f, 0f}), new SqlText("{\"doc\": \"oceanbase doc 3\"}") };
|
||||
insert_rows.add(ir3);
|
||||
ob.insert(tb_name, new String[] {"c2", "c3"}, insert_rows);
|
||||
```
|
||||
|
||||
#### Delete data
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# primary_key_name: the name of the primary key column.
|
||||
# primary_keys: an array of primary key column values for the target rows.
|
||||
public void delete(String table_name, String primary_key_name, ArrayList<Sqlizable> primary_keys);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
ArrayList<Sqlizable> ids = new ArrayList<>();
|
||||
ids.add(new SqlInteger(2));
|
||||
ids.add(new SqlInteger(1));
|
||||
ob.delete(tb_name, "c1", ids);
|
||||
```
|
||||
|
||||
#### ANN queries
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# vec_col_name: the name of the vector column.
|
||||
# metric_type: the type of the vector distance function. l2: corresponds to the L2 distance function. cosine: corresponds to the cosine distance function. ip: corresponds to the negative inner product distance function.
|
||||
# qv: the vector value to be queried.
|
||||
# topk: the number of the most similar results to be returned.
|
||||
# output_fields: the projected columns, that is, the array of the fields to be returned.
|
||||
# output_datatypes: the data types of the projected columns, that is, the data types of the fields to be returned, for direct conversion to Java data types.
|
||||
# where_expr: the WHERE condition expression.
|
||||
public ArrayList<HashMap<String, Sqlizable>> query(
|
||||
String table_name,
|
||||
String vec_col_name,
|
||||
String metric_type,
|
||||
float[] qv,
|
||||
int topk,
|
||||
String[] output_fields,
|
||||
DataType[] output_datatypes,
|
||||
String where_expr);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
ArrayList<HashMap<String, Sqlizable>> res = ob.query(tb_name, "c2", "l2",
|
||||
new float[] {0f, 0f, 0f}, 10,
|
||||
new String[] {"c1", "c3", "c2"},
|
||||
new DataType[] {
|
||||
DataType.INT32,
|
||||
DataType.JSON,
|
||||
DataType.FLOAT_VECTOR,
|
||||
"c1 > 0"});
|
||||
if (res != null) {
|
||||
for (int i = 0; i < res.size(); i++) {
|
||||
for (HashMap.Entry<String, Sqlizable> entry : res.get(i).entrySet()) {
|
||||
System.out.printf("%s : %s, ", entry.getKey(), entry.getValue().toString());
|
||||
}
|
||||
System.out.print("\n");
|
||||
}
|
||||
} else {
|
||||
System.out.println("res is null");
|
||||
}
|
||||
```
|
||||
|
||||
### Use the JSON table feature
|
||||
|
||||
The JSON table feature of obvec_jdbc relies on seekdb's ability to handle JSON data types (including `JSON_VALUE`/`JSON_TABLE`/`JSON_REPLACE`, etc.) to implement a virtual table mechanism. Multiple users (distinguished by user ID) can perform DDL or DML operations on virtual tables over the same physical table while ensuring data isolation between users. Admin users can perform DDL operations, while regular users can perform DML operations.
|
||||
|
||||
This design combines the structured management capabilities of relational databases with the flexibility of JSON, showcasing seekdb's multi-model integration capabilities. Users can enjoy the power and ease of use of SQL while also handling semi-structured data, meeting the diverse data model requirements of modern applications. Although operations are still performed on "tables," data is stored in a more flexible JSON format at the underlying level, better supporting complex and varied application scenarios.
|
||||
|
||||
#### How it works
|
||||
|
||||
<!-- The following figure illustrates the principle of JSON Table.
|
||||
|
||||
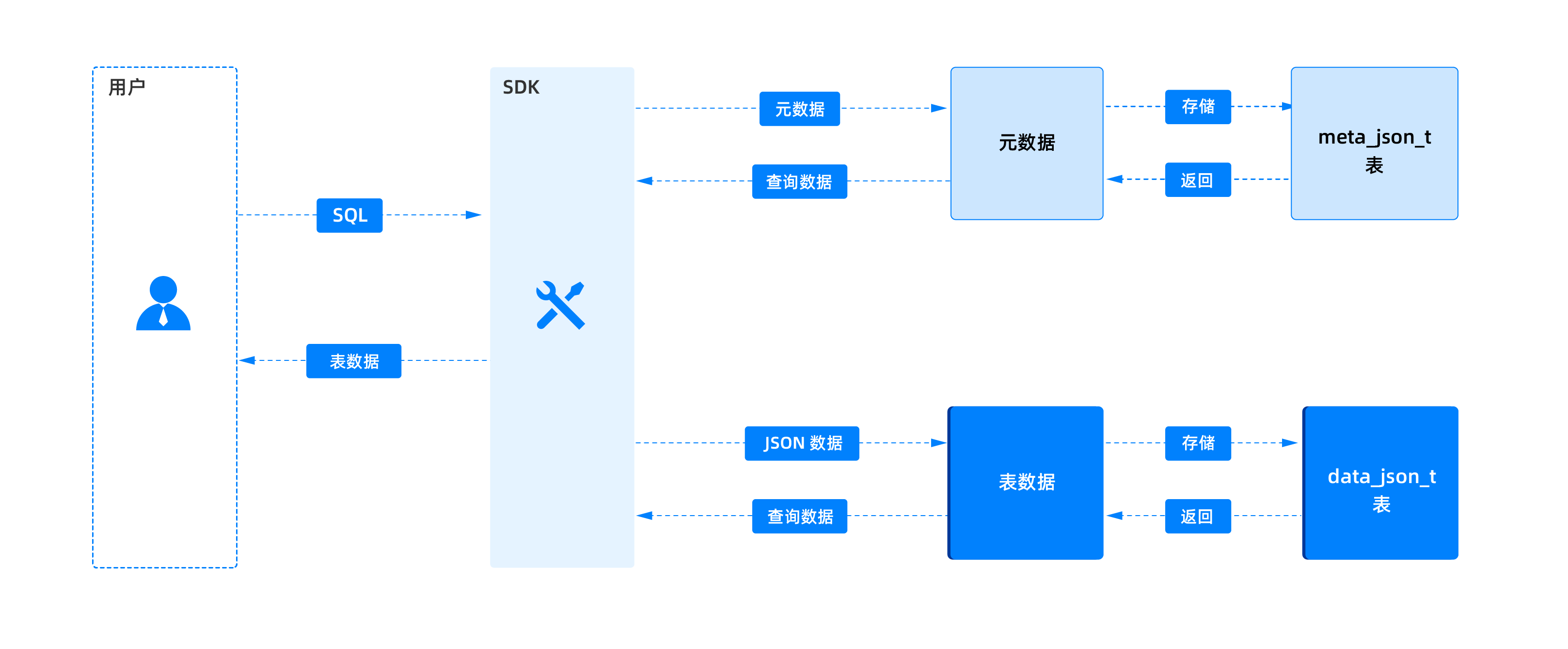
|
||||
|
||||
Detailed explanation:-->
|
||||
|
||||
1. User operations: Users still interact with the system using familiar standard SQL statements (such as `CREATE TABLE` to create table structures, `INSERT` to insert data, and `SELECT` to query data). They do not need to worry about how data is stored at the underlying level, just like operating ordinary relational database tables. The tables created by users using SQL statements are logical tables, which correspond to two physical tables (`meta_json_t` and `data_json_t`) within seekdb.
|
||||
|
||||
2. JSON Table SDK: Within the application, there is a JSON Table SDK (Software Development Kit). This SDK is the key that connects users' SQL operations and seekdb's actual storage. When SQL statements are executed, the SDK intercepts these requests and intelligently converts them into read and write operations on seekdb's internal tables `meta_json_t` and `data_json_t`.
|
||||
|
||||
3. seekdb internal storage:
|
||||
|
||||
* `meta_json_t` (stores table schema): stores the metadata of the logical tables created by users, which is the schema information of the table (for example, which columns are created and what data type each column is). When `CREATE TABLE` is executed, the SDK records this schema information in `meta_json_t`.
|
||||
* `data_json_t` (stores row data as JSON type): stores the actual inserted data. Unlike traditional relational databases that directly store row data, the JSON Table feature encapsulates each row of inserted data into a JSON object and stores it in a column of the `data_json_t` table. This allows for efficient storage even with flexible data structures.
|
||||
|
||||
4. Data query: When query operations such as `SELECT` are executed, the SDK reads JSON-format data from `data_json_t` and combines it with the schema information from `meta_json_t` to re-parse and present the JSON data in a familiar tabular format, returning it to your application.
|
||||
|
||||
The `meta_json_t` table stores the metadata of the JSON table, which is the logical table schema defined by the user using the `CREATE TABLE` statement. It records the column information of each logical table, with the following schema:
|
||||
|
||||
| Field | Description | Example |
|
||||
|--------|------|------|
|
||||
| `user_id` | The user ID, used to distinguish the logical tables of different users. | `0`, `1`, `2` |
|
||||
| `jtable_name` | The name of the logical table. | `test_count` |
|
||||
| `jcol_id` | The column ID of the logical table. | `1`, `2`, `3` |
|
||||
| `jcol_name` | The column name of the logical table. | `c1`, `c2`, `c3` |
|
||||
| `jcol_type` | The data type of the column. | `INT`, `VARCHAR(124)`, `DECIMAL(10,2)` |
|
||||
| `jcol_nullable` | Indicates whether the column allows null values. | `0`, `1` |
|
||||
| `jcol_has_default` | Indicates whether the column has a default value. | `0`, `1` |
|
||||
| `jcol_default` | The default value of the column. | `{'default': null}` |
|
||||
|
||||
When a user executes the `CREATE TABLE` statement, the JSON table SDK parses and inserts the column definition information into the `meta_json_t` table.
|
||||
|
||||
The `data_json_t` table stores the actual data of the JSON table, which is the data inserted by the user using the `INSERT` statement. It records the row data of each logical table, with the following schema:
|
||||
|
||||
| Field | Description | Example |
|
||||
|--------|------|------|
|
||||
| `user_id` | The user ID, used to distinguish the logical tables of different users. | `0`, `1`, `2` |
|
||||
| `admin_id` | The administrator user ID. | `0` |
|
||||
| `jtable_name` | The name of the logical table, used to associate the metadata in `meta_json_t`. | `test_count` |
|
||||
| `jdata_id` | The data ID, a unique identifier for the JSON data, corresponding to each row in the logical table. | `1`, `2`, `3` |
|
||||
| `jdata` | A column of the JSON type, used to store the actual row data of the logical table. | `{"c1": 1, "c2": "test", "c3": 1.23}` |
|
||||
|
||||
#### Examples
|
||||
|
||||
1. Create a client
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# uri: the connection string, which contains the address, port, and name of the database to which you want to connect.
|
||||
# user: the username.
|
||||
# password: the password.
|
||||
# user_id: the user ID.
|
||||
# log_level: the log level.
|
||||
public ObVecJsonClient(String uri, String user, String password, String user_id, Level log_level);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.ObVecJsonClient;
|
||||
|
||||
String uri = "jdbc:oceanbase://127.0.0.1:2881/test";
|
||||
String user = "root@test";
|
||||
String password = "";
|
||||
ObVecJsonClient client = new ObVecJsonClient(uri, user, password, 0, Level.INFO);
|
||||
```
|
||||
|
||||
2. Execute DDL statements
|
||||
|
||||
You can directly call the `parseJsonTableSQL2NormalSQL` interface and pass in the specific SQL statements.
|
||||
|
||||
* Create a table
|
||||
|
||||
```java
|
||||
String sql = "CREATE TABLE `t2` (c1 INT NOT NULL DEFAULT 10, c2 VARCHAR(30) DEFAULT 'ca', c3 VARCHAR NOT NULL, c4 DECIMAL(10, 2), c5 TIMESTAMP DEFAULT CURRENT_TIMESTAMP);";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE CHANGE COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 CHANGE COLUMN c2 changed_col INT";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE ADD COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 ADD COLUMN email VARCHAR(100) default 'example@example.com'";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE MODIFY COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 MODIFY COLUMN changed_col TIMESTAMP NOT NULL DEFAULT current_timestamp";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE DROP COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 DROP c1";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE RENAME
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 RENAME TO alter_test";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
Reference in New Issue
Block a user