Initial commit
This commit is contained in:
@@ -0,0 +1,84 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-intro
|
||||
---
|
||||
|
||||
# Overview of vector search
|
||||
|
||||
This topic introduces the core concepts of vector databases and vector search.
|
||||
|
||||
seekdb supports dense float vectors with up to 16,000 dimensions, as well as sparse vectors. It supports various types of vector distance calculations, including Manhattan distance, Euclidean distance, inner product, and cosine distance. seekdb also supports the creation of HNSW/IVF-based vector indexes, as well as incremental updates and deletions, with these operations having no impact on recall rate.
|
||||
|
||||
seekdb vector search offers hybrid retrieval capabilities with scalar filtering. It also provides flexible access interfaces: you can use SQL via the MySQL protocol from clients in various programming languages, or access it using a Python SDK. In addition, seekdb is fully adapted to AI application development frameworks such as LlamaIndex, DB-GPT, and the AI application development platform Dify, offering better support for AI application development.
|
||||
|
||||
<video data-code="9002093" src="https://obbusiness-private.oss-cn-shanghai.aliyuncs.com/doc/video/03%20OceanBase%20Vector%20Search-An%20Official%20In-depth%20Perspective.mp4" controls width="811px" height="456.188px"></video>
|
||||
|
||||
## Key concepts
|
||||
|
||||
### Unstructured data
|
||||
|
||||
Unstructured data is data that does not have a predefined data format or organizational structure. It typically includes data in forms such as text, images, audio, and video, as well as social media content, emails, and log files. Due to the complexity and diversity of unstructured data, processing it requires specific tools and techniques, such as natural language processing, image recognition, and machine learning.
|
||||
|
||||
### Vector
|
||||
|
||||
A vector is the projection of an object in a high-dimensional space. Mathematically, a vector is a floating-point array with the following characteristics:
|
||||
|
||||
* Each element in the array is a floating-point number that represents a dimension of the vector.
|
||||
|
||||
* The size, namely, the number of elements, of the vector array indicates the dimensionality of the entire vector space.
|
||||
|
||||
### Vector embedding
|
||||
|
||||
Vector embedding is the process of using a deep learning neural network to extract content and semantics from unstructured data such as images and videos, and convert them into feature vectors. Embedding technology maps original data from a high-dimensional space to a low-dimensional space and converts multimodal data with rich features into multi-dimensional vector data.
|
||||
|
||||
### Vector similarity search
|
||||
|
||||
In today's era of information explosion, users often need to quickly retrieve specific information from massive datasets. Whether it's online literature databases, e-commerce product catalogs, or rapidly growing multimedia content libraries, efficient retrieval systems are essential for locating content of interest. As data volumes continue to grow, traditional keyword-based search methods can no longer meet the demands for both accuracy and speed, giving rise to vector search technology. Vector similarity search uses feature extraction and vectorization techniques to convert unstructured data—such as text, images, and audio—into vectors. By applying similarity measurement methods to compare these vectors, it captures the deeper semantic meaning of the data. This approach delivers more precise and efficient search results, addressing the shortcomings of traditional search methods.
|
||||
|
||||
## Why seekdb vector search?
|
||||
|
||||
seekdb's vector search capabilities are built on its integrated multi-model capabilities, excelling in areas such as hybrid retrieval, high performance, high availability, cost efficiency, and data security.
|
||||
|
||||
### Hybrid retrieval
|
||||
|
||||
seekdb supports hybrid retrieval across multiple data types, including vector data, spatial data, document data, and scalar data. With support for various indexes such as vector indexes, spatial indexes, and full-text indexes, seekdb delivers exceptional performance in multi-model hybrid retrieval. It enables a single database to handle diverse storage and retrieval needs for applications.
|
||||
|
||||
### Scalability
|
||||
|
||||
seekdb vector search supports the storage and retrieval of massive amounts of vector data, meeting the requirements of large-scale vector data applications.
|
||||
|
||||
### High performance
|
||||
|
||||
seekdb vector search capabilities integrate the VSAG indexing algorithm library, which demonstrates outstanding performance on the 960-dimensional GIST dataset. In the ANN-Benchmarks tests, the VSAG library significantly outperformed other algorithms.
|
||||
|
||||
### High availability
|
||||
|
||||
seekdb vector search provides reliable data storage and access capabilities. For in-memory HNSW indexes, it ensures stable retrieval performance.
|
||||
|
||||
### Transactions
|
||||
|
||||
seekdb's transaction capabilities ensure the consistency and integrity of vector data. It also offers effective concurrency control and fault recovery mechanisms.
|
||||
|
||||
### Cost efficiency
|
||||
|
||||
seekdb's storage encoding and compression capabilities significantly reduce the storage space required for vectors, helping to lower application storage costs.
|
||||
|
||||
### Data security
|
||||
|
||||
seekdb already supports comprehensive enterprise-grade security features, including identity authentication and verification, access control, data encryption, monitoring and alerts, and security auditing. These features effectively ensure data security in vector search scenarios.
|
||||
|
||||
### Ease of use
|
||||
|
||||
seekdb vector search provides flexible access interfaces, enabling SQL access through MySQL protocol clients across various programming languages, as well as seamless integration via a Python SDK. Furthermore, seekdb has been optimized for AI application development frameworks like LangChain and LlamaIndex, offering better support for AI application development.
|
||||
|
||||
### Comprehensive toolset
|
||||
|
||||
seekdb features a comprehensive database toolset, supporting data development, migration, operations, diagnostics, and full lifecycle data management, safeguarding the development and maintenance of AI applications.
|
||||
|
||||
## Application scenarios
|
||||
|
||||
* Retrieval-Augmented Generation (RAG): RAG is an artificial intelligence (AI) framework that retrieves facts from external knowledge bases to provide the most accurate and latest information for Large Language Models (LLMs) and allow users to have an insight into the generation process of an LLM. RAG is commonly used in intelligent Q&A systems and knowledge bases.
|
||||
|
||||
* Personalized recommendation: The recommendation system can recommend items that users may be interested in based on their historical behavior and preferences. When a recommendation request is initiated, the system will calculate the similarity based on the characteristics of the user, and then return items that the user may be interested in as the recommendation results, such as recommended restaurants and scenic spots.
|
||||
|
||||
* Image search/Text search: An image/text search task aims to find results that are most similar to the specified image in a large-scale image/text database. The text/image features used in the search can be stored in a vector database, and efficient similarity calculation can be achieved based on high-performance index-based storage, thereby returning image/text results that match the search criteria. This applies to scenarios such as facial recognition.
|
||||
@@ -0,0 +1,28 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-workflow
|
||||
---
|
||||
|
||||
# AI application workflow using seekdb vector search
|
||||
|
||||
This topic describes the AI application workflow using seekdb vector search.
|
||||
|
||||
## Convert unstructured data into feature vectors through vector embedding
|
||||
|
||||
Unstructured data (such as videos, documents, and images) is the starting point of the entire workflow. Various forms of unstructured data, including videos, text files (documents), and images, are transformed into vector representations through vector embedding models. The task of these models is to convert raw, unstructured data that is difficult to directly calculate similarity into high-dimensional vector data. These vectors capture the semantic information and features of the data, and can express the similarity of data through distances in the vector space. For more information, see [Vector embedding technology](../150.vector-embedding-technology.md).
|
||||
|
||||
## Store vector embeddings and create vector indexes in seekdb
|
||||
|
||||
As the core storage layer, seekdb is responsible for storing all data. This includes traditional relational tables (used for storing business data), the original unstructured data, and the vector data generated after vector embedding. For more information, see [Store vector data](../160.store-vector-data.md).
|
||||
|
||||
To enable efficient vector search, seekdb internally builds vector indexes for the vector data. Vector indexes are specialized data structures that significantly accelerate nearest neighbor searches in high-dimensional vector spaces. Since calculating vector similarity is computationally expensive, exact searches (calculating distances for all vectors one by one) ensure accuracy but can severely impact query performance. Through vector indexes, the system can quickly locate candidate vectors, significantly reducing the number of vectors that need distance calculations, thereby improving query efficiency while maintaining high accuracy. For more information, see [Create vector indexes](../200.vector-index/200.dense-vector-index.md).
|
||||
|
||||
## Perform nearest neighbor search and hybrid search through SQL/SDK
|
||||
|
||||
Users interact with the AI application through clients or programming languages by submitting queries that may involve text, images, or other formats. For more information, see [Supported clients and languages](../700.vector-search-reference/900.vector-search-supported-clients-and-languages/100.vector-search-supported-clients-and-languages-overview.md).
|
||||
|
||||
seekdb uses SQL statements to query and manage relational data, enabling hybrid searches that combine scalar and vector data. When a user initiates a query—if it is unstructured—the system first converts it into a vector using the embedding model. Then, leveraging both vector and scalar indexes, the system quickly retrieves the most similar vectors that also meet scalar filter conditions, thus identifying the most relevant unstructured data. For detailed information about nearest neighbor search, see [Nearest neighbor search](../300.vector-similarity-search.md).
|
||||
|
||||
## Generate prompts and send them to the LLM for inference
|
||||
|
||||
In the final stage, an optimized prompt is generated based on the hybrid search results and sent to the large language model (LLM) to complete the inference process. The LLM generates a natural language response based on this contextual information. There is a feedback loop between the LLM and the vector embedding model, meaning that the output of the LLM or user feedback can be used to optimize the embedding model, creating a cycle of continuous learning and improvement.
|
||||
@@ -0,0 +1,339 @@
|
||||
---
|
||||
|
||||
slug: /vector-embedding-technology
|
||||
---
|
||||
|
||||
# Vector embedding technology
|
||||
|
||||
This topic introduces vector embedding technology in vector retrieval.
|
||||
|
||||
## What is vector embedding?
|
||||
|
||||
Vector embedding is a technique for converting unstructured data into numerical vectors. These vectors can capture the semantic information of unstructured data, enabling computers to "understand" and process the meaning of such data. Specifically:
|
||||
|
||||
* Vector embedding maps unstructured data such as text, images, or audio/video to points in a high-dimensional vector space.
|
||||
|
||||
* In this vector space, semantically similar unstructured data is mapped to nearby locations.
|
||||
|
||||
* Vectors are typically composed of hundreds of numbers (such as 512 or 1024 dimensions).
|
||||
|
||||
* Mathematical methods (such as cosine similarity) can be used to calculate the similarity between vectors.
|
||||
|
||||
* Common vector embedding models include Word2Vec, BERT, and BGE. For example, when developing RAG applications, text data is often embedded into vector data and stored in a vector database, while other structured data is stored in a relational database.
|
||||
|
||||
In seekdb, vector data can be stored as a data type in a relational table, allowing vectors and traditional scalar data to be stored in an orderly and efficient manner within seekdb.
|
||||
|
||||
## Generate vector embeddings using AI function service in seekdb
|
||||
|
||||
In seekdb, you can use the AI function service to generate vector embeddings. Users do not need to install any dependencies. After registering the model information, you can use the AI function service to generate vector embeddings in seekdb. For details, see [AI function service usage and examples](../300.ai-function/200.ai-function.md).
|
||||
|
||||
## Common text embedding methods
|
||||
|
||||
This section introduces common text embedding methods.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
You need to have the `pip` command installed in advance.
|
||||
|
||||
### Use an offline, locally pre-trained embedding model
|
||||
|
||||
Using pre-trained models for local text embedding is the most flexible approach, but it requires significant computing resources. Commonly used models include:
|
||||
|
||||
#### Use Sentence Transformers
|
||||
|
||||
Sentence Transformers is an NLP model designed to convert sentences or paragraphs into vector embeddings. It uses deep learning technology, particularly the Transformer architecture, to effectively capture the semantic information of text. Since direct access to Hugging Face's domain often times out in China, please set the Hugging Face mirror address `export HF_ENDPOINT=https://hf-mirror.com` in advance. After setting it, run the code below:
|
||||
|
||||
```shell
|
||||
from sentence_transformers import SentenceTransformer
|
||||
|
||||
model = SentenceTransformer("BAAI/bge-m3")
|
||||
|
||||
sentences = [
|
||||
"That is a happy person",
|
||||
"That is a happy dog",
|
||||
"That is a very happy person",
|
||||
"Today is a sunny day"
|
||||
]
|
||||
embeddings = model.encode(sentences)
|
||||
print(embeddings)
|
||||
# [[-0.01178016 0.00884024 -0.05844684 ... 0.00750248 -0.04790139
|
||||
# 0.00330675]
|
||||
# [-0.03470375 -0.00886354 -0.05242309 ... 0.00899352 -0.02396279
|
||||
# 0.02985837]
|
||||
# [-0.01356584 0.01900942 -0.05800966 ... 0.00523864 -0.05689549
|
||||
# 0.00077098]
|
||||
# [-0.02149693 0.02998871 -0.05638731 ... 0.01443702 -0.02131325
|
||||
# -0.00112451]]
|
||||
similarities = model.similarity(embeddings, embeddings)
|
||||
print(similarities.shape)
|
||||
# torch.Size([4, 4])
|
||||
```
|
||||
|
||||
#### Use Hugging Face Transformers
|
||||
|
||||
Hugging Face Transformers is an open-source library that provides a wide range of pre-trained deep learning models, especially for NLP tasks. Due to geographical reasons, direct access to Hugging Face's domain may time out. Please set the Hugging Face mirror address `export HF_ENDPOINT=https://hf-mirror.com` in advance. After setting it, run the code below:
|
||||
|
||||
```shell
|
||||
from transformers import AutoTokenizer, AutoModel
|
||||
import torch
|
||||
|
||||
# Load the model and tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-m3")
|
||||
model = AutoModel.from_pretrained("BAAI/bge-m3")
|
||||
|
||||
# Prepare the input
|
||||
texts = ["This is an example text."]
|
||||
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
|
||||
|
||||
# Generate embeddings
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs)
|
||||
embeddings = outputs.last_hidden_state[:, 0] # Use the [CLS] token's output
|
||||
print(embeddings)
|
||||
# tensor([[-1.4136, 0.7477, -0.9914, ..., 0.0937, -0.0362, -0.1650]])
|
||||
print(embeddings.shape)
|
||||
# torch.Size([1, 1024])
|
||||
```
|
||||
|
||||
#### Ollama
|
||||
|
||||
[Ollama](https://ollama.com) is an open-source model runtime that allows users to easily run, manage, and use various large language models locally. In addition to supporting open-source language models like Llama 3 and Mistral, it also supports embedding models like bge-m3.
|
||||
|
||||
1. Deploy Ollama
|
||||
|
||||
On MacOS and Windows, you can directly download and install the package from the official website. For installation instructions, refer to Ollama's official website. After installation, Ollama runs as a background service.
|
||||
|
||||
To install Ollama on Linux:
|
||||
|
||||
```shell
|
||||
curl -fsSL https://ollama.ai/install.sh | sh
|
||||
```
|
||||
|
||||
2. Pull an embedding model
|
||||
|
||||
Ollama supports using the bge-m3 model for text embeddings:
|
||||
|
||||
```shell
|
||||
ollama pull bge-m3
|
||||
```
|
||||
|
||||
3. Use Ollama for text embeddings
|
||||
|
||||
You can use Ollama's embedding capabilities through HTTP API or Python SDK:
|
||||
|
||||
* HTTP API
|
||||
|
||||
```shell
|
||||
import requests
|
||||
|
||||
def get_embedding(text: str) -> list:
|
||||
"""Get text embeddings using Ollama's HTTP API"""
|
||||
response = requests.post(
|
||||
'http://localhost:11434/api/embeddings',
|
||||
json={
|
||||
'model': 'bge-m3',
|
||||
'prompt': text
|
||||
}
|
||||
)
|
||||
return response.json()['embedding']
|
||||
|
||||
# Example usage
|
||||
text = "This is an example text."
|
||||
embedding = get_embedding(text)
|
||||
print(embedding)
|
||||
# [-1.4269912242889404, 0.9092104434967041, ...]
|
||||
```
|
||||
|
||||
* Python SDK
|
||||
|
||||
First, install Ollama's Python SDK:
|
||||
|
||||
```shell
|
||||
pip install ollama
|
||||
```
|
||||
|
||||
Then you can use it like this:
|
||||
|
||||
```shell
|
||||
import ollama
|
||||
|
||||
# Example usage
|
||||
texts = ["First sentence", "Second sentence"]
|
||||
embeddings = ollama.embed(model="bge-m3", input=texts)['embeddings']
|
||||
print(embeddings)
|
||||
# [[0.03486196, 0.0625187, ...], [...]]
|
||||
```
|
||||
|
||||
4. Advantages and limitations of Ollama
|
||||
|
||||
Advantages:
|
||||
|
||||
* Fully local deployment, no internet connection required
|
||||
* Open-source and free, no API Key required
|
||||
* Supports multiple models, easy to switch and compare
|
||||
* Relatively low resource usage
|
||||
|
||||
Limitations:
|
||||
|
||||
* Limited selection of embedding models
|
||||
* Performance may not match commercial services
|
||||
* Requires self-maintenance and updates
|
||||
* Lacks enterprise-level support
|
||||
|
||||
When choosing whether to use Ollama, you need to weigh these factors. If your application scenario has high privacy requirements, or you want to run completely offline, Ollama is a good choice. However, if you need more stable service quality and better performance, you may need to consider commercial services.
|
||||
|
||||
<!-- ### Use online, remote embedding services
|
||||
|
||||
Using offline, local embedding models usually requires high hardware specifications for the deployment machine and also demands advanced management of processes such as model loading and unloading. As a result, many users have a strong need for online embedding services. Currently, many AI inference service providers offer corresponding text embedding services. Taking Tongyi Qwen's text embedding service as an example, you can first register for an account with [Alibaba Cloud Model Studio](https://bailian.console.aliyun.com) and obtain an API Key. Then, you can call its public API to get text embeddings.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
-->
|
||||
|
||||
#### HTTP call
|
||||
|
||||
After obtaining the credentials, you can try performing text embedding with the following code. If the requests package is not installed in your Python environment, you need to install it first with `pip install requests` to enable sending network requests.
|
||||
|
||||
```shell
|
||||
import requests
|
||||
from typing import List
|
||||
|
||||
class RemoteEmbedding():
|
||||
def __init__(
|
||||
self,
|
||||
base_url: str,
|
||||
api_key: str,
|
||||
model: str,
|
||||
dimensions: int = 1024,
|
||||
**kwargs,
|
||||
):
|
||||
self._base_url = base_url
|
||||
self._api_key = api_key
|
||||
self._model = model
|
||||
self._dimensions = dimensions
|
||||
|
||||
"""
|
||||
OpenAI compatible embedding API. Tongyi, Baichuan, Doubao, etc.
|
||||
"""
|
||||
|
||||
def embed_documents(
|
||||
self,
|
||||
texts: List[str],
|
||||
) -> List[List[float]]:
|
||||
"""Embed search docs.
|
||||
|
||||
Args:
|
||||
texts: List of text to embed.
|
||||
|
||||
Returns:
|
||||
List of embeddings.
|
||||
"""
|
||||
res = requests.post(
|
||||
f"{self._base_url}",
|
||||
headers={"Authorization": f"Bearer {self._api_key}"},
|
||||
json={
|
||||
"input": texts,
|
||||
"model": self._model,
|
||||
"encoding_format": "float",
|
||||
"dimensions": self._dimensions,
|
||||
},
|
||||
)
|
||||
data = res.json()
|
||||
embeddings = []
|
||||
try:
|
||||
for d in data["data"]:
|
||||
embeddings.append(d["embedding"][: self._dimensions])
|
||||
return embeddings
|
||||
except Exception as e:
|
||||
print(data)
|
||||
print("Error", e)
|
||||
raise e
|
||||
|
||||
def embed_query(self, text: str, **kwargs) -> List[float]:
|
||||
"""Embed query text.
|
||||
|
||||
Args:
|
||||
text: Text to embed.
|
||||
|
||||
Returns:
|
||||
Embedding.
|
||||
"""
|
||||
return self.embed_documents([text])[0]
|
||||
|
||||
embedding = RemoteEmbedding(
|
||||
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
|
||||
api_key="your-api-key", # Enter your API Key
|
||||
model="text-embedding-v3",
|
||||
)
|
||||
|
||||
print("Embedding result:", embedding.embed_query("The weather is nice today"), "\n")
|
||||
# Embedding result: [-0.03573227673768997, 0.0645645260810852, ...]
|
||||
print("Embedding results:", embedding.embed_documents(["The weather is nice today", "What about tomorrow?"]), "\n")
|
||||
# Embedding results: [[-0.03573227673768997, 0.0645645260810852, ...], [-0.05443647876381874, 0.07368793338537216, ...]]
|
||||
```
|
||||
|
||||
#### Use Qwen SDK
|
||||
|
||||
Qwen provides an SDK called dashscope for quickly accessing model capabilities. After installing it using `pip install dashscope`, you can obtain text embeddings.
|
||||
|
||||
```shell
|
||||
import dashscope
|
||||
from dashscope import TextEmbedding
|
||||
|
||||
# Set the API Key
|
||||
dashscope.api_key = "your-api-key"
|
||||
|
||||
# Prepare the input text
|
||||
texts = ["This is the first sentence", "This is the second sentence"]
|
||||
|
||||
# Call the embedding service
|
||||
response = TextEmbedding.call(
|
||||
model="text-embedding-v3",
|
||||
input=texts
|
||||
)
|
||||
|
||||
# Get the embedding results
|
||||
if response.status_code == 200:
|
||||
print(response.output['embeddings'])
|
||||
# [{"embedding": [-0.03193652629852295, 0.08152323216199875, ...]}, {"embedding": [...]}]
|
||||
```
|
||||
|
||||
## Common image embedding methods
|
||||
|
||||
This section introduces image embedding methods.
|
||||
|
||||
### Use an offline, locally pre-trained embedding model
|
||||
|
||||
#### Use CLIP
|
||||
|
||||
CLIP (Contrastive Language-Image Pretraining) is a model proposed by OpenAI for multimodal learning by combining images and text. CLIP can understand and process the relationships between images and text, making it perform well in various tasks such as image classification, image retrieval, and text generation.
|
||||
|
||||
```shell
|
||||
from PIL import Image
|
||||
from transformers import CLIPProcessor, CLIPModel
|
||||
|
||||
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
|
||||
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
||||
|
||||
# Prepare the input image
|
||||
image = Image.open("path_to_your_image.jpg")
|
||||
texts = ["This is the first sentence", "This is the second sentence"]
|
||||
|
||||
# Call the embedding service
|
||||
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
|
||||
outputs = model(**inputs)
|
||||
|
||||
# Obtain the embedding results
|
||||
if outputs.status_code == 200:
|
||||
print(outputs.output['embeddings'])
|
||||
# [{"embedding": [-0.03193652629852295, 0.08152323216199875, ...]}, {"embedding": [...]}]
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Store vector embeddings](160.store-vector-data.md)
|
||||
* [Vector data types](700.vector-search-reference/100.vector-data-type.md)
|
||||
@@ -0,0 +1,50 @@
|
||||
---
|
||||
|
||||
slug: /store-vector-data
|
||||
---
|
||||
|
||||
# Store vector data
|
||||
|
||||
This topic introduces how to store unstructured, semi-structured, and structured data in a unified way within seekdb. This not only fully leverages the foundational capabilities of seekdb, but also provides strong support for hybrid search.
|
||||
|
||||
## How it works
|
||||
|
||||
seekdb can store data of different modalities and supports hybrid search by converting various types of data (such as text, images, and videos) into vectors. Searches are performed by calculating the distances between these vectors. Hybrid search can be divided into two types: simple search, which is based on similarity search for a single vector, and complex search, which involves combining vector and scalar searches.
|
||||
|
||||
Since vector search is inherently approximate, it is necessary to employ multiple techniques in practical applications to improve accuracy. Only precise search results can deliver greater value to your business.
|
||||
|
||||
## Create a vector column
|
||||
|
||||
The following example shows a table that stores vector data, spatial data, and relational data. The data type of the vector column is `VECTOR`, and the dimension must be specified when the column is created. The maximum supported dimension is 16,000. The data type of the spatial column is `GEOMETRY`:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t (
|
||||
-- Store relational data (structured data).
|
||||
id INT PRIMARY KEY,
|
||||
-- Store spatial data (semi-structured data).
|
||||
g GEOMETRY,
|
||||
-- Store vector data (unstructured data).
|
||||
vec VECTOR(3)
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
## Use the `INSERT` statement to insert vector data
|
||||
|
||||
Once you create a table that contains a column of the `VECTOR` data type, you can directly use the `INSERT` statement to insert vectors into the table. When you insert data, the vector must match the dimension specified when the table is created. Otherwise, an error will be returned. This design ensures data consistency and query efficiency. Vectors are represented in standard floating-point number arrays. Each dimension must have a valid floating-point number. Here is a simple example:
|
||||
|
||||
```sql
|
||||
INSERT INTO t (id, g, vec) VALUES (
|
||||
-- Insert structured data.
|
||||
1,
|
||||
-- Insert semi-structured data.
|
||||
ST_GeomFromText('POINT(1 1)'),
|
||||
-- Insert unstructured data.
|
||||
'[0.1, 0.2, 0.3]'
|
||||
);
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Vector embedding technology](150.vector-embedding-technology.md)
|
||||
* [Create vector indexes](200.vector-index/200.dense-vector-index.md)
|
||||
@@ -0,0 +1,600 @@
|
||||
---
|
||||
|
||||
slug: /dense-vector-index
|
||||
---
|
||||
|
||||
# Dense vector index
|
||||
|
||||
This topic describes how to create, query, maintain, and drop a dense vector index in seekdb.
|
||||
|
||||
## Index types
|
||||
|
||||
The following table describes the vector index types supported by seekdb.
|
||||
|
||||
| Index type | Description | Scenarios |
|
||||
|-----------|------|----------|
|
||||
| HNSW | The maximum dimension of indexed columns is 4096. The HNSW index is a memory-based index that must be fully loaded into memory. It supports DML and real-time queries. | |
|
||||
| HNSW_SQ | The HNSW_SQ index offers similar construction speed, query performance, and recall rate as the HNSW index, but reduces overall memory usage to 1/2 to 1/3 of the original. | Scenarios with high performance and recall rate requirements. |
|
||||
| HNSW_BQ | The HNSW_BQ index has a slightly lower recall rate compared to the HNSW index, but significantly reduces memory usage. The BQ quantization compression algorithm (Rabitq) can compress vectors to 1/32 of their original size. The memory optimization effect of the HNSW_BQ index becomes more pronounced as the vector dimension increases. | |
|
||||
| IVF| An IVF index implemented based on database tables, which does not require resident memory. | Scenarios with lower performance requirements but large data volumes and cost sensitivity. |
|
||||
| IVF_PQ| An IVF_PQ index implemented based on database tables, which does not require resident memory. On top of IVF, PQ quantization technology is applied. The recall rate of the index is slightly lower than that of the IVF index, but the performance is higher. The PQ quantization compression algorithm can generally compress vectors to 1/16 to 1/32 of their original size. | Scenarios with lower performance requirements but large data volumes and cost sensitivity. |
|
||||
| IVF_SQ (Experimental feature)| An IVF_SQ index implemented based on database tables, which does not require resident memory. On top of IVF, SQ quantization technology is applied. The recall rate of the index is slightly lower than that of the IVF index, but the performance is higher. The SQ quantization compression algorithm can generally compress vectors to 1/3 to 1/4 of their original size. | Scenarios with lower performance requirements but large data volumes and cost sensitivity. |
|
||||
|
||||
Some other notes:
|
||||
|
||||
* Dense vector indexes support L2, inner product (IP), and cosine distance as the index distance algorithm.
|
||||
* Vector index queries support calling some distance functions. For more information, see [Use SQL functions](../250.vector-function.md).
|
||||
* Vector queries with filter conditions are supported. The filter conditions can be scalar conditions or spatial relationships, such as ST_Intersects. Multi-value indexes, full-text indexes, and global indexes are not supported as pre-filterers.
|
||||
* You can create vector and full-text indexes on the same table.
|
||||
* For more information about how vector indexes support offline DDL operations, see [Offline DDL](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974221).
|
||||
|
||||
The limitations are described as follows:
|
||||
|
||||
* For V1.0.0, creating columnstore vector indexes is currently not supported.
|
||||
|
||||
## Index memory estimation and actual usage query
|
||||
|
||||
You can estimate the memory required for vector indexes using the `DBMS_VECTOR` system package:
|
||||
|
||||
* Before creating a table, you can estimate index memory requirements by using the [INDEX_VECTOR_MEMORY_ADVISOR](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754002) procedure.
|
||||
* After a table is created and data is inserted, you can estimate index memory requirements by using the [INDEX_VECTOR_MEMORY_ESTIMATE](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754001) procedure.
|
||||
|
||||
The vector index memory estimation provides two key pieces of information: the minimum memory configuration required to create a vector index, and the actual memory usage after creating HNSW_SQ and IVF indexes.
|
||||
|
||||
We also provide the configuration item `load_vector_index_on_follower` to control whether the follower role automatically loads in-memory vector indexes. For syntax and examples, see [load_vector_index_on_follower](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002969407). If weak reads are not needed, you can disable this configuration item to reduce the memory used by vector indexes.
|
||||
|
||||
## Creation syntax and description
|
||||
|
||||
seekdb vector indexes can be created during table creation or after the table is created. When creating a vector index, note the following:
|
||||
|
||||
* The `VECTOR` keyword is required when creating a vector index.
|
||||
* The parameters and descriptions for an index created after the table is created are the same as those for an index created during table creation.
|
||||
* If a large amount of data is involved, we recommend that you write the data first and then create the index to achieve the optimal query performance.
|
||||
* It is recommended to create HNSW_SQ, IVF, IVF_SQ, and IVF_PQ indexes after data is inserted, and to rebuild the indexes after a significant amount of new data is added. For detailed instructions on creating each index, see the specific examples below.
|
||||
|
||||
:::tab
|
||||
tab HNSW/HNSW_SQ/HNSW_BQ
|
||||
|
||||
Syntax for creating an index during table creation:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 data_type1,
|
||||
column_name2 data_type2,
|
||||
...,
|
||||
VECTOR INDEX index_name (column_name) WITH (param1=value1, param2=value2, ...)
|
||||
);
|
||||
```
|
||||
|
||||
Syntax for creating an index after table creation:
|
||||
|
||||
```sql
|
||||
-- Creating an index after table creation supports setting parallel degree to improve index construction performance. The maximum parallel degree should not exceed CPU cores * 2
|
||||
CREATE [/*+ paralell $value*/] VECTOR INDEX index_name ON table_name(column_name) WITH (param1=value1, param2=value2, ...);
|
||||
```
|
||||
|
||||
`param` parameter description:
|
||||
|
||||
| Parameter | Default value | Value range | Required | Description | Remarks |
|
||||
|------|--------|----------|----------|------|------|
|
||||
| distance | | l2/inner_product/cosine | Yes | The vector distance function type. | l2 indicates the Euclidean distance, inner_product indicates the inner product distance, and cosine indicates the cosine distance. |
|
||||
| type | | currently supported `hnsw` / `hnsw_sq`/ `hnsw_bq`. | Yes | The index type. | |
|
||||
| lib | vsag | vsag | No | The vector index library type. | At present, only the VSAG vector library is supported. |
|
||||
| m | 16 | [5,128] | No | The maximum number of neighbors of each node. | The larger the value, the slower the index construction, but the better the query performance. |
|
||||
| ef_construction | 200 | [5,1000] | No | The size of the candidate set during index construction. | The larger the value, the slower the index construction, but the better the index quality. `ef_construction` must be greater than `m`. |
|
||||
| ef_search | 64 | [1,1000] | No | The size of the candidate set during a query. | The larger the value, the slower the query, but the higher the recall rate. |
|
||||
| extra_info_max_size | 0 | [0,16384] | No | The maximum size of each primary key information (in bytes). Storing the primary key of the table in the index can speed up queries. | <code>0</code>: The primary key information is not stored.<br/><code>1</code>: The primary key information is forcibly stored, regardless of the size limit. In this case, the primary key type (see below) must be a supported type.<br/><code>Greater than 1</code>: The maximum size of the primary key information (in bytes) is specified. In this case, the following conditions must be met:<ul><li>The size of the primary key information (calculation method see below) must be less than the specified size limit.</li><li>The primary key type must be a supported type.</li><li>The table is not a table without a primary key.</li></ul> |
|
||||
| refine_k | 4.0 | [1.0,1000.0] | No | <main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an HNSW_BQ index. </p></main> This parameter is a floating-point number used to adjust the rearrangement ratio for quantized vector indexes. | This parameter can be specified when you create an index or during a query:<ul><li>If this parameter is not specified during a query, the value specified when the index is created is used. </li><li>If this parameter is specified during a query, the value specified during the query is used. </li></ul> |
|
||||
| refine_type | sq8 <main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an HNSW_BQ index. </p></main> This parameter specifies the construction precision of quantized vector indexes. | This parameter improves the efficiency of index construction by reducing the memory usage and the construction time, but may affect the recall rate. |
|
||||
| bq_bits_query | 32 | 0/4/32 | No | <main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an HNSW_BQ index. </p></main> This parameter specifies the query precision of quantized vector indexes in bits. | This parameter improves the efficiency of index construction by reducing the memory usage and the construction time, but may affect the recall rate. |
|
||||
| bq_use_fht | true <main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an HNSW_BQ index. </p></main> This parameter specifies whether to use FHT for queries. FHT (Fast Hadamard Transform) is an algorithm used to accelerate vector inner product calculations. | |
|
||||
|
||||
The supported primary key types for `extra_info_max_size` include:
|
||||
|
||||
* [Numeric types](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001975803): Integer types, floating-point types, and BIT_VALUE types.
|
||||
* [Datetime types](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001975805)
|
||||
* [Character types](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001975810): VARCHAR type is supported.
|
||||
|
||||
The calculation method for the primary key information size:
|
||||
|
||||
```sql
|
||||
SET @table_name = 'test'; -- Replace this with the table name to be queried.
|
||||
|
||||
SELECT
|
||||
CASE
|
||||
WHEN COUNT(*) <> COUNT(result_value) THEN 'not support'
|
||||
ELSE COALESCE(SUM(result_value), 'not support')
|
||||
END AS extra_info_size
|
||||
FROM (
|
||||
SELECT
|
||||
CASE
|
||||
WHEN vdt.data_type_class IN (1, 2, 3, 4, 6, 8, 9, 14, 27, 28) THEN 8 -- For numeric types, extra_info_size += 8
|
||||
WHEN oc.data_type = 22 THEN oc.data_length -- For varchar types, extra_info_size += data_length
|
||||
ELSE NULL -- Other types are not supported
|
||||
END AS result_value
|
||||
FROM
|
||||
oceanbase.__all_column oc
|
||||
JOIN
|
||||
oceanbase.__all_virtual_data_type vdt
|
||||
ON
|
||||
oc.data_type = vdt.data_type
|
||||
WHERE
|
||||
oc.rowkey_position != 0
|
||||
AND oc.table_id = (SELECT table_id FROM oceanbase.__all_table WHERE table_name = @table_name)
|
||||
) AS result_table;
|
||||
|
||||
-- The result is 8 bytes.
|
||||
```
|
||||
|
||||
tab IVF/IVF_SQ (Experimental feature)/IVF_PQ
|
||||
|
||||
Syntax for creating an index during table creation:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 data_type1,
|
||||
column_name2 data_type2,
|
||||
...,
|
||||
VECTOR INDEX index_name (column_name) WITH (param1=value1, param2=value2, ...)
|
||||
);
|
||||
```
|
||||
|
||||
Syntax for creating an index after table creation:
|
||||
|
||||
```sql
|
||||
-- Creating an index after table creation supports setting parallel degree to improve index construction performance. The maximum parallel degree should not exceed CPU cores * 2
|
||||
CREATE [/*+ paralell $value*/] VECTOR INDEX index_name ON table_name(column_name) WITH (param1=value1, param2=value2, ...);
|
||||
```
|
||||
|
||||
`param` parameter description:
|
||||
|
||||
| Parameter | Default value | Value range | Required? | Description | Remarks |
|
||||
|------|--------|----------|----------|------|------|
|
||||
| distance | | l2/inner_product/cosine | Yes | The vector distance function type. | l2 indicates the Euclidean distance, inner_product indicates the inner product distance, and cosine indicates the cosine distance. |
|
||||
| type | | ivf_flat/ivf_sq8/ivf_pq | Yes | The IVF index type. | |
|
||||
| lib | ob | ob | No | The vector index library type. | |
|
||||
| nlist | 128 | [1,65536] | No | The number of clusters. | |
|
||||
| sample_per_nlist | 256 | [1,int64_max] | Yes | The number of samples for each cluster center, which is used when creating an index after table creation. | |
|
||||
| nbits | 8 | [1,24] | No | The number of quantization bits.<main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an IVF_PQ index.</p></main> | The recommended value is 8. The recommended value range is [8,10]. The larger the value, the higher the quantization accuracy and query accuracy, but the query performance will be affected. |
|
||||
| m | No default value, must be specified | [1,65536] | Yes | The dimension of the quantized vectors.<main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an IVF_PQ index.</p></main> | The larger the value, the slower the index construction, and the higher the query accuracy, but the query performance will be affected. |
|
||||
|
||||
:::
|
||||
|
||||
## Query syntax and description
|
||||
|
||||
Vector index queries are approximate nearest neighbor queries and do not guarantee 100% accuracy. The accuracy of vector queries is measured by recall. For example, if a query for the 10 nearest neighbors can stably return 9 correct results, the recall is 90%. The recall is described as follows:
|
||||
|
||||
* The recall is affected by the build parameters and query parameters.
|
||||
* The index query parameters are specified when the index is created and cannot be modified. However, you can set session variables to specify the parameters. The `ob_hnsw_ef_search` variable specifies the parameters for the HNSW/HNSW_SQ/HNSW_BQ index, and the `ob_ivf_nprobes` variable specifies the parameters for the IVF index. If you set a session variable, its value is prioritized. For more information, see [ob_hnsw_ef_search](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001976680) and [ob_ivf_nprobes](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002179539).
|
||||
|
||||
The syntax for dense vector indexes is as follows:
|
||||
|
||||
```sql
|
||||
SELECT ... FROM $table_name ORDER BY $distance_function($column_name, $vector_expr) [APPROXIMATE|APPROX] LIMIT $num (OFFSET $num);
|
||||
```
|
||||
|
||||
Query usage notes are as follows:
|
||||
|
||||
* Syntax requirements:
|
||||
* The `APPROXIMATE`/`APPROX` keyword must be specified for the query to use the vector index instead of a full table scan.
|
||||
* The query must include the `ORDER BY` and `LIMIT` clauses.
|
||||
* The `ORDER BY` clause only supports a single vector condition.
|
||||
* The value of `LIMIT + OFFSET` must be in the range `(0, 16384]`.
|
||||
|
||||
* Rules for distance functions:
|
||||
* If `APPROXIMATE`/`APPROX` is specified, a supported distance function is called, and it matches the vector index algorithm, the query will use the vector index.
|
||||
* If `APPROXIMATE`/`APPROX` is specified, but the distance function does not match the vector index algorithm, the query will not use the vector index, but no error is returned.
|
||||
* If `APPROXIMATE`/`APPROX` is specified, but the distance function is not supported in the current version, the query will not use the vector index, and an error is returned.
|
||||
* If `APPROXIMATE`/`APPROX` is not specified, and a supported distance function is called, the query will not use the vector index, but no error is returned.
|
||||
|
||||
* Other notes:
|
||||
* The `WHERE` condition will serve as a filter after the vector index query.
|
||||
* Specifying the `LIMIT` clause is required; otherwise, an error will be returned.
|
||||
|
||||
## Create, query, and delete examples
|
||||
|
||||
### Create an index during table creation
|
||||
|
||||
#### Example of dense vector index
|
||||
|
||||
##### HNSW example
|
||||
|
||||
:::tip
|
||||
|
||||
When you create an HNSW index, the index name must be less than 25 characters in length. Otherwise, an exception may occur because the auxiliary table name exceeds the <code>index_name</code> limit. In future versions, the index name can be longer.
|
||||
:::
|
||||
|
||||
Create a test table.
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1(c1 INT, c0 INT, c2 VECTOR(10), c3 VECTOR(10), PRIMARY KEY(c1), VECTOR INDEX idx1(c2) WITH (distance=l2, type=hnsw, lib=vsag), VECTOR INDEX idx2(c3) WITH (distance=l2, type=hnsw, lib=vsag));
|
||||
```
|
||||
|
||||
Write test data.
|
||||
|
||||
```sql
|
||||
INSERT INTO t1 VALUES(1, 1,'[0.203846,0.205289,0.880265,0.824340,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833]', '[0.203846,0.205289,0.880265,0.824340,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833]');
|
||||
|
||||
INSERT INTO t1 VALUES(2, 2, '[0.735541,0.670776,0.903237,0.447223,0.232028,0.659316,0.765661,0.226980,0.579658,0.933939]', '[0.213846,0.205289,0.880265,0.824340,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833]');
|
||||
|
||||
INSERT INTO t1 VALUES(3, 3, '[0.327936,0.048756,0.084670,0.389642,0.970982,0.370915,0.181664,0.940780,0.013905,0.628127]', '[0.223846,0.205289,0.880265,0.824340,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833]');
|
||||
```
|
||||
|
||||
Perform an approximate nearest neighbor query.
|
||||
|
||||
```sql
|
||||
SELECT * FROM t1 ORDER BY l2_distance(c2, [0.712338,0.603321,0.133444,0.428146,0.876387,0.763293,0.408760,0.765300,0.560072,0.900498]) APPROXIMATE LIMIT 1;
|
||||
```
|
||||
|
||||
The query result is as follows:
|
||||
|
||||
```shell
|
||||
+----+------+-------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------+
|
||||
| c1 | c0 | c2 | c3 |
|
||||
+----+------+-------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------+
|
||||
| 3 | 3 | [0.327936,0.048756,0.08467,0.389642,0.970982,0.370915,0.181664,0.94078,0.013905,0.628127] | [0.223846,0.205289,0.880265,0.82434,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833] |
|
||||
+----+------+-------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
##### HNSW_SQ example
|
||||
|
||||
```sql
|
||||
CREATE TABLE t2 (c1 INT AUTO_INCREMENT, c2 VECTOR(3), PRIMARY KEY(c1), VECTOR INDEX idx1(c2) WITH (distance=l2, type=hnsw_sq, lib=vsag));
|
||||
```
|
||||
|
||||
##### HNSW_BQ example
|
||||
|
||||
```sql
|
||||
CREATE TABLE t3 (c1 INT AUTO_INCREMENT, c2 VECTOR(3), PRIMARY KEY(c1), VECTOR INDEX idx3(c2) WITH (distance=l2, type=hnsw_bq, lib=vsag));
|
||||
```
|
||||
|
||||
The `distance` parameter of HNSW_BQ supports only the l2 value.
|
||||
|
||||
##### IVF example
|
||||
|
||||
:::tip
|
||||
|
||||
When you create an IVF index, the index name must be less than 33 characters in length. Otherwise, an exception may occur because the auxiliary table name exceeds the <code>index_name</code> limit. In future versions, the index name can be longer.
|
||||
:::
|
||||
|
||||
```sql
|
||||
CREATE TABLE ivf_vecindex_suite_table_test (c1 INT, c2 VECTOR(3), PRIMARY KEY(c1), VECTOR INDEX idx2(c2) WITH (distance=l2, type=ivf_flat));
|
||||
```
|
||||
|
||||
### Create an index after table creation
|
||||
|
||||
:::tip
|
||||
|
||||
Currently, only dense vector indexes can be created after table creation.
|
||||
:::
|
||||
|
||||
#### Example of HNSW index
|
||||
|
||||
Create a test table.
|
||||
|
||||
```sql
|
||||
CREATE TABLE vec_table_hnsw (id INT, c2 VECTOR(10));
|
||||
```
|
||||
|
||||
Create an HNSW index.
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX vec_idx1 ON vec_table_hnsw(c2) WITH (distance=l2, type=hnsw);
|
||||
```
|
||||
|
||||
View the created table.
|
||||
|
||||
```sql
|
||||
SHOW CREATE TABLE vec_table_hnsw;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Table | Create Table |
|
||||
+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| vec_table_hnsw | CREATE TABLE `vec_table_hnsw` (
|
||||
`id` int(11) DEFAULT NULL,
|
||||
`c2` VECTOR(10) DEFAULT NULL,
|
||||
VECTOR KEY `vec_idx1` (`c2`) WITH (DISTANCE=L2, TYPE=HNSW, LIB=VSAG, M=16, EF_CONSTRUCTION=200, EF_SEARCH=64) BLOCK_SIZE 16384
|
||||
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
|
||||
+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
```sql
|
||||
SHOW INDEX FROM vec_table_hnsw;
|
||||
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
|
||||
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
|
||||
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
|
||||
| vec_table | 1 | vec_idx1 | 1 | c2 | A | NULL | NULL | NULL | YES | VECTOR | available | | YES | NULL |
|
||||
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
#### Example of HNSW_SQ index
|
||||
|
||||
Create a test table.
|
||||
|
||||
```sql
|
||||
CREATE TABLE vec_table_hnsw_sq (c1 INT AUTO_INCREMENT, c2 VECTOR(3), PRIMARY KEY(c1));
|
||||
```
|
||||
|
||||
Create an HNSW_SQ index.
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX vec_idx2 ON vec_table_hnsw_sq(c2) WITH (distance=l2, type=hnsw_sq, lib=vsag, m=16, ef_construction = 200);
|
||||
```
|
||||
|
||||
##### Example of HNSW_BQ index
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX vec_idx3 ON vec_table_hnsw_bq(c2) WITH (distance=l2, type=hnsw_bq, lib=vsag, m=16, ef_construction = 200);
|
||||
```
|
||||
|
||||
The `distance` parameter of the HNSW_BQ index can be used only with the L2 algorithm.
|
||||
|
||||
#### Example of IVF index
|
||||
|
||||
Create a test table.
|
||||
|
||||
```sql
|
||||
CREATE TABLE vec_table_ivf (c1 INT, c2 VECTOR(3), PRIMARY KEY(c1));
|
||||
```
|
||||
|
||||
Create an IVF index.
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX vec_idx3 ON vec_table_ivf(c2) WITH (distance=l2, type=ivf_flat);
|
||||
```
|
||||
|
||||
### Drop an index
|
||||
|
||||
```sql
|
||||
DROP INDEX vec_idx1 ON vec_table;
|
||||
```
|
||||
|
||||
View the dropped index.
|
||||
|
||||
```sql
|
||||
SHOW INDEX FROM vec_table;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
Empty set
|
||||
```
|
||||
|
||||
<!--## Monitoring
|
||||
|
||||
seekdb vector indexes provide monitoring capabilities:
|
||||
|
||||
* You can view the basic information and real-time status of HNSW/HNSW_SQ/HNSW_BQ indexes through the [GV$OB_HNSW_INDEX_INFO](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000004017373) view.
|
||||
* You can view the basic information and real-time status of IVF/IVF_SQ/IVF_PQ indexes through the [GV$OB_IVF_INDEX_INFO](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000004017374) view.-->
|
||||
|
||||
## Maintenance
|
||||
|
||||
When there is a large amount of incremental data, the query performance decreases. To reduce the amount of incremental data in the table, seekdb introduced the `DBMS_VECTOR` package for maintaining vector indexes.
|
||||
|
||||
### Incremental refresh
|
||||
|
||||
:::tip
|
||||
|
||||
IVF/IVF_SQ/IVF_PQ indexes do not support incremental refresh.
|
||||
:::
|
||||
|
||||
If a large amount of data is written after the index is created, we recommend that you perform an incremental refresh by using the `REFRESH_INDEX` procedure. For more information, see [REFRESH_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002753999).
|
||||
|
||||
The system checks for incremental data every 15 minutes. If more than 10,000 incremental data records are found, the system automatically performs an incremental refresh.
|
||||
|
||||
### Full refresh (rebuild)
|
||||
|
||||
#### Manual full table rebuild
|
||||
|
||||
If a large amount of data is updated or deleted after an index is created, it is recommended to use the `REBUILD_INDEX` procedure to perform a full refresh. For details and examples, see [REBUILD_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754000).
|
||||
|
||||
A full refresh is automatically checked every 24 hours. If the newly added data exceeds 20% of the original data, a full refresh will be triggered automatically. The full refresh runs asynchronously in the background: a new index is created first, and then the old index is replaced. During the rebuild process, the old index remains available, but the overall process is relatively slow.
|
||||
|
||||
We also provide the configuration item `vector_index_memory_saving_mode` to control the memory usage during index rebuild. Enabling this mode can reduce the memory consumption during vector index rebuild for partitioned tables. Typically, vector index rebuild requires memory equivalent to twice the index size. After enabling the memory-saving mode, the system will temporarily delete the memory index of a partition after building that partition to release memory, effectively reducing the total memory required for the rebuild operation. For syntax and examples, see [vector_index_memory_saving_mode](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002969408).
|
||||
|
||||
Notes:
|
||||
|
||||
* When executing offline DDL operations (such as `ALTER TABLE` to modify the table structure or primary key), the index table will be rebuilt. Since parallel degree cannot be specified for index rebuild, the system uses single-threaded execution by default. Therefore, when the data volume is large, the rebuild process will be slow, affecting the efficiency of the entire offline DDL operation.
|
||||
* When rebuilding an index, if you need to modify index parameters, you must specify both `type` and `distance` in the parameter list, and `type` and `distance` must match the original index type. For example, if the original index type is `hnsw` and the distance algorithm is `l2`, you must specify both `type=hnsw` and `distance=l2` during rebuild.
|
||||
* When rebuilding an index, the following are supported:
|
||||
* Modifying `m`, `ef_search`, and `ef_construction` values.
|
||||
* Online rebuild of the `ef_search` parameter.
|
||||
* Index type rebuild between `hnsw` - `hnsw_sq`.
|
||||
* Index type rebuild between `ivf_flat` - `ivf_flat`, `ivf_sq8` - `ivf_sq8`, `ivf_pq` - `ivf_pq`.
|
||||
* Setting parallel degree during rebuild. For examples, see [REBUILD_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754000).
|
||||
* When rebuilding an index, the following are not supported:
|
||||
* Modifying `type` and `distance` types.
|
||||
* Index rebuild between `hnsw` - `ivf`.
|
||||
* Index rebuild between `hnsw` - `hnsw_bq`.
|
||||
* Cross rebuild between `ivf_flat`, `ivf_pq`, and `ivf_sq8`.
|
||||
|
||||
#### Automatic partition rebuild (recommended)
|
||||
|
||||
:::tip
|
||||
<li>This feature is supported starting from V1.0.0. If your vector database is upgraded from an earlier version to V1.0.0, you need to manually rebuild all vector indexes for the entire table after the upgrade. Otherwise, automatic partition rebuild tasks may not be executed after the upgrade.</li><li>This feature only supports HNSW/HNSW_SQ/HNSW_BQ indexes.</li>
|
||||
:::
|
||||
|
||||
There are two scenarios that trigger automatic partition rebuild tasks in the current version:
|
||||
|
||||
* When executing vector index query statements.
|
||||
* Scheduled checks, with configurable execution cycle.
|
||||
|
||||
1. Configure execution cycle
|
||||
|
||||
In the `seekdb` database, configure the execution cycle through the configuration item `vector_index_optimize_duty_time`. Example:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET vector_index_optimize_duty_time='[23:00:00, 24:00:00]';
|
||||
```
|
||||
After the above configuration, partition rebuild tasks will only be executed between 23:00:00 and 24:00:00, and will not be initiated at other times. For detailed parameter descriptions, see the corresponding configuration item documentation.
|
||||
|
||||
2. View task progress/history
|
||||
|
||||
You can view task progress and history through the `CDB/DBA_OB_VECTOR_INDEX_TASKS` or `CDB/DBA_OB_VECTOR_INDEX_TASK_HISTORY` view.
|
||||
|
||||
Determine the current task status through the `status` field:
|
||||
|
||||
* 0 (PREPARE): The task is waiting to be executed.
|
||||
* 1 (RUNNING): The task is being executed.
|
||||
* 2 (PENDING): The task is paused.
|
||||
* 3 (FINISHED): The task has been completed.
|
||||
|
||||
Completed tasks, i.e., tasks with `status=FINISHED`, will be archived to the history table regardless of whether they succeeded. For detailed usage examples, see the corresponding view documentation.
|
||||
|
||||
3. Cancel task
|
||||
|
||||
To cancel a task, obtain the trace_id from the `DBA_OB_VECTOR_INDEX_TASKS` or `CDB_OB_VECTOR_INDEX_TASKS` view, then execute the following command:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM CANCEL TASK <trace_id>;
|
||||
```
|
||||
Example:
|
||||
```sql
|
||||
ALTER SYSTEM CANCEL TASK "Y61480BA2D976-00063084E80435E2-0-1";
|
||||
```
|
||||
|
||||
## Performance optimization
|
||||
|
||||
:::tip
|
||||
Only the IVF index is supported.
|
||||
:::
|
||||
|
||||
seekdb provides an automatic performance optimization mechanism for the IVF index to improve query performance through cache management and regular maintenance.
|
||||
|
||||
### Optimization mechanism
|
||||
|
||||
IVF index performance optimization includes two types of automated tasks:
|
||||
|
||||
1. Cache warming task: Periodically checks all IVF indexes. If it finds that the cache corresponding to an index does not exist, it automatically triggers cache warming and loads the index data into memory. Additionally, cache warming is automatically performed when an IVF index is created.
|
||||
2. Cache cleanup task: Periodically checks all IVF caches. If it finds that the cache corresponds to an index that has been deleted, it automatically cleans up the invalid cache and releases memory resources. Additionally, cache cleanup is automatically performed when an IVF index is deleted.
|
||||
|
||||
### Configure the optimization cycle
|
||||
|
||||
The system allows you to customize the execution time window for performance optimization tasks to avoid impacting performance during peak business hours.
|
||||
|
||||
In the `seekdb` database, you can set the execution cycle using the `vector_index_optimize_duty_time` parameter:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET vector_index_optimize_duty_time='[23:00:00, 24:00:00]';
|
||||
```
|
||||
|
||||
The configuration is described as follows:
|
||||
|
||||
* The time format is `[start time, end time]`.
|
||||
* The above configuration means that optimization tasks will only be executed between 23:00:00 and 24:00:00.
|
||||
* Optimization tasks will not be initiated at other times to avoid impacting normal business operations.
|
||||
|
||||
### Monitor optimization tasks
|
||||
|
||||
seekdb vector indexes provide monitoring capabilities for optimization tasks:
|
||||
|
||||
* You can view tasks that are being executed or waiting to be executed through the `DBA_OB_VECTOR_INDEX_TASKS` view.
|
||||
* You can view historical task records through the `DBA_OB_VECTOR_INDEX_TASK_HISTORY` view.
|
||||
|
||||
Usage examples:
|
||||
|
||||
1. View the current task status
|
||||
|
||||
View tasks that are being executed or waiting to be executed through the `DBA_OB_VECTOR_INDEX_TASKS` view:
|
||||
|
||||
```sql
|
||||
SELECT * FROM oceanbase.DBA_OB_VECTOR_INDEX_TASKS;
|
||||
```
|
||||
|
||||
Sample return result:
|
||||
|
||||
```shell
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| TABLE_ID | TABLET_ID | TASK_ID | START_TIME | MODIFY_TIME | TRIGGER_TYPE | STATUS | TASK_TYPE | TASK_SCN | RET_CODE | TRACE_ID |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| 500020 | 1152921504606846990 | 2002281 | 1970-08-23 17:10:23.174127 | 1970-08-23 17:10:23.174137 | USER | FINISHED | 2 | 1750671687770026 | 0 | YAFF00B9E4D97-00063839E6BD9BBC-0-1 |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
Description of the task status:
|
||||
|
||||
* `STATUS = 0`: PREPARE, the task is waiting to be executed.
|
||||
* `STATUS = 1`: RUNNING, the task is being executed.
|
||||
* `STATUS = 3`: FINISHED, the task has been completed.
|
||||
|
||||
Description of the task type:
|
||||
|
||||
* `TASK_TYPE = 2`: IVF cache warming task.
|
||||
* `TASK_TYPE = 3`: IVF invalid cache cleanup task.
|
||||
|
||||
2. View the history task records
|
||||
|
||||
Completed tasks (with `STATUS = 3`) are automatically archived to the history table every 10 seconds, regardless of whether they were successful. View the history through the `DBA_OB_VECTOR_INDEX_TASKS_HISTORY` view:
|
||||
|
||||
```sql
|
||||
-- Query the history of a specified task ID
|
||||
SELECT * FROM oceanbase.DBA_OB_VECTOR_INDEX_TASKS_HISTORY WHERE TASK_ID=2002281;
|
||||
```
|
||||
|
||||
Sample return result:
|
||||
|
||||
```shell
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| TABLE_ID | TABLET_ID | TASK_ID | START_TIME | MODIFY_TIME | TRIGGER_TYPE | STATUS | TASK_TYPE | TASK_SCN | RET_CODE | TRACE_ID |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| 500020 | 1152921504606846990 | 2002281 | 1970-08-23 17:10:23.174127 | 1970-08-23 17:10:23.174137 | AUTO | FINISHED | 2 | 1750671687770026 | 0 | YAFF00B9E4D97-00063839E6BD9BBC-0-1 |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Cancel an optimization task
|
||||
|
||||
You can cancel a specified task by using the following command:
|
||||
|
||||
```sql
|
||||
-- trace_id is obtained from the DBA_OB_VECTOR_INDEX_TASKS_HISTORY view
|
||||
ALTER SYSTEM CANCEL TASK <trace_id>;
|
||||
```
|
||||
|
||||
:::tip
|
||||
You can cancel a task only in the failed retry phase by executing the <code>ALTER SYSTEM CANCEL TASK</code> statement. If a background task is stuck in a specific execution phase, it cannot be canceled by using this statement.
|
||||
:::
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
-- Log in to the system and obtain the trace_id of the specified task
|
||||
SELECT * FROM oceanbase.DBA_OB_VECTOR_INDEX_TASK_HISTORY WHERE TASK_ID=2037736;
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| TABLE_ID | TABLET_ID | TASK_ID | START_TIME | MODIFY_TIME | TRIGGER_TYPE | STATUS | TASK_TYPE | TASK_SCN | RET_CODE | TRACE_ID |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| 500041 | 1152921504606847008 | 2037736 | 1970-08-23 17:10:23.203821 | 1970-08-23 17:10:23.203821 | USER | PREPARED | 2 | 1750682301145225 | -1 | YAFF00B9E4D97-00063839E6BDDEE0-0-1 |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
```sql
|
||||
-- Cancel the task
|
||||
ALTER SYSTEM CANCEL TASK "YAFF00B9E4D97-00063839E6BDDEE0-0-1";
|
||||
```
|
||||
|
||||
After the task is canceled, the task status changes to `CANCELLED`.
|
||||
|
||||
```sql
|
||||
-- Log in to the user database and query the task status
|
||||
SELECT * FROM oceanbase.DBA_OB_VECTOR_INDEX_TASK_HISTORY;
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| TABLE_ID | TABLET_ID | TASK_ID | START_TIME | MODIFY_TIME | TRIGGER_TYPE | STATUS | TASK_TYPE | TASK_SCN | RET_CODE | TRACE_ID |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| 500041 | 1152921504606847008 | 2037736 | 1970-08-23 17:10:23.203821 | 1970-08-23 17:10:23.203821 | USER | FINISHED | 2 | 1750682301145225 | -4072 | YAFF00B9E4D97-00063839E6BDDEE0-0-1 |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Use SQL functions](../250.vector-function.md)
|
||||
@@ -0,0 +1,374 @@
|
||||
---
|
||||
|
||||
slug: /hybrid-vector-index
|
||||
---
|
||||
|
||||
# Create a hybrid vector index
|
||||
|
||||
This topic describes how to create a hybrid vector index in seekdb.
|
||||
|
||||
## Overview
|
||||
|
||||
Hybrid vector indexes leverage seekdb's built-in embedding capabilities to greatly simplify the vector index usage process. They make the vector concept transparent to users: you can directly write raw data (such as text) that needs to be stored, and seekdb will automatically convert it to vectors and build indexes internally. During retrieval, you only need to provide the raw query content, and seekdb will also automatically perform embedding and retrieve the vector index, significantly improving ease of use.
|
||||
|
||||
Considering the performance overhead of embedding models, hybrid vector indexes provide two embedding modes for users to choose from:
|
||||
* Synchronous mode: Embedding and indexing are performed immediately after data is written, ensuring real-time data visibility.
|
||||
* Asynchronous mode: Background tasks perform data embedding and indexing in batches, which can significantly improve write performance. You can flexibly set the trigger cycle of background tasks based on your requirements for real-time data visibility.
|
||||
|
||||
In addition, this feature also provides the capability to perform brute-force search on hybrid vector indexes to help verify the correctness of search results. Brute-force search refers to performing a search using a full table scan to obtain the exact results of the n nearest rows.
|
||||
|
||||
## Feature support
|
||||
|
||||
:::tip
|
||||
This feature currently supports only HNSW/HNSW_BQ indexes.
|
||||
:::
|
||||
|
||||
This feature supports the full lifecycle of hybrid vector indexes, including creation, update, deletion, and retrieval, and is compatible with `REFRESH_INDEX` and `REBUILD_INDEX` in the `DBMS_VECTOR` system package. The syntax for update, deletion, and retrieval is exactly the same as that for regular vector indexes. In asynchronous mode, `REFRESH_INDEX` will additionally trigger data embedding. For details about creation and retrieval, see the sections below.
|
||||
|
||||
The supported features are as follows:
|
||||
|
||||
| Module | Feature | Description |
|
||||
|------|--------|------|
|
||||
| DDL | Create a hybrid vector index during table creation | You can create a hybrid vector index on a `VARCHAR` column when creating a table |
|
||||
| DDL | Create a hybrid vector index after table creation | Supports creating a hybrid vector index on a `VARCHAR` column of an existing table |
|
||||
| Retrieval | `semantic_distance` function | Pass raw data through this function for vector retrieval |
|
||||
| Retrieval | `semantic_vector_distance` function | Pass vectors through this function for retrieval. There are two usage modes: <ul><li>When the SQL statement includes the `APPROXIMATE`/`APPROX` clause, vector index retrieval is used.</li><li>When the `APPROXIMATE`/`APPROX` clause is not included, brute-force search using a full table scan is performed.</li></ul> |
|
||||
| DBMS_VECTOR | `REFRESH_INDEX` | The usage is the same as that for regular vector indexes. Performs incremental index refresh and embedding in asynchronous mode |
|
||||
| DBMS_VECTOR | `REBUILD_INDEX` | The usage is the same as that for regular vector indexes. Performs full index rebuild |
|
||||
|
||||
Some usage notes are as follows:
|
||||
|
||||
* In synchronous mode, write performance may be affected by embedding performance. In asynchronous mode, data visibility will be delayed.
|
||||
* For repeated retrieval scenarios, it is recommended to use AI Function Service to pre-obtain query vectors to avoid embedding for each retrieval.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using hybrid vector indexes, you must register an embedding model and endpoint. The following is a registration example:
|
||||
|
||||
```sql
|
||||
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_embed');
|
||||
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_embed_endpoint');
|
||||
|
||||
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
|
||||
'ob_embed', '{
|
||||
"type": "dense_embedding",
|
||||
"model_name": "BAAI/bge-m3"
|
||||
}');
|
||||
|
||||
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
|
||||
'ob_embed_endpoint', '{
|
||||
"ai_model_name": "ob_embed",
|
||||
"url": "https://api.siliconflow.cn/v1/embeddings",
|
||||
"access_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxx",
|
||||
"provider": "siliconflow"
|
||||
}');
|
||||
```
|
||||
|
||||
:::info
|
||||
Replace <code>access_key</code> with your actual API Key. The BAAI/bge-m3 model has a vector dimension of 1024, so you need to use <code>dim=1024</code> when creating a hybrid vector index.
|
||||
:::
|
||||
|
||||
## Creation syntax and description
|
||||
|
||||
Hybrid vector indexes support two creation methods: **creation during table creation** and **creation after table creation**. When creating an index, note the following:
|
||||
|
||||
* The index must be created on a column of the `VARCHAR` type.
|
||||
* The `model` and `sync_mode` parameters are not supported for regular vector indexes.
|
||||
* The parameters and descriptions for an index created after table creation are the same as those for an index created during table creation.
|
||||
|
||||
### Create during table creation
|
||||
|
||||
You can use the `CREATE TABLE` statement to create a hybrid vector index. Through index parameters, background tasks can be initiated synchronously or asynchronously. In synchronous mode, `VARCHAR` data is automatically converted to vector data when data is inserted. In asynchronous mode, data conversion is performed periodically or manually.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 data_type1,
|
||||
column_name2 VARCHAR, -- Text column
|
||||
...,
|
||||
VECTOR INDEX index_name (column_name2) WITH (param1=value1, param2=value2, ...)
|
||||
);
|
||||
```
|
||||
|
||||
#### Parameter description
|
||||
|
||||
| Parameter | Default value | Value range | Required | Description | Remarks |
|
||||
|------|--------|----------|----------|------|------|
|
||||
| `distance` | | `l2`/`inner_product`/`cosine` | Yes | Specifies the vector distance algorithm type. | `l2` indicates Euclidean distance, `inner_product` indicates inner product distance, and `cosine` indicates cosine distance. |
|
||||
| `type` | | Currently supports `hnsw` / `hnsw_bq` | Yes | Specifies the index algorithm type. | |
|
||||
| `lib` | `vsag` | `vsag` | No | Specifies the vector index library type. | Currently, only the VSAG vector library is supported. |
|
||||
| `model` | | Registered model name | Yes | Specifies the large language model name used for embedding. | The model must be registered using AI Function Service before creating the index.<main id="notice" type='notice'><h4>Note</h4><p>Regular vector indexes do not support setting this parameter.</p></main> |
|
||||
| `dim` | | Positive integer, maximum 4096 | Yes | Specifies the vector dimension after embedding. | Must match the dimension provided by the model. |
|
||||
| `sync_mode` | `async` | `immediate`/`manual`/`async` | No | Specifies the data and index synchronization mode. | `immediate` indicates synchronous mode, `manual` indicates manual mode, and `async` indicates asynchronous mode.<main id="notice" type='notice'><h4>Note</h4><p>Regular vector indexes do not support setting this parameter.</p></main> |
|
||||
| `sync_interval` | `10s` | Time interval, such as `10s`, `1h`, `1d`, etc. | No | Sets the trigger cycle of background tasks in asynchronous mode. | The numeric part must be positive. Units supported include seconds (s), hours (h), days (d), etc. |
|
||||
|
||||
The usage of other vector index parameters (such as `m`, `ef_construction`, `ef_search`, etc.) is the same as that for regular vector indexes. For details, see the related documentation.
|
||||
|
||||
### Create after table creation
|
||||
|
||||
Supports creating a hybrid vector index on a `VARCHAR` column of an existing table. When creating an index after table creation, synchronous or asynchronous background tasks are initiated through the provided index parameters. In synchronous mode, all existing `VARCHAR` data is converted to vector data. In asynchronous mode, data conversion is performed periodically or manually.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX index_name
|
||||
ON table_name(varchar_column_name)
|
||||
WITH (param1=value1, param2=value2, ...);
|
||||
```
|
||||
|
||||
#### Parameter description
|
||||
|
||||
The parameter description is the same as that for creating an index during table creation. For details, see the section above.
|
||||
|
||||
## Create, update, and delete examples
|
||||
|
||||
DML operations (`INSERT`, `UPDATE`, `DELETE`) for hybrid vector indexes are exactly the same as those for regular vector indexes. When inserting or updating data of the `VARCHAR` type, the system automatically or asynchronously performs embedding based on the `sync_mode` parameter setting.
|
||||
|
||||
### Create during table creation
|
||||
|
||||
Create the `vector_idx` index when creating the test table `items`:
|
||||
|
||||
```sql
|
||||
-- Assume that the ob_embed model has been created previously (please refer to the "Prerequisites" section to register the model)
|
||||
CREATE TABLE items (
|
||||
id BIGINT PRIMARY KEY,
|
||||
doc VARCHAR(100),
|
||||
VECTOR INDEX vector_idx(doc)
|
||||
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=async, sync_interval=10s)
|
||||
);
|
||||
```
|
||||
|
||||
Insert a row of data into the test table `items`. The system will automatically perform embedding:
|
||||
|
||||
```sql
|
||||
INSERT INTO items(id, doc) VALUES(1, 'Rose');
|
||||
```
|
||||
|
||||
### Create after table creation
|
||||
|
||||
After creating the test table `items`, use the `CREATE VECTOR INDEX` statement to create the `vector_idx` index:
|
||||
|
||||
```sql
|
||||
CREATE TABLE items (
|
||||
id BIGINT PRIMARY KEY,
|
||||
doc VARCHAR(100)
|
||||
);
|
||||
|
||||
-- Assume that the ob_embed model has been created previously (please refer to the "Prerequisites" section to register the model)
|
||||
CREATE VECTOR INDEX vector_idx
|
||||
ON items (doc)
|
||||
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=async, sync_interval=10s);
|
||||
```
|
||||
|
||||
Insert a row of data into the test table `items`. The system will automatically perform embedding:
|
||||
|
||||
```sql
|
||||
INSERT INTO items(id, doc) VALUES(1, 'Rose');
|
||||
```
|
||||
|
||||
### Update
|
||||
|
||||
When updating data of the `VARCHAR` type, the system will re-perform embedding:
|
||||
|
||||
* Synchronous mode: Re-embedding is performed immediately after update.
|
||||
* Asynchronous mode: Re-embedding is performed by background tasks at the next trigger cycle after update.
|
||||
|
||||
Usage example:
|
||||
|
||||
```sql
|
||||
UPDATE items SET doc = 'Lily' WHERE id = 1;
|
||||
```
|
||||
|
||||
### Delete
|
||||
|
||||
The delete operation is the same as that for regular vector indexes. You can directly delete the data.
|
||||
|
||||
Usage example:
|
||||
|
||||
```sql
|
||||
DELETE FROM items WHERE id = 1;
|
||||
```
|
||||
|
||||
## Retrieval
|
||||
|
||||
Hybrid vector indexes support two retrieval methods:
|
||||
|
||||
* Retrieve using raw text
|
||||
* Retrieve using vectors
|
||||
|
||||
For detailed usage of the `APPROXIMATE`/`APPROX` clause, see the related documentation on creating vector indexes at the end of this topic.
|
||||
|
||||
### Retrieve using raw text
|
||||
|
||||
Use the `semantic_distance` expression to pass raw text for vector retrieval.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
SELECT ... FROM table_name
|
||||
ORDER BY semantic_distance(column_name, 'query_text') [APPROXIMATE|APPROX]
|
||||
LIMIT n;
|
||||
```
|
||||
|
||||
Where:
|
||||
* `column_name`: The text column specified when creating the hybrid vector index.
|
||||
* `query_text`: The raw text for retrieval.
|
||||
* `n`: The number of result rows to return.
|
||||
|
||||
#### Usage example
|
||||
|
||||
```sql
|
||||
-- Assume that the ob_embed model has been created previously
|
||||
CREATE TABLE items (
|
||||
id INT PRIMARY KEY,
|
||||
doc varchar(100),
|
||||
VECTOR INDEX vector_idx(doc)
|
||||
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=immediate)
|
||||
);
|
||||
|
||||
INSERT INTO items(id, doc) VALUES(1, 'Rose');
|
||||
INSERT INTO items(id, doc) VALUES(2, 'Sunflower');
|
||||
INSERT INTO items(id, doc) VALUES(3, 'Rose');
|
||||
INSERT INTO items(id, doc) VALUES(4, 'Sunflower');
|
||||
INSERT INTO items(id, doc) VALUES(5, 'Rose');
|
||||
|
||||
-- Retrieve using raw text
|
||||
SELECT id, doc FROM items
|
||||
ORDER BY semantic_distance(doc, 'Sunflower')
|
||||
APPROXIMATE LIMIT 3;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```sql
|
||||
+----+-----------+
|
||||
| id | doc |
|
||||
+----+-----------+
|
||||
| 2 | Sunflower |
|
||||
| 4 | Sunflower |
|
||||
| 5 | Rose |
|
||||
+----+-----------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
### Retrieve using vectors (with APPROXIMATE clause)
|
||||
|
||||
Use the `semantic_vector_distance` expression to pass vectors for retrieval. When the retrieval statement includes the `APPROXIMATE`/`APPROX` clause, vector index retrieval is used.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
SELECT ... FROM table_name
|
||||
ORDER BY semantic_vector_distance(column_name, 'query_vector') [APPROXIMATE|APPROX]
|
||||
LIMIT n;
|
||||
```
|
||||
|
||||
Where:
|
||||
* `column_name`: The text column specified when creating the hybrid vector index.
|
||||
* `query_vector`: The query vector.
|
||||
* `n`: The number of result rows to return.
|
||||
|
||||
#### Usage example
|
||||
|
||||
```sql
|
||||
-- Assume that the ob_embed model has been created previously (please refer to the "Prerequisites" section to register the model)
|
||||
CREATE TABLE items (
|
||||
id INT PRIMARY KEY,
|
||||
doc varchar(100),
|
||||
VECTOR INDEX vector_idx(doc)
|
||||
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=immediate)
|
||||
);
|
||||
|
||||
INSERT INTO items(id, doc) VALUES(1, 'Rose');
|
||||
INSERT INTO items(id, doc) VALUES(2, 'Lily');
|
||||
INSERT INTO items(id, doc) VALUES(3, 'Sunflower');
|
||||
INSERT INTO items(id, doc) VALUES(4, 'Rose');
|
||||
|
||||
-- First, obtain the query vector
|
||||
SET @query_vector = AI_EMBED('ob_embed', 'Sunflower');
|
||||
|
||||
-- Retrieve using vectors with index
|
||||
SELECT id, doc FROM items
|
||||
ORDER BY semantic_vector_distance(doc, @query_vector)
|
||||
APPROXIMATE LIMIT 3;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+-----------+
|
||||
| id | doc |
|
||||
+----+-----------+
|
||||
| 3 | Sunflower |
|
||||
| 1 | Rose |
|
||||
| 4 | Rose |
|
||||
+----+-----------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
### Retrieve using vectors (without APPROXIMATE clause)
|
||||
|
||||
Use the `semantic_vector_distance` expression to pass vectors for retrieval. When the `APPROXIMATE`/`APPROX` clause is not included, brute-force search using a full table scan is performed to obtain the exact results of the n nearest rows. During retrieval execution, the `distance` type is obtained from the table schema, and then a full table scan is performed. Vector distance is calculated for each row to ensure accurate results.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
SELECT ... FROM table_name
|
||||
ORDER BY semantic_vector_distance(column_name, 'query_vector')
|
||||
LIMIT n;
|
||||
```
|
||||
|
||||
Where:
|
||||
* `column_name`: The text column specified when creating the hybrid vector index.
|
||||
* `query_vector`: The query vector.
|
||||
* `n`: The number of result rows to return.
|
||||
|
||||
#### Usage example
|
||||
|
||||
```sql
|
||||
-- Retrieve using vectors with brute-force search (exact results)
|
||||
SELECT id, doc FROM items
|
||||
ORDER BY semantic_vector_distance(doc, @query_vector)
|
||||
LIMIT 3;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+-----------+
|
||||
| id | doc |
|
||||
+----+-----------+
|
||||
| 3 | Sunflower |
|
||||
| 4 | Rose |
|
||||
| 1 | Rose |
|
||||
+----+-----------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
## Index maintenance
|
||||
|
||||
Hybrid vector indexes support using the `DBMS_VECTOR` system package for index maintenance, including incremental refresh and full rebuild.
|
||||
|
||||
### Incremental refresh
|
||||
|
||||
If a large amount of data is written after the index is created, it is recommended to use the `REFRESH_INDEX` procedure for incremental refresh. For descriptions and examples, see the related documentation.
|
||||
|
||||
Special notes for hybrid vector indexes:
|
||||
* The usage is the same as that for regular vector indexes. For details, see the related documentation.
|
||||
* In asynchronous mode, `REFRESH_INDEX` will additionally trigger data embedding to ensure that incremental data is correctly converted to vectors and added to the index.
|
||||
|
||||
### Full refresh (rebuild)
|
||||
|
||||
If a large amount of data is updated or deleted after the index is created, it is recommended to use the `REBUILD_INDEX` procedure for full refresh. For descriptions and examples, see the related documentation.
|
||||
|
||||
Special notes for hybrid vector indexes:
|
||||
* The usage is the same as that for regular vector indexes. For details, see the related documentation.
|
||||
* The task merges incremental data and snapshots.
|
||||
|
||||
## Related documentation
|
||||
|
||||
* [AI Function Service](../../300.ai-function/200.ai-function.md)
|
||||
* [Create a vector index](200.dense-vector-index.md)
|
||||
* [REFRESH_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002753999)
|
||||
* [REBUILD_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754000)
|
||||
@@ -0,0 +1,279 @@
|
||||
---
|
||||
|
||||
slug: /in-memory-sparse-vector-index
|
||||
---
|
||||
|
||||
# In-memory sparse vector index
|
||||
|
||||
This topic describes how to create, query, and use in-memory sparse vector indexes in seekdb.
|
||||
|
||||
## Overview
|
||||
|
||||
In-memory sparse vector indexes are an efficient index type provided by seekdb for sparse vector data (vectors where most elements are zero). In-memory sparse vector indexes must be fully loaded into memory and support DML and real-time queries.
|
||||
|
||||
To improve the query performance of sparse vectors, seekdb integrates the sparse vector index (SINDI) from the VSAG algorithm library. This index performs better than disk-based sparse vector indexes and is suitable for use when memory resources are sufficient.
|
||||
|
||||
## Feature support
|
||||
|
||||
In-memory sparse vector indexes support the following features:
|
||||
|
||||
| Module | Feature | Description |
|
||||
|------|--------|------|
|
||||
| DDL | Create a sparse vector index during table creation | You can create a sparse vector index on a `SPARSEVECTOR` column when creating a table. The maximum supported dimension is 500,000. |
|
||||
| DDL | Create a sparse vector index after table creation | Supports creating a sparse vector index on a `SPARSEVECTOR` column of an existing table. The maximum supported dimension is 500,000. |
|
||||
| DML | Insert, update, delete | The syntax for DML operations is exactly the same as that for regular vector indexes. |
|
||||
| Retrieval | Vector retrieval | Supports retrieval using SQL functions. |
|
||||
| Retrieval | Query parameters | Supports setting query-level parameters through the `parameters` clause during retrieval. |
|
||||
| DBMS_VECTOR | `REFRESH_INDEX` | Performs incremental index refresh. |
|
||||
| DBMS_VECTOR | `REBUILD_INDEX` | Performs full index rebuild. |
|
||||
|
||||
## Index memory estimation and actual usage query
|
||||
|
||||
Supports index memory estimation through the `DBMS_VECTOR` system package. The usage is the same as that for dense indexes. Here, only the special requirements for sparse vector indexes are described:
|
||||
|
||||
* The `IDX_TYPE` parameter must be set to `SINDI`, case-insensitive.
|
||||
|
||||
## Creation syntax and description
|
||||
|
||||
In-memory sparse vector indexes support two creation methods: **creation during table creation** and **creation after table creation**. When creating an index, note the following:
|
||||
|
||||
* The maximum supported dimension for columns on which sparse vector indexes are created is 500,000.
|
||||
* Sparse vector indexes must be created on columns of the `SPARSEVECTOR` type.
|
||||
* The `VECTOR` keyword is required when creating an index.
|
||||
* The index type must be set to `sindi`, which indicates creating an in-memory sparse vector index.
|
||||
* Only the `inner_product` (inner product) distance algorithm is supported.
|
||||
* The parameters and descriptions for an index created after table creation are the same as those for an index created during table creation.
|
||||
|
||||
### Create during table creation
|
||||
|
||||
Supports using the `CREATE TABLE` statement to create a sparse vector index.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 data_type1,
|
||||
column_name2 SPARSEVECTOR,
|
||||
...,
|
||||
VECTOR INDEX index_name (column_name2) WITH (param1=value1, param2=value2, ...)
|
||||
);
|
||||
```
|
||||
|
||||
#### Parameter description
|
||||
|
||||
| Parameter | Default value | Value range | Required | Description | Remarks |
|
||||
|------|--------|----------|----------|------|------|
|
||||
| `distance` | | `inner_product` | Yes | Specifies the vector distance algorithm type. | Sparse vector indexes support only inner product (`inner_product`) as the distance algorithm. |
|
||||
| `type` | | `sindi` | Yes | Specifies the index algorithm type. | Indicates creating an in-memory sparse vector index. |
|
||||
| `lib` | `vsag` | `vsag` | No | Specifies the vector index library type. | Currently, only the VSAG vector library is supported. |
|
||||
| `prune` | `false` | `true`/`false` | No | Whether to perform pruning on vectors. | When `prune` is `true`, you need to set the `refine` and `drop_ratio_build` parameters. When `prune` is `false`, full-precision retrieval can be provided. If `refine` is set to `true` or `drop_ratio_build` is not `0`, an error will be returned. |
|
||||
| `refine` | `false` | `true`/`false` | No | Whether reranking is needed. | When set to `true`, the original sparse vectors are retrieved for the search results to perform high-precision distance calculation and reranking, which means an additional copy of the original vector data needs to be stored. Can be set only when `prune=true`. |
|
||||
| `drop_ratio_build` | `0` | `[0, 0.9]` | No | The pruning ratio for sparse vector data. | When a new sparse vector is inserted, the `query_length * drop_ratio_build` smallest values are pruned based on value size. If `refine` is `true`, the original vector data is preserved. Otherwise, only the pruned data is retained. Can be set only when `prune=true`. |
|
||||
| `drop_ratio_search` | `0` | `[0, 0.9]` | No | The pruning ratio for sparse vector values during retrieval. | The larger the value, the more pruning is performed, the lower the accuracy, and the higher the performance. Can also be set through the `parameters` clause during retrieval, and query parameters have higher priority. |
|
||||
| `refine_k` | `4.0` | `[1.0, 1000.0]` | No | Indicates the proportion of results participating in reranking. | Retrieves `limit_k * refine_k` results and obtains the original vectors for reranking. Meaningful only when `refine=true`. Can also be set through the `parameters` clause during retrieval, and query parameters have higher priority. |
|
||||
|
||||
### Create after table creation
|
||||
|
||||
Supports creating a sparse vector index on a `SPARSEVECTOR` column of an existing table.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX index_name ON table_name(column_name) WITH (param1=value1, param2=value2, ...);
|
||||
```
|
||||
|
||||
#### Parameter description
|
||||
|
||||
The parameter description is the same as that for creating an index during table creation. For details, see the section above.
|
||||
|
||||
## Create, update, and delete examples
|
||||
|
||||
### Create during table creation
|
||||
|
||||
Create the test table `sparse_t1` and create a sparse vector index:
|
||||
|
||||
```sql
|
||||
CREATE TABLE sparse_t1 (
|
||||
c1 INT PRIMARY KEY,
|
||||
c2 SPARSEVECTOR,
|
||||
VECTOR INDEX sparse_idx1(c2)
|
||||
WITH (lib=vsag, type=sindi, distance=inner_product)
|
||||
);
|
||||
```
|
||||
|
||||
Insert sparse vector data into the test table:
|
||||
|
||||
```sql
|
||||
INSERT INTO sparse_t1 VALUES(1, '{1:0.1, 2:0.2, 3:0.3}');
|
||||
INSERT INTO sparse_t1 VALUES(2, '{3:0.3, 2:0.2, 4:0.4}');
|
||||
INSERT INTO sparse_t1 VALUES(3, '{3:0.3, 4:0.4, 5:0.5}');
|
||||
```
|
||||
|
||||
Query the test table:
|
||||
|
||||
```sql
|
||||
SELECT * FROM sparse_t1;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```
|
||||
+----+---------------------+
|
||||
| c1 | c2 |
|
||||
+----+---------------------+
|
||||
| 1 | {1:0.1,2:0.2,3:0.3} |
|
||||
| 2 | {2:0.2,3:0.3,4:0.4} |
|
||||
| 3 | {3:0.3,4:0.4,5:0.5} |
|
||||
+----+---------------------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
### Create after table creation
|
||||
|
||||
Create a sparse vector index after creating the test table:
|
||||
|
||||
```sql
|
||||
CREATE TABLE sparse_t2 (
|
||||
c1 INT PRIMARY KEY,
|
||||
c2 SPARSEVECTOR
|
||||
);
|
||||
|
||||
CREATE VECTOR INDEX sparse_idx2 ON sparse_t2(c2)
|
||||
WITH (lib=vsag, type=sindi, distance=inner_product,
|
||||
prune=true, refine=true, drop_ratio_build=0.1,
|
||||
drop_ratio_search=0.5, refine_k=2.0);
|
||||
```
|
||||
|
||||
Insert sparse vector data into the test table:
|
||||
|
||||
```sql
|
||||
INSERT INTO sparse_t2 VALUES(1, '{1:0.1, 2:0.2, 3:0.3}');
|
||||
```
|
||||
|
||||
Query the test table:
|
||||
|
||||
```sql
|
||||
SELECT * FROM sparse_t2;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+---------------------+
|
||||
| c1 | c2 |
|
||||
+----+---------------------+
|
||||
| 1 | {1:0.1,2:0.2,3:0.3} |
|
||||
+----+---------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Update
|
||||
|
||||
When updating sparse vector data, the index is automatically maintained:
|
||||
|
||||
```sql
|
||||
UPDATE sparse_t1 SET c2 = '{1:0.1}' WHERE c1 = 1;
|
||||
```
|
||||
|
||||
### Delete
|
||||
|
||||
The delete operation is the same as that for regular vector indexes. You can directly delete the data:
|
||||
|
||||
```sql
|
||||
DELETE FROM sparse_t1 WHERE c1 = 1;
|
||||
```
|
||||
|
||||
## Retrieval
|
||||
|
||||
The retrieval syntax for sparse vector indexes is similar to that for dense vector indexes, using the `APPROXIMATE`/`APPROX` keyword for approximate nearest neighbor retrieval.
|
||||
|
||||
### Syntax
|
||||
|
||||
```sql
|
||||
SELECT ... FROM table_name
|
||||
ORDER BY inner_product(column_name, query_vector) [APPROXIMATE|APPROX]
|
||||
LIMIT n [PARAMETERS(param1=value1, param2=value2)];
|
||||
```
|
||||
|
||||
Where:
|
||||
* `column_name`: The `SPARSEVECTOR` column specified when creating the sparse vector index.
|
||||
* `query_vector`: The query vector, which can be a string in sparse vector format, such as `'{1:2.4, 3:1.5}'`.
|
||||
* `n`: The number of result rows to return.
|
||||
* `PARAMETERS`: Optional query-level parameters for setting `drop_ratio_search` and `refine_k`.
|
||||
|
||||
### Retrieval usage notes
|
||||
|
||||
For detailed requirements, see [Dense vector index](../200.dense-vector-index.md). Here, only the special requirements for sparse vector indexes are described:
|
||||
|
||||
* Query parameter priority: Query-level parameters set by `PARAMETERS` > Query parameters set when building the index > Default values.
|
||||
* `drop_ratio_search`: Value range `[0, 0.9]`, default value `0`. The pruning ratio for sparse vector values during retrieval. The larger the value, the more pruning is performed, the lower the accuracy, and the higher the performance. Prunes the `query_length * drop_ratio_search` smallest values based on value size. Since pruning all values is meaningless, at least one value is always retained.
|
||||
* `refine_k`: Value range `[1.0, 1000.0]`, default value `4.0`. Indicates the proportion of results participating in reranking. Queries `limit_k * refine_k` results and obtains the original vectors for reranking. Effective only when `refine=true`.
|
||||
|
||||
### Usage examples
|
||||
|
||||
#### Regular query
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1 (
|
||||
c1 INT PRIMARY KEY,
|
||||
c2 SPARSEVECTOR,
|
||||
VECTOR INDEX idx1(c2)
|
||||
WITH (lib=vsag, type=sindi, distance=inner_product)
|
||||
);
|
||||
|
||||
INSERT INTO t1 VALUES(1, '{1:0.1, 2:0.2, 3:0.3}');
|
||||
INSERT INTO t1 VALUES(2, '{3:0.3, 2:0.2, 4:0.4}');
|
||||
INSERT INTO t1 VALUES(3, '{3:0.3, 4:0.4, 5:0.5}');
|
||||
INSERT INTO t1 VALUES(4, '{5:0.5, 4:0.4, 6:0.6}');
|
||||
INSERT INTO t1 VALUES(5, '{5:0.5, 6:0.6, 7:0.7}');
|
||||
|
||||
SELECT * FROM t1
|
||||
ORDER BY negative_inner_product(c2, '{3:0.3, 4:0.4}')
|
||||
APPROXIMATE LIMIT 4;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+---------------------+
|
||||
| c1 | c2 |
|
||||
+----+---------------------+
|
||||
| 2 | {2:0.2,3:0.3,4:0.4} |
|
||||
| 3 | {3:0.3,4:0.4,5:0.5} |
|
||||
| 4 | {4:0.4,5:0.5,6:0.6} |
|
||||
| 1 | {1:0.1,2:0.2,3:0.3} |
|
||||
+----+---------------------+
|
||||
```
|
||||
|
||||
#### Use query parameters
|
||||
|
||||
```sql
|
||||
SELECT *, negative_inner_product(c2, '{3:0.3, 4:0.4}')
|
||||
AS score FROM t1
|
||||
ORDER BY score APPROXIMATE LIMIT 4
|
||||
PARAMETERS(drop_ratio_search=0.5);
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+---------------------+---------------------+
|
||||
| c1 | c2 | score |
|
||||
+----+---------------------+---------------------+
|
||||
| 4 | {4:0.4,5:0.5,6:0.6} | -0.1600000113248825 |
|
||||
| 3 | {3:0.3,4:0.4,5:0.5} | -0.2500000149011612 |
|
||||
| 2 | {2:0.2,3:0.3,4:0.4} | -0.2500000149011612 |
|
||||
+----+---------------------+---------------------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
## Index monitoring and maintenance
|
||||
|
||||
In-memory sparse vector indexes provide monitoring views and support using the `DBMS_VECTOR` system package for index maintenance, including incremental refresh and full rebuild. The usage is the same as that for dense indexes.
|
||||
|
||||
## Related documentation
|
||||
|
||||
* For detailed information about sparse vector data types, see [Vector data type](../../700.vector-search-reference/100.vector-data-type.md).
|
||||
* For detailed information about vector distance functions, see [Vector functions](../../250.vector-function.md).
|
||||
* For monitoring and maintenance of dense vector indexes, see [Vector index monitoring/maintenance](../200.dense-vector-index.md).
|
||||
* For index memory estimation and actual usage query of vector indexes, see [Index memory estimation and actual usage query](../200.dense-vector-index.md).
|
||||
@@ -0,0 +1,611 @@
|
||||
---
|
||||
|
||||
slug: /vector-function
|
||||
---
|
||||
|
||||
# Use SQL functions
|
||||
|
||||
This topic describes the vector functions supported by seekdb and the considerations for using them.
|
||||
|
||||
## Considerations
|
||||
|
||||
* Vectors with different dimensions are not allowed to perform the following operations. An error `different vector dimensions %d and %d` is returned.
|
||||
|
||||
* When the result exceeds the floating-point number range, an error `value out of range: overflow / underflow` is returned.
|
||||
|
||||
* Dense vector indexes support L2, inner product, and cosine distance as index distance algorithms. Memory-based sparse vector indexes support inner product as the distance algorithm. For details, see [Create vector indexes](200.vector-index/200.dense-vector-index.md).
|
||||
|
||||
* Vector index search supports calling the `L2_distance`, `Cosine_distance`, and `Inner_product` distance functions in this document.
|
||||
|
||||
## Distance functions
|
||||
|
||||
Distance functions are used to calculate the distance between two vectors. The calculation method varies depending on the distance algorithm used.
|
||||
|
||||
### L2_distance
|
||||
|
||||
Euclidean distance reflects the distance between the coordinates of the compared vectors -- essentially the straight-line distance between two vectors. It is calculated by applying the Pythagorean theorem to vector coordinates:
|
||||
|
||||
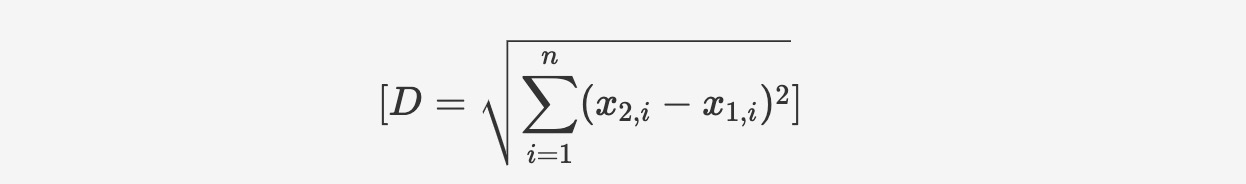
|
||||
|
||||
The function syntax is as follows:
|
||||
|
||||
```sql
|
||||
l2_distance(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1(c1 vector(3));
|
||||
INSERT INTO t1 VALUES('[1,2,3]');
|
||||
SELECT l2_distance(c1, [1,2,3]), l2_distance([1,2,3],[1,1,1]), l2_distance('[1,1,1]','[1,2,3]') FROM t1;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+--------------------------+------------------------------+----------------------------------+
|
||||
| l2_distance(c1, [1,2,3]) | l2_distance([1,2,3],[1,1,1]) | l2_distance('[1,1,1]','[1,2,3]') |
|
||||
+--------------------------+------------------------------+----------------------------------+
|
||||
| 0 | 2.23606797749979 | 2.23606797749979 |
|
||||
+--------------------------+------------------------------+----------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### L2_squared
|
||||
|
||||
L2 Squared distance is the square of the Euclidean distance (L2 Distance). It omits the square root operation in the Euclidean distance formula, thereby reducing computational cost while maintaining the relative order of distances. The calculation method is as follows:
|
||||
|
||||
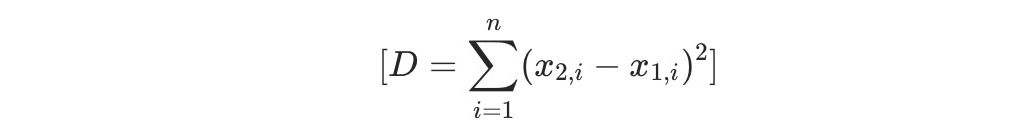
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
l2_squared(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1(c1 vector(3));
|
||||
INSERT INTO t1 VALUES('[1,2,3]');
|
||||
SELECT l2_squared(c1, [1,2,3]), l2_squared([1,2,3],[1,1,1]), l2_squared('[1,1,1]','[1,2,3]') FROM t1;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+-------------------------+-----------------------------+---------------------------------+
|
||||
| l2_squared(c1, [1,2,3]) | l2_squared([1,2,3],[1,1,1]) | l2_squared('[1,1,1]','[1,2,3]') |
|
||||
+-------------------------+-----------------------------+---------------------------------+
|
||||
| 0 | 5 | 5 |
|
||||
+-------------------------+-----------------------------+---------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### L1_distance
|
||||
|
||||
The Manhattan distance is used to calculate the sum of absolute axis distances between two points in a standard coordinate system. The calculation formula is as follows:
|
||||
|
||||
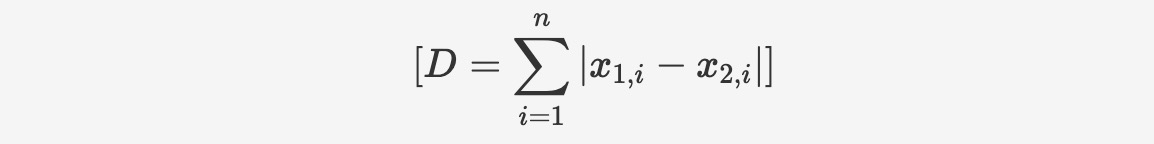
|
||||
|
||||
The function syntax is as follows:
|
||||
|
||||
```sql
|
||||
l1_distance(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t2(c1 vector(3));
|
||||
INSERT INTO t2 VALUES('[1,2,3]');
|
||||
INSERT INTO t2 VALUES('[1,1,1]');
|
||||
SELECT l1_distance(c1, [1,2,3]) FROM t2;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+--------------------------+
|
||||
| l1_distance(c1, [1,2,3]) |
|
||||
+--------------------------+
|
||||
| 0 |
|
||||
| 3 |
|
||||
+--------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
### Cosine_distance
|
||||
|
||||
Cosine similarity measures the angular difference between two vectors and reflects their directional similarity, regardless of their lengths (magnitude). The value range of cosine similarity is `[-1, 1]`, where `1` indicates vectors in exactly the same direction, `0` indicates orthogonality, and `-1` indicates completely opposite directions.
|
||||
|
||||
The calculation method for cosine similarity is as follows:
|
||||
|
||||
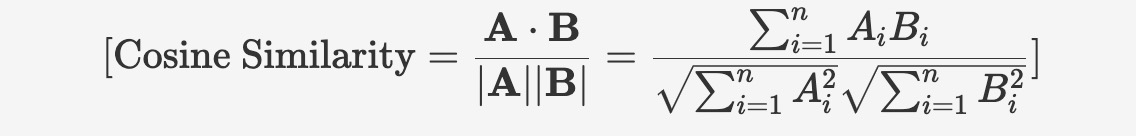
|
||||
|
||||
Since cosine similarity closer to 1 indicates greater similarity, cosine distance (or cosine dissimilarity) is sometimes used as a measure of distance between vectors. Cosine distance can be calculated by subtracting cosine similarity from 1:
|
||||
|
||||
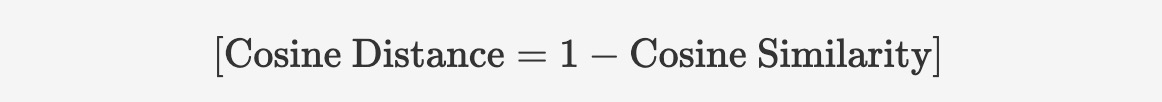
|
||||
|
||||
The value range of cosine distance is `[0, 2]`, where `0` indicates exactly the same direction (no distance) and `2` indicates completely opposite directions.
|
||||
|
||||
The function syntax is as follows:
|
||||
|
||||
```sql
|
||||
cosine_distance(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t3(c1 vector(3));
|
||||
INSERT INTO t3 VALUES('[1,2,3]');
|
||||
INSERT INTO t3 VALUES('[1,2,1]');
|
||||
SELECT cosine_distance(c1, [1,2,3]) FROM t3;
|
||||
```
|
||||
|
||||
```shell
|
||||
+------------------------------+
|
||||
| cosine_distance(c1, [1,2,3]) |
|
||||
+------------------------------+
|
||||
| 0 |
|
||||
| 0.12712843905603044 |
|
||||
+------------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
### Inner_product
|
||||
|
||||
The inner product, also known as the dot product or scalar product, represents a type of multiplication between two vectors. In geometric terms, the inner product indicates the direction and magnitude relationship between two vectors. The calculation method for the inner product is as follows:
|
||||
|
||||
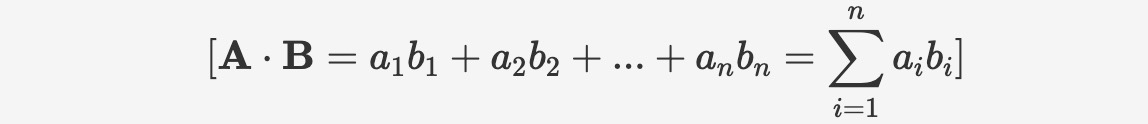
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
inner_product(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
* For sparse vectors using this function, one parameter can be a string in sparse vector format, such as `c2,'{1:2.4}'`. Two parameters cannot both be strings.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Dense vector example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t4(c1 vector(3));
|
||||
INSERT INTO t4 VALUES('[1,2,3]');
|
||||
INSERT INTO t4 VALUES('[1,2,1]');
|
||||
SELECT inner_product(c1, [1,2,3]) FROM t4;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----------------------------+
|
||||
| inner_product(c1, [1,2,3]) |
|
||||
+----------------------------+
|
||||
| 14 |
|
||||
| 8 |
|
||||
+----------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
Sparse vector example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t4(c1 INT, c2 SPARSEVECTOR, c3 SPARSEVECTOR);
|
||||
INSERT INTO t4 VALUES(1, '{1:1.1, 2:2.2}', '{1:2.4}');
|
||||
INSERT INTO t4 VALUES(2, '{1:1.5, 3:3.6}', '{4:4.5}');
|
||||
SELECT inner_product(c2,c3) FROM t4;
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----------------------+
|
||||
| inner_product(c2,c3) |
|
||||
+----------------------+
|
||||
| 2.640000104904175 |
|
||||
| 0 |
|
||||
+----------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
### Vector_distance
|
||||
|
||||
The vector_distance function calculates the distance between two vectors. You can specify parameters to select different distance algorithms.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
vector_distance(vector v1, vector v2 [, string metric])
|
||||
```
|
||||
|
||||
The `vector v1/v2` parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The `metric` parameter is used to specify the distance algorithm. Options:
|
||||
|
||||
* If not specified, the default algorithm is `euclidean`.
|
||||
|
||||
* If specified, the only valid values are:
|
||||
|
||||
* `euclidean`. Represents Euclidean distance, same as L2_distance.
|
||||
|
||||
* `manhattan`. Represents Manhattan distance, same as L1_distance.
|
||||
|
||||
* `cosine`. Represents cosine distance, same as Cosine_distance.
|
||||
|
||||
* `dot`. Represents inner product, same as Inner_product.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t5(c1 vector(3));
|
||||
INSERT INTO t5 VALUES('[1,2,3]');
|
||||
INSERT INTO t5 VALUES('[1,2,1]');
|
||||
SELECT vector_distance(c1, [1,2,3], euclidean) FROM t5;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+-----------------------------------------+
|
||||
| vector_distance(c1, [1,2,3], euclidean) |
|
||||
+-----------------------------------------+
|
||||
| 0 |
|
||||
| 2 |
|
||||
+-----------------------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
## Arithmetic functions
|
||||
|
||||
Arithmetic functions provide element-wise addition (+), subtraction (-), and multiplication (*) operations between vector types and vector types, single-level array types, and special string types, as well as between single-level array types and single-level array types, and special string types. The calculation method is element-wise, as shown for addition:
|
||||
|
||||
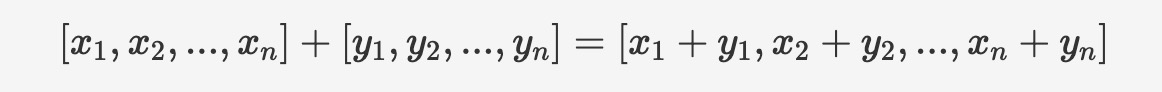
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
v1 + v2
|
||||
v1 - v2
|
||||
v1 * v2
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`). **Note**: Two parameters cannot both be string types. At least one parameter must be a vector or single-level array type.
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* When at least one of the two parameters is a vector type, the return value is of the same vector type as the vector parameter.
|
||||
|
||||
* When both parameters are single-level array types, the return value is of the `array(float)` type.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t6(c1 vector(3));
|
||||
INSERT INTO t6 VALUES('[1,2,3]');
|
||||
SELECT [1,2,3] + '[1.12,1000.0001, -1.2222]', c1 - [1,2,3] FROM t6;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------------------------------------+--------------+
|
||||
| [1,2,3] + '[1.12,1000.0001, -1.2222]' | c1 - [1,2,3] |
|
||||
+---------------------------------------+--------------+
|
||||
| [2.12,1002,1.7778] | [0,0,0] |
|
||||
+---------------------------------------+--------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## Comparison functions
|
||||
|
||||
Comparison functions provide comparison calculations between vector types and vector types, single-level array types, and special string types, including the comparison operators `=`, `!=`, `>`, `>=`, `<`, and `<=`. The calculation method is element-wise dictionary order comparison.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
v1 = v2
|
||||
v1 != v2
|
||||
v1 > v2
|
||||
v1 < v2
|
||||
v1 >= v2
|
||||
v1 <= v2
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
:::tip
|
||||
One of the two parameters must be a vector type.
|
||||
:::
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is of the bool type.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t7(c1 vector(3));
|
||||
INSERT INTO t7 VALUES('[1,2,3]');
|
||||
SELECT c1 = '[1,2,3]' FROM t7;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----------------+
|
||||
| c1 = '[1,2,3]' |
|
||||
+----------------+
|
||||
| 1 |
|
||||
+----------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## Aggregate functions
|
||||
|
||||
:::tip
|
||||
Vector columns cannot be used as GROUP BY conditions, and DISTINCT is not supported.
|
||||
:::
|
||||
|
||||
### Sum
|
||||
|
||||
The Sum function is used to calculate the sum of vectors in a vector column of a table, using element-wise accumulation to obtain the sum vector.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
sum(vector v1)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Only the vector type is supported.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `sum (vector)` value.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t8(c1 vector(3));
|
||||
INSERT INTO t8 VALUES('[1,2,3]');
|
||||
SELECT sum(c1) FROM t8;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------+
|
||||
| sum(c1) |
|
||||
+---------+
|
||||
| [1,2,3] |
|
||||
+---------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Avg
|
||||
|
||||
The Avg function is used to calculate the average of vectors in a vector column of a table.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
avg(vector v1)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Only the vector type is supported.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is an `avg (vector)` value.
|
||||
|
||||
* `NULL` rows in the vector column are not counted.
|
||||
|
||||
* When the input parameter is empty, the output is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t9(c1 vector(3));
|
||||
INSERT INTO t9 VALUES('[1,2,3]');
|
||||
SELECT avg(c1) FROM t9;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------+
|
||||
| avg(c1) |
|
||||
+---------+
|
||||
| [1,2,3] |
|
||||
+---------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## Other common vector functions
|
||||
|
||||
### Vector_norm
|
||||
|
||||
The Vector_norm function calculates the Euclidean norm (or length) of a vector, which represents the Euclidean distance between the vector and the origin. The calculation formula is as follows:
|
||||
|
||||
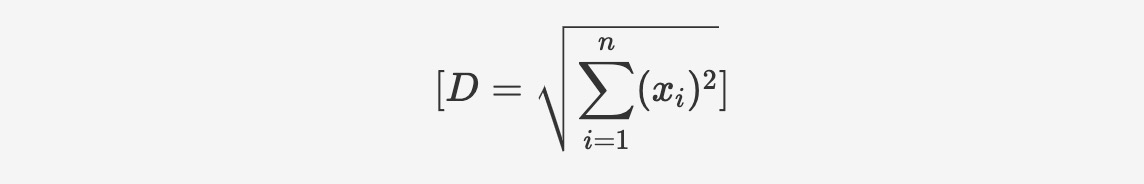
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
vector_norm(vector v1)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `norm(double)` modulus value.
|
||||
|
||||
* If the parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t10(c1 vector(3));
|
||||
INSERT INTO t10 VALUES('[1,2,3]');
|
||||
SELECT vector_norm(c1),vector_norm([1,2,3]) FROM t10;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+--------------------+----------------------+
|
||||
| vector_norm(c1) | vector_norm([1,2,3]) |
|
||||
+--------------------+----------------------+
|
||||
| 3.7416573867739413 | 3.7416573867739413 |
|
||||
+--------------------+----------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Vector_dims
|
||||
|
||||
The Vector_dims function is used to return the vector dimension.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
vector_dims(vector v1)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `dims(int64)` dimension value.
|
||||
|
||||
* If the parameter is `NULL`, an error is returned.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t11(c1 vector(3));
|
||||
INSERT INTO t11 VALUES('[1,2,3]');
|
||||
INSERT INTO t11 VALUES('[1,1,1]');
|
||||
SELECT vector_dims(c1), vector_dims('[1,2,3]') FROM t11;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+-----------------+------------------------+
|
||||
| vector_dims(c1) | vector_dims('[1,2,3]') |
|
||||
+-----------------+------------------------+
|
||||
| 3 | 3 |
|
||||
| 3 | 3 |
|
||||
+-----------------+------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
@@ -0,0 +1,232 @@
|
||||
---
|
||||
|
||||
slug: /vector-similarity-search
|
||||
---
|
||||
|
||||
# Vector similarity search
|
||||
|
||||
Vector similarity search, also known as nearest neighbor search, is a search method based on distance metrics in vector space. Its core objective is to find the set of vectors most similar to a given query vector. Although specific distance metrics are used during computation, the final output is the Top K nearest vectors, sorted in ascending order of distance.
|
||||
|
||||
This topic describes two vector search methods in seekdb: exact nearest neighbor search based on full-scan and approximate nearest neighbor search based on vector index. It also provides examples to illustrate how to use these methods.
|
||||
|
||||
:::tip
|
||||
For readability, this document refers to vector nearest neighbor search as "vector search," exact nearest neighbor search as "exact search," and approximate nearest neighbor search as "approximate search."
|
||||
:::
|
||||
|
||||
## Perform exact search
|
||||
|
||||
Exact search uses a full scan strategy, calculating the distance between the query vector and all vectors in the dataset to perform an exact search. This method ensures complete accuracy of the search results, but because it requires calculating the distance for all data, the search performance decreases significantly as the dataset grows.
|
||||
|
||||
When executing an exact search, the system calculates and compares the distances between the query vector vₑ and all other vectors in the vector space. After completing the full distance calculations, the system selects the k vectors closest to the query as the search results.
|
||||
|
||||
### Example: Euclidean search
|
||||
|
||||
Euclidean similarity search is used to retrieve the top-k vectors in the vector space that are closest to the query vector, using Euclidean distance as the metric. The following example demonstrates how to use exact search to retrieve the top 5 vectors from a table that are closest to the query vector:
|
||||
|
||||
```sql
|
||||
-- Create a test table
|
||||
CREATE TABLE t1 (
|
||||
id INT PRIMARY KEY,
|
||||
c1 VECTOR(3)
|
||||
);
|
||||
|
||||
-- Insert data
|
||||
INSERT INTO t1 VALUES
|
||||
(1, '[0.1, 0.2, 0.3]'),
|
||||
(2, '[0.2, 0.3, 0.4]'),
|
||||
(3, '[0.3, 0.4, 0.5]'),
|
||||
(4, '[0.4, 0.5, 0.6]'),
|
||||
(5, '[0.5, 0.6, 0.7]'),
|
||||
(6, '[0.6, 0.7, 0.8]'),
|
||||
(7, '[0.7, 0.8, 0.9]'),
|
||||
(8, '[0.8, 0.9, 1.0]'),
|
||||
(9, '[0.9, 1.0, 0.1]'),
|
||||
(10, '[1.0, 0.1, 0.2]');
|
||||
|
||||
-- Perform an exact search
|
||||
SELECT c1
|
||||
FROM t1
|
||||
ORDER BY l2_distance(c1, '[0.1, 0.2, 0.3]') LIMIT 5;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------------+
|
||||
| c1 |
|
||||
+---------------+
|
||||
| [0.1,0.2,0.3] |
|
||||
| [0.2,0.3,0.4] |
|
||||
| [0.3,0.4,0.5] |
|
||||
| [0.4,0.5,0.6] |
|
||||
| [0.5,0.6,0.7] |
|
||||
+---------------+
|
||||
5 rows in set
|
||||
```
|
||||
|
||||
### Analyze the execution plan
|
||||
|
||||
Obtain the execution plan of the preceding example:
|
||||
|
||||
```sql
|
||||
EXPLAIN SELECT c1
|
||||
FROM t1
|
||||
ORDER BY l2_distance(c1, '[0.1, 0.2, 0.3]') LIMIT 5;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------------------------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+---------------------------------------------------------------------------------------------+
|
||||
| ================================================= |
|
||||
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
|
||||
| ------------------------------------------------- |
|
||||
| |0 |TOP-N SORT | |5 |3 | |
|
||||
| |1 |└─TABLE FULL SCAN|t1 |10 |3 | |
|
||||
| ================================================= |
|
||||
| Outputs & filters: |
|
||||
| ------------------------------------- |
|
||||
| 0 - output([t1.c1]), filter(nil), rowset=16 |
|
||||
| sort_keys([l2_distance(t1.c1, cast('[0.1, 0.2, 0.3]', ARRAY(18, -1))), ASC]), topn(5) |
|
||||
| 1 - output([t1.c1]), filter(nil), rowset=16 |
|
||||
| access([t1.c1]), partitions(p0) |
|
||||
| is_index_back=false, is_global_index=false, |
|
||||
| range_key([t1.id]), range(MIN ; MAX)always true |
|
||||
+---------------------------------------------------------------------------------------------+
|
||||
14 rows in set
|
||||
```
|
||||
|
||||
The analysis is as follows:
|
||||
|
||||
* Execution method:
|
||||
* The full-table scan method is used, which requires traversing all data in the table. The `TABLE FULL SCAN` operation in the execution plan scans all data in the `t1` table.
|
||||
* The system calculates the vector distance for each record and then sorts the records by distance. The `TOP-N SORT` operation in the execution plan calculates the vector distance using the `l2_distance` function and sorts the records by distance in ascending order.
|
||||
* The system returns the five records with the smallest distances. The `topn(5)` setting in the execution plan indicates that only the first five records of the sorted list are returned.
|
||||
|
||||
* Performance characteristics:
|
||||
* Advantages: The search results are completely accurate and ensure that the true nearest neighbors are returned.
|
||||
* Disadvantages: The system must scan all data in the table and calculate the distance between all vectors, leading to a significant drop in performance as the data volume increases.
|
||||
|
||||
* Applicable scenarios:
|
||||
* Scenarios with a small amount of data.
|
||||
* Scenarios where high result accuracy is required.
|
||||
* Scenarios where real-time queries are not suitable for large datasets.
|
||||
|
||||
## Perform approximate search by using vector indexes
|
||||
|
||||
Vector index search uses an approximate nearest neighbor (ANN) strategy, accelerating the search process through pre-built index structures. While it cannot guarantee 100% result accuracy, it can significantly improve search performance, allowing for a good balance between accuracy and efficiency in practical applications.
|
||||
|
||||
### Example: Approximate search by using the HNSW index
|
||||
|
||||
```sql
|
||||
-- Create a HNSW vector index with the table.
|
||||
CREATE TABLE t2 (
|
||||
id INT PRIMARY KEY,
|
||||
vec VECTOR(3),
|
||||
VECTOR INDEX idx(vec) WITH (distance=l2, type=hnsw, lib=vsag)
|
||||
);
|
||||
|
||||
-- Insert test data
|
||||
INSERT INTO t2 VALUES
|
||||
(1, '[0.1, 0.2, 0.3]'),
|
||||
(2, '[0.2, 0.3, 0.4]'),
|
||||
(3, '[0.3, 0.4, 0.5]'),
|
||||
(4, '[0.4, 0.5, 0.6]'),
|
||||
(5, '[0.5, 0.6, 0.7]'),
|
||||
(6, '[0.6, 0.7, 0.8]'),
|
||||
(7, '[0.7, 0.8, 0.9]'),
|
||||
(8, '[0.8, 0.9, 1.0]'),
|
||||
(9, '[0.9, 1.0, 0.1]'),
|
||||
(10, '[1.0, 0.1, 0.2]');
|
||||
|
||||
-- Perform approximate search and return the 5 most similar data records
|
||||
SELECT id, vec
|
||||
FROM t2
|
||||
ORDER BY l2_distance(vec, '[0.1, 0.2, 0.3]')
|
||||
APPROXIMATE
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
The return result is as follows. The result is the same as that of the exact search because the data volume is small:
|
||||
|
||||
```shell
|
||||
+------+---------------+
|
||||
| id | vec |
|
||||
+------+---------------+
|
||||
| 1 | [0.1,0.2,0.3] |
|
||||
| 2 | [0.2,0.3,0.4] |
|
||||
| 3 | [0.3,0.4,0.5] |
|
||||
| 4 | [0.4,0.5,0.6] |
|
||||
| 5 | [0.5,0.6,0.7] |
|
||||
+------+---------------+
|
||||
5 rows in set
|
||||
```
|
||||
|
||||
### Execution plan analysis
|
||||
|
||||
Obtain the execution plan of the preceding example:
|
||||
|
||||
```sql
|
||||
EXPLAIN SELECT id, vec
|
||||
FROM t2
|
||||
ORDER BY l2_distance(vec, '[0.1, 0.2, 0.3]')
|
||||
APPROXIMATE
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+--------------------------------------------------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+--------------------------------------------------------------------------------------------------------------------+
|
||||
| ==================================================== |
|
||||
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
|
||||
| ---------------------------------------------------- |
|
||||
| |0 |VECTOR INDEX SCAN|t2(idx)|10 |29 | |
|
||||
| ==================================================== |
|
||||
| Outputs & filters: |
|
||||
| ------------------------------------- |
|
||||
| 0 - output([t2.id], [t2.vec]), filter(nil), rowset=16 |
|
||||
| access([t2.id], [t2.vec]), partitions(p0) |
|
||||
| is_index_back=true, is_global_index=false, |
|
||||
| range_key([t2.__vid_1750162978114053], [t2.__type_17_1750162978114364]), range(MIN,MIN ; MAX,MAX)always true |
|
||||
+--------------------------------------------------------------------------------------------------------------------+
|
||||
11 rows in set
|
||||
```
|
||||
|
||||
The analysis is as follows:
|
||||
|
||||
* Execution method:
|
||||
* The vector index scan method is used, directly locating similar vectors through the pre-built HNSW index. The `VECTOR INDEX SCAN` operation in the execution plan uses the index `t2(idx)` for retrieval.
|
||||
* The graph structure of the index is used to quickly locate nearest neighbors without calculating the distance between all vectors. The `is_index_back=true` setting in the execution plan indicates that complete data is retrieved through index back-lookup.
|
||||
* The five records that the index considers to be the most similar are returned. The `output([t2.id], [t2.vec])` in the execution plan indicates that the id and vector data are returned.
|
||||
|
||||
* Performance characteristics:
|
||||
* Advantage: The search performance is high and remains stable as the data volume increases.
|
||||
* Disadvantage: A small amount of error may exist in the results, and 100% accuracy is not guaranteed.
|
||||
|
||||
* Applicable scenarios:
|
||||
* Real-time search for large-scale datasets.
|
||||
* Scenarios with high requirements for search performance.
|
||||
* Scenarios that can tolerate a small amount of result error.
|
||||
|
||||
## Summary
|
||||
|
||||
A comparison of the two search methods is as follows:
|
||||
|
||||
| Item | Exact search | Approximate search |
|
||||
|--------|----------------|----------------|
|
||||
| Execution method | Full-table scan (`TABLE FULL SCAN`) followed by sorting | Direct search through the vector index (`VECTOR INDEX SCAN`) |
|
||||
| Execution plan | Contains two operators: `TABLE FULL SCAN` and `TOP-N SORT` | Contains only one operator: `VECTOR INDEX SCAN` |
|
||||
| Performance characteristics | Requires full-table scan and sorting, and performance decreases significantly as the data volume increases | Directly locates target data through the index, and performance is stable |
|
||||
| Result accuracy | 100% accurate, ensuring real nearest neighbors are returned | Approximately accurate, with a small amount of error possible |
|
||||
| Applicable scenarios | Scenarios with small data volumes and high accuracy requirements | Scenarios with large-scale datasets and high performance requirements |
|
||||
|
||||
### References
|
||||
|
||||
* For more information about SQL functions, see [Use SQL functions](250.vector-function.md).
|
||||
* For more information about vector indexes and examples, see [Create vector indexes](200.vector-index/200.dense-vector-index.md).
|
||||
* To perform large-scale performance tests, we recommend that you use the [VectorDBBenchmark tool](700.vector-search-benchmark-test.md) to generate a test dataset to better compare the performance differences between exact search and approximate search.
|
||||
@@ -0,0 +1,127 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-benchmark-test
|
||||
---
|
||||
|
||||
# Benchmark testing with VectorDBBench
|
||||
|
||||
VectorDBBench is a benchmarking tool designed to provide benchmark test results for mainstream vector databases and cloud services. This topic explains how to use VectorDBBench to test the performance of seekdb vector database. Designed for ease of use, VectorDBBench allows you to easily replicate test results or test new systems.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* Deploy seekdb.
|
||||
* Install Python 3.11 or later. The following example uses Conda for installation:
|
||||
```bash
|
||||
# Download and install Conda
|
||||
mkdir -p ~/miniconda3
|
||||
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
|
||||
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
|
||||
rm ~/miniconda3/miniconda.sh
|
||||
|
||||
# Reopen your terminal and initialize Conda
|
||||
source ~/miniconda3/bin/activate
|
||||
conda init --all
|
||||
|
||||
# Create and initialize the Python environment required by VectorDBBench
|
||||
conda create -n vdb python=3.11
|
||||
conda activate vdb
|
||||
```
|
||||
* Connect to the database and optimize memory and query parameters for HNSW vector index searches:
|
||||
|
||||
```sql
|
||||
-- Set ob_vector_memory_limit_percentage to 30%.
|
||||
ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30;
|
||||
-- Set ob_query_timeout to 24 hours.
|
||||
SET GLOBAL ob_query_timeout = 86400000000;
|
||||
-- Set max_allowed_packet to 1 GB.
|
||||
SET GLOBAL max_allowed_packet=1073741824;
|
||||
-- Set ddl_thread_score and parallel_servers_target to configure parallelism when creating indexes
|
||||
ALTER SYSTEM SET ddl_thread_score = 8; -- Parallelism for DDL operations
|
||||
SET GLOBAL parallel_servers_target = 624; -- Number of parallel queries the database server can handle simultaneously
|
||||
```
|
||||
Here, `ob_vector_memory_limit_percentage = 30` is only an example value. Adjust it based on the database memory and workload.
|
||||
|
||||
## Recommended configuration
|
||||
|
||||
The recommended resource specifications for the database are as follows:
|
||||
|
||||
| Parameter | Value |
|
||||
|-------|----|
|
||||
| Memory | 64 GB |
|
||||
| CPU | 16 cores |
|
||||
|
||||
## Testing methods
|
||||
|
||||
### Clone the VectorDBBench code
|
||||
|
||||
:::tip
|
||||
We recommend that you deploy VectorDBBench and seekdb on separate servers to avoid CPU resource contention and improve the reliability of test results.
|
||||
:::
|
||||
|
||||
Clone the VectorDBBench test tool code to your local server.
|
||||
|
||||
```bash
|
||||
git clone https://github.com/zilliztech/VectorDBBench.git
|
||||
```
|
||||
|
||||
### Install dependencies
|
||||
|
||||
Go to the VectorDBBench directory and install the dependencies.
|
||||
|
||||
```bash
|
||||
cd VectorDBBench
|
||||
pip install .
|
||||
```
|
||||
|
||||
### Run the test
|
||||
|
||||
Run VectorDBBench. Two examples are provided here: HNSW index and IVF index.
|
||||
|
||||
#### HNSW index example
|
||||
|
||||
```bash
|
||||
# Replace $host, $port, and $user with the actual seekdb connection information.
|
||||
vectordbbench oceanbasehnsw --host $host --port $port --user $user --database test --m 16 --ef-construction 200 --ef-search 40 --k 10 --case-type Performance768D1M --index-type HNSW
|
||||
```
|
||||
|
||||
For more information about the parameters, run the following command:
|
||||
|
||||
```bash
|
||||
vectordbbench oceanbasehnsw --help
|
||||
```
|
||||
|
||||
Commonly used options are described as follows:
|
||||
|
||||
* `--num-concurrency`: Used to adjust the concurrency level. VectorDBBench executes vector queries with the specified concurrency and selects the highest QPS (Queries Per Second) as the final result.
|
||||
* `--skip-drop-old`/`--skip-load`: Skips the deletion of old data and the data loading step. After adding these two options to the command line, the command only performs vector query operations and does not delete old data or reload data.
|
||||
* `--k`: Specifies the number of top-k nearest neighbor results to return in a vector query.
|
||||
* `--ef-search`: HNSW query parameter that indicates the size of the candidate set during query.
|
||||
* `--index-type`: Specifies the index type. Currently supports `HNSW`, `HNSW_SQ`, and `HNSW_BQ`.
|
||||
|
||||
#### IVF index example
|
||||
|
||||
```bash
|
||||
vectordbbench oceanbaseivf --host $host --port $port --user $user --database test --nlist 1000 --sample_per_nlist 256 --ivf_nprobes 100 --case-type Performance768D1M --index-type IVF_FLAT
|
||||
```
|
||||
|
||||
Commonly used options are described as follows:
|
||||
|
||||
* `--sample_per_nlist`: The amount of data sampled per cluster center. Default value is `256`.
|
||||
* `--ivf_nprobes`: Used to set how many nearest cluster centers to search in this query when performing vector index queries. Default value is `8`. The larger the value, the higher the recall rate, but the search time also increases.
|
||||
* `--index-type`: Specifies the index type. Currently supports `IVF_FLAT`.
|
||||
|
||||
For more information about the parameters, run the following command:
|
||||
|
||||
```bash
|
||||
vectordbbench oceanbaseivf --help
|
||||
```
|
||||
|
||||
## FAQs
|
||||
|
||||
### Is it normal for the first test execution to be slow?
|
||||
|
||||
The first test execution requires downloading the required dataset from AWS S3 storage, which may take relatively longer. This is normal.
|
||||
|
||||
### Can I customize and modify the test code?
|
||||
|
||||
Yes, you can. If you customize and modify the test code, you need to run `pip install .` again before running the test.
|
||||
@@ -0,0 +1,61 @@
|
||||
---
|
||||
|
||||
slug: /vector-data-type
|
||||
---
|
||||
|
||||
# Overview of vector data types
|
||||
|
||||
seekdb provides vector data types to support AI vector search applications. By using vector data types, you can store and query an array of floating-point numbers, such as `[0.1, 0.3, -0.9, ...]`. Before using vector data, you need to be aware of the following:
|
||||
|
||||
* Both dense and sparse vector data are supported, and all data elements must be single-precision floating-point numbers.
|
||||
|
||||
* Element values in vector data cannot be NaN (not a number) or Inf (infinity); otherwise, a runtime error will be thrown.
|
||||
|
||||
* You must specify the vector dimension when creating a vector column, for example, `VECTOR(3)`.
|
||||
|
||||
* Creating dense/sparse vector indexes is supported. For details, see [vector index](../200.vector-index/200.dense-vector-index.md).
|
||||
|
||||
* Vector data in seekdb is stored in array form.
|
||||
|
||||
* Both dense and sparse vectors support [hybrid search](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001970893).
|
||||
|
||||
## Syntax
|
||||
|
||||
A dense vector value can contain any number of floating-point numbers up to 16,000. The syntax is as follows:
|
||||
|
||||
```sql
|
||||
-- Dense vector
|
||||
'[<float>, <float>, ...]'
|
||||
```
|
||||
|
||||
A sparse vector is based on the MAP data type and contains unordered key-value pairs. The syntax is as follows:
|
||||
|
||||
```sql
|
||||
-- Sparse vector
|
||||
'{<uint:float>, <uint:float>...}'
|
||||
```
|
||||
|
||||
Examples of creating vector columns and indexes are as follows:
|
||||
|
||||
```sql
|
||||
-- Create a dense vector column and index
|
||||
CREATE TABLE t1(
|
||||
c1 INT,
|
||||
c2 VECTOR(3),
|
||||
PRIMARY KEY(c1),
|
||||
VECTOR INDEX idx1(c2) WITH (distance=L2, type=hnsw)
|
||||
);
|
||||
```
|
||||
|
||||
```sql
|
||||
-- Create a sparse vector column
|
||||
CREATE TABLE t2 (
|
||||
c1 INT,
|
||||
c2 SPARSEVECTOR
|
||||
);
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Create vector indexes](../200.vector-index/200.dense-vector-index.md)
|
||||
* [Use SQL functions](../250.vector-function.md)
|
||||
@@ -0,0 +1,391 @@
|
||||
---
|
||||
|
||||
slug: /vector-sdk-refer
|
||||
---
|
||||
|
||||
# Compatibility
|
||||
|
||||
This topic describes the data model mappings, SDK interface compatibility, and concept mappings between seekdb's vector search feature and Milvus.
|
||||
|
||||
## Concept mappings
|
||||
|
||||
To help users familiar with Milvus quickly get started with seekdb's vector storage capabilities, we analyze the similarities and differences between the two systems and provide a mapping of related concepts.
|
||||
|
||||
### Data models
|
||||
|
||||
| **Data model layer** | **Milvus** | **seekdb** | **Description** |
|
||||
|------------|---------|-----------|-----------|
|
||||
| First layer | Shards | Partition | Milvus specifies partition rules by setting some columns as `partition_key` in the schema definition.<br/>seekdb supports range/range columns, list/list columns, hash, key, and subpartitioning strategies. |
|
||||
| Second layer | Partitions | ≈Tablet | Milvus enhances read performance by chunking the same shard (shards are usually partitioned by primary key) based on other columns.<br />seekdb implements this by sorting keys within a partition. |
|
||||
| Third layer | Segments | MemTable+SSTable | Both have a minor compaction mechanism. |
|
||||
|
||||
### SDKs
|
||||
|
||||
This section introduces the conceptual differences between seekdb's vector storage SDK (pyobvector) and Milvus's SDK (pymilvus).
|
||||
|
||||
pyobvector supports two usage modes:
|
||||
|
||||
1. pymilvus MilvusClient lightweight compatible mode: This mode is compatible with common interfaces of Milvus clients. Users familiar with Milvus can easily use this mode without concept mapping.
|
||||
|
||||
2. SQLAlchemy extension mode: This mode can be used as a vector feature extension of python SQLAlchemy, retaining the operation mode of a relational database. Concept mapping is required.
|
||||
|
||||
For more information about pyobvector's APIs, see [pyobvector Python SDK API reference](900.vector-search-supported-clients-and-languages/200.vector-pyobvector.md).
|
||||
|
||||
The following table describes the concept mappings between pyobvector's SQLAlchemy extension mode and pymilvus:
|
||||
|
||||
| **pymilvus** | **pyobvector** | **Description** |
|
||||
|---------|------------|---------------|
|
||||
| Database | Database | Database |
|
||||
| Collection | Table | Table |
|
||||
| Field | Column | Column |
|
||||
| Primary Key | Primary Key | Primary key |
|
||||
| Vector Field | Vector Column | Vector column |
|
||||
| Index | Index | Index |
|
||||
| Partition | Partition | Partition |
|
||||
| DataType | DataType | Data type |
|
||||
| Metric Type | Distance Function | Distance function |
|
||||
| Search | Query | Query |
|
||||
| Insert | Insert | Insert |
|
||||
| Delete | Delete | Delete |
|
||||
| Update | Update | Update |
|
||||
| Batch | Batch | Batch operations |
|
||||
| Transaction | Transaction | Transaction |
|
||||
| NONE | Not supported| NULL value |
|
||||
| BOOL | Boolean | Corresponds to the MySQL TINYINT type |
|
||||
| INT8 | Boolean | Corresponds to the MySQL TINYINT type |
|
||||
| INT16 | SmallInteger | Corresponds to the MySQL SMALLINT type |
|
||||
| INT32 | Integer | Corresponds to the MySQL INT type |
|
||||
| INT64 | BigInteger | Corresponds to the MySQL BIGINT type |
|
||||
| FLOAT | Float | Corresponds to the MySQL FLOAT type |
|
||||
| DOUBLE | Double | Corresponds to the MySQL DOUBLE type |
|
||||
| STRING | LONGTEXT | Corresponds to the MySQL LONGTEXT type |
|
||||
| VARCHAR | STRING | Corresponds to the MySQL VARCHAR type |
|
||||
| JSON | JSON | For differences and similarities in JSON operations, see [pyobvector Python SDK API reference](900.vector-search-supported-clients-and-languages/200.vector-pyobvector.md). |
|
||||
| FLOAT_VECTOR | VECTOR | Vector type |
|
||||
| BINARY_VECTOR | Not supported | |
|
||||
| FLOAT16_VECTOR | Not supported | |
|
||||
| BFLOAT16_VECTOR | Not supported | |
|
||||
| SPARSE_FLOAT_VECTOR | Not supported | |
|
||||
| dynamic_field | Not needed | The hidden `$meta` metadata column in Milvus.<br/>In seekdb, you can explicitly create a JSON-type column. |
|
||||
|
||||
## Compatibility with Milvus
|
||||
|
||||
### Milvus SDK
|
||||
|
||||
Except `load_collection()`, `release_collection()`, and `close()`, which are supported through SQLAlchemy, all operations listed in the following tables are supported.
|
||||
|
||||
**Collection operations**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| create_collection() | Creates a vector table based on the given schema. |
|
||||
| get_collection_stats() | Queries table statistics, such as the number of rows. |
|
||||
| describe_collection() | Provides detailed metadata of a vector table. |
|
||||
| has_collection() | Checks whether a table exists. |
|
||||
| list_collections() | Lists existing tables. |
|
||||
| drop_collection() | Drops a table. |
|
||||
|
||||
**Field and schema definition**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| create_schema() | Creates a schema in memory and adds column definitions. |
|
||||
| add_field() | The call sequence is: create_schema->add_field->...->add_field<br/>You can also manually build a FieldSchema list and then use the CollectionSchema constructor to create a schema. |
|
||||
|
||||
**Vector indexes**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| list_indexes() | Lists all indexes. |
|
||||
| create_index() | Supports creating multiple vector indexes in a single call. First, use prepare_index_params to initialize an index parameter list object, call add_index multiple times to set multiple index parameters, and finally call create_index to create the indexes. |
|
||||
| drop_index() | Drops a vector index. |
|
||||
| describe_index() | Gets the metadata (schema) of an index. |
|
||||
|
||||
**Vector indexes**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| search() | ANN query interface:<ul><li>collection_name: the table name</li><li>data: the query vectors</li><li>filter: filtering operation, equivalent to `WHERE`</li><li>limit: top K</li><li>output_fields: projected columns, equivalent to `SELECT`</li><li>partition_names: partition names (not supported in Milvus Lite)</li><li>anns_field: the index column name</li><li>search_params: vector distance function name and index algorithm-related parameters</li></ul> |
|
||||
| query() | Point query with filter, namely `SELECT ... WHERE ids IN (..., ...) AND <filters>`. |
|
||||
| get() | Point query without filter, namely `SELECT ... WHERE ids IN (..., ...)`. |
|
||||
| delete() | Deletes a group of vectors, `DELETE FROM ... WHERE ids IN (..., ...)`. |
|
||||
| insert() | Inserts a group of vectors. |
|
||||
| upsert() | Insert with update on primary key conflict. |
|
||||
|
||||
**Collection metadata synchronization**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| load_collection() | Loads the table structure from the database to the Python application memory, enabling the application to operate the database table in an object-oriented manner. This is a standard feature of an object-relational mapping (ORM) framework. |
|
||||
| release_collection() | Releases the loaded table structure from the Python application memory and releases related resources. This is a standard feature of an ORM framework for memory management. |
|
||||
| close() | Closes the database connection and releases related resources. This is a standard feature of an ORM framework. |
|
||||
|
||||
### pymilvus
|
||||
|
||||
#### Data model
|
||||
|
||||
The data model of Milvus comprises three levels: Shards->Partitions->Segments. Compatibility with seekdb is described as follows:
|
||||
|
||||
* Shards correspond to seekdb's Partition concept.
|
||||
|
||||
* Partitions currently have no corresponding concept in seekdb.
|
||||
|
||||
* Milvus allows you to partition a shard into blocks by other columns to improve read performance (shards are usually partitioned by primary key). seekdb implements this by sorting by primary key within a partition.
|
||||
|
||||
* Segments are similar to [MemTable](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001973721) + [SSTable](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001973722).
|
||||
|
||||
#### Milvus Lite API compatibility
|
||||
|
||||
##### collection operations
|
||||
|
||||
1. Milvus create_collection():
|
||||
|
||||
```python
|
||||
create_collection(
|
||||
collection_name: str,
|
||||
dimension: int,
|
||||
primary_field_name: str = "id",
|
||||
id_type: str = DataType,
|
||||
vector_field_name: str = "vector",
|
||||
metric_type: str = "COSINE",
|
||||
auto_id: bool = False,
|
||||
timeout: Optional[float] = None,
|
||||
schema: Optional[CollectionSchema] = None, # Used for custom setup
|
||||
index_params: Optional[IndexParams] = None, # Used for custom setup
|
||||
**kwargs,
|
||||
) -> None
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* collection_name: compatible, corresponds to table_name.
|
||||
|
||||
* dimension: compatible, vector(dim).
|
||||
|
||||
* primary_field_name: compatible, the primary key column name.
|
||||
|
||||
* id_type: compatible, the primary key column type.
|
||||
|
||||
* vector_field_name: compatible, the vector column name.
|
||||
|
||||
* auto_id: compatible, auto increment.
|
||||
|
||||
* timeout: compatible, seekdb supports it through hint.
|
||||
|
||||
* schema: compatible.
|
||||
|
||||
* index_params: compatible.
|
||||
|
||||
2. Milvus get_collection_stats():
|
||||
|
||||
```python
|
||||
get_collection_stats(
|
||||
collection_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> Dict
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* API is compatible.
|
||||
|
||||
* Return value is compatible: `{ 'row_count': ... }`.
|
||||
|
||||
3. Milvus has_collection():
|
||||
|
||||
```python
|
||||
has_collection(
|
||||
collection_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> Bool
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus has_collection().
|
||||
|
||||
4. Milvus drop_collection():
|
||||
|
||||
```python
|
||||
drop_collection(collection_name: str) -> None
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus drop_collection().
|
||||
|
||||
5. Milvus rename_collection():
|
||||
|
||||
```python
|
||||
rename_collection(
|
||||
old_name: str,
|
||||
new_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> None
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus rename_collection().
|
||||
|
||||
##### Schema-related
|
||||
|
||||
1. Milvus create_schema():
|
||||
|
||||
```python
|
||||
create_schema(
|
||||
auto_id: bool,
|
||||
enable_dynamic_field: bool,
|
||||
primary_field: str,
|
||||
partition_key_field: str,
|
||||
) -> CollectionSchema
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* auto_id: whether the primary key column is auto-increment, compatible.
|
||||
|
||||
* primary_field & partition_key_field: compatible.
|
||||
|
||||
2. Milvus add_field():
|
||||
|
||||
```python
|
||||
add_field(
|
||||
field_name: str,
|
||||
datatype: DataType,
|
||||
is_primary: bool,
|
||||
max_length: int,
|
||||
element_type: str,
|
||||
max_capacity: int,
|
||||
dim: int,
|
||||
is_partition_key: bool,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus add_field().
|
||||
|
||||
##### Insert/Search-related
|
||||
|
||||
1. Milvus search():
|
||||
|
||||
```python
|
||||
search(
|
||||
collection_name: str,
|
||||
data: Union[List[list], list],
|
||||
filter: str = "",
|
||||
limit: int = 10,
|
||||
output_fields: Optional[List[str]] = None,
|
||||
search_params: Optional[dict] = None,
|
||||
timeout: Optional[float] = None,
|
||||
partition_names: Optional[List[str]] = None,
|
||||
**kwargs,
|
||||
) -> List[dict]
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* filter: string expression. For usage examples, see: [Milvus Filtering Explained](https://milvus.io/docs/boolean.md). It is generally similar to SQL's `WHERE` expression.
|
||||
|
||||
* search_params:
|
||||
|
||||
* metric_type: compatible.
|
||||
|
||||
* radius & range filter: related to RNN, currently not supported.
|
||||
|
||||
* group_by_field: groups ANN results, currently not supported.
|
||||
|
||||
* max_empty_result_buckets: used for IVF series indexes, currently not supported.
|
||||
|
||||
* ignore_growing: skips incremental data and directly reads baseline index, currently not supported.
|
||||
|
||||
* partition_names: partition read, supported.
|
||||
|
||||
* kwargs:
|
||||
|
||||
* offset: the number of records to skip in search results, currently not supported.
|
||||
|
||||
* round_decimal: rounds results to specified decimal places, currently not supported.
|
||||
|
||||
2. Milvus get():
|
||||
|
||||
```python
|
||||
get(
|
||||
collection_name: str,
|
||||
ids: Union[list, str, int],
|
||||
output_fields: Optional[List[str]] = None,
|
||||
timeout: Optional[float] = None,
|
||||
partition_names: Optional[List[str]] = None,
|
||||
**kwargs,
|
||||
) -> List[dict]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus get().
|
||||
|
||||
3. Milvus delete()
|
||||
|
||||
```python
|
||||
delete(
|
||||
collection_name: str,
|
||||
ids: Optional[Union[list, str, int]] = None,
|
||||
timeout: Optional[float] = None,
|
||||
filter: Optional[str] = "",
|
||||
partition_name: Optional[str] = "",
|
||||
**kwargs,
|
||||
) -> dict
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus delete().
|
||||
|
||||
4. Milvus insert()
|
||||
|
||||
```python
|
||||
insert(
|
||||
collection_name: str,
|
||||
data: Union[Dict, List[Dict]],
|
||||
timeout: Optional[float] = None,
|
||||
partition_name: Optional[str] = "",
|
||||
) -> List[Union[str, int]]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus insert().
|
||||
|
||||
5. Milvus upsert()
|
||||
|
||||
```python
|
||||
upsert(
|
||||
collection_name: str,
|
||||
data: Union[Dict, List[Dict]],
|
||||
timeout: Optional[float] = None,
|
||||
partition_name: Optional[str] = "",
|
||||
) -> List[Union[str, int]]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus upsert().
|
||||
|
||||
##### Index-related
|
||||
|
||||
1. Milvus create_index()
|
||||
|
||||
```python
|
||||
create_index(
|
||||
collection_name: str,
|
||||
index_params: IndexParams,
|
||||
timeout: Optional[float] = None,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus create_index().
|
||||
|
||||
2. Milvus drop_index()
|
||||
|
||||
```python
|
||||
drop_index(
|
||||
collection_name: str,
|
||||
index_name: str,
|
||||
timeout: Optional[float] = None,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus drop_index().
|
||||
|
||||
## Compatibility with MySQL protocol
|
||||
|
||||
* In terms of request initiation: All APIs are implemented through general query SQL, and there are no compatibility issues.
|
||||
|
||||
* In terms of response result set processing: Only processing of new vector data elements needs to be considered. Currently, string and bytes element parsing are supported. Even if the transmission mode of vector data elements changes in the future, compatibility can be achieved by updating the SDK.
|
||||
@@ -0,0 +1,12 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-supported-clients-and-languages-overview
|
||||
---
|
||||
|
||||
# Supported clients and languages for vector search
|
||||
|
||||
| Client/Language | Version |
|
||||
|---|---|
|
||||
| MySQL client | All versions |
|
||||
| Python SDK | 3.9+ |
|
||||
| Java SDK | 1.8 |
|
||||
@@ -0,0 +1,318 @@
|
||||
---
|
||||
|
||||
slug: /vector-pyobvector
|
||||
---
|
||||
|
||||
# pyobvector Python SDK API reference
|
||||
|
||||
pyobvector is the Python SDK for seekdb's vector storage feature. It provides two operating modes:
|
||||
|
||||
* pymilvus-compatible mode: Operates the database using the MilvusLikeClient object, offering commonly used APIs compatible with the lightweight MilvusClient.
|
||||
|
||||
* SQLAlchemy extension mode: Operates the database using the ObVecClient object, serving as an extension of Python's SDK for relational databases.
|
||||
|
||||
This topic describes the APIs in the two modes and provides examples.
|
||||
|
||||
## MilvusLikeClient
|
||||
|
||||
### Constructor
|
||||
|
||||
```python
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
uri: str = "127.0.0.1:2881",
|
||||
user: str = "root@test",
|
||||
password: str = "",
|
||||
db_name: str = "test",
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
### collection-related APIs
|
||||
|
||||
| API | Description | Example |
|
||||
|------|------|------|
|
||||
| `def create_schema(self, **kwargs) -> CollectionSchema:` | <ul>Creates a `CollectionSchema` object.<li>Parameters are optional, allowing the initialization of an empty schema definition.</li><li>Optional parameters include:</li><ul><li>`fields`: A list of `FieldSchema` objects (see the `add_field` interface below for details).</li><li>`partitions`: Partitioning rules (see the section on defining partition rules using `ObPartition`).</li><li>`description`: Compatible with Milvus, but currently has no practical effect in seekdb.</li></ul></ul> | |
|
||||
| `def create_collection(<br/>self,<br/>collection_name: str,<br/>dimension: Optional[int] = None,<br/>primary_field_name: str = "id",<br/>id_type: Union[DataType, str] = DataType.INT64,<br/>vector_field_name: str = "vector",<br/>metric_type: str = "l2",<br/>auto_id: bool = False,<br/>timeout: Optional[float] = None,<br/>schema: Optional[CollectionSchema] = None, # Used for custom setup<br/>index_params: Optional[IndexParams] = None, # Used for custom setup<br/>max_length: int = 16384,<br/>**kwargs,<br/>)` | Creates a table: <ul><li>collection_name: the table name</li><li>dimension: the vector data dimension</li><li>primary_field_name: the primary field name</li><li>id_type: the primary field data type (only supports VARCHAR and INT types)</li><li>vector_field_name: the vector field name</li><li>metric_type: not used in seekdb, but maintained for API compatibility (because the main table definition does not need to specify a vector distance function)</li><li>auto_id: specifies whether the primary field value increases automatically</li><li>timeout: not used in seekdb, but maintained for API compatibility</li><li>schema: the custom collection schema. When `schema` is not None, the parameters from dimension to metric_type will be ignored</li><li>index_params: the custom vector index parameters</li><li>max_length: the maximum varchar length when the primary field data type is VARCHAR and `schema` is not None</li></ul> | `client.create_collection(<br/>collection_name=test_collection_name,<br/>schema=schema,<br/>index_params=idx_params,<br/>)` |
|
||||
| `def get_collection_stats(<br/>self, collection_name: str, timeout: Optional[float] = None # pylint: disable=unused-argument<br/>) -> Dict:` | Queries the record count of a table.<ul><li>collection_name: the table name</li><li>timeout: not used in seekdb, but maintained for API compatibility</li></ul> | |
|
||||
| `def has_collection(self, collection_name: str, timeout: Optional[float] = None) -> bool` | Verifies whether a table exists.<ul><li>collection_name: the table name</li><li>timeout: not used in seekdb, but maintained for API compatibility</li></ul> | |
|
||||
| `def drop_collection(self, collection_name: str) -> None` | Drops a table.<ul><li>collection_name: the table name</li></ul> | |
|
||||
| `def load_table(self, collection_name: str,)` | Reads the metadata of a table to the SQLAlchemy metadata cache.<ul><li>collection_name: the table name</li></ul> | |
|
||||
|
||||
### CollectionSchema & FieldSchema
|
||||
|
||||
MilvusLikeClient describes the schema of a table by using a CollectionSchema. A CollectionSchema contains multiple FieldSchemas, and a FieldSchema describes the column schema of a table.
|
||||
|
||||
#### Create a CollectionSchema by using the create_schema method of the MilvusLikeClient
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
fields: Optional[List[FieldSchema]] = None,
|
||||
partitions: Optional[ObPartition] = None,
|
||||
description: str = "", # ignored in oceanbase
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* fields: an optional parameter that specifies a list of FieldSchema objects.
|
||||
|
||||
* partitions: partition rules (for more information, see the ObPartition section).
|
||||
|
||||
* description: compatible with Milvus, but currently has no practical effect in seekdb.
|
||||
|
||||
#### Create a FieldSchema and register it to a CollectionSchema
|
||||
|
||||
```python
|
||||
def add_field(self, field_name: str, datatype: DataType, **kwargs)
|
||||
```
|
||||
|
||||
* field_name: the column name.
|
||||
|
||||
* datatype: the column data type. For supported data types, see [Compatibility reference](../800.vector-sdk-refer.md).
|
||||
|
||||
* kwargs: additional parameters for configuring column properties, as shown below:
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
name: str,
|
||||
dtype: DataType,
|
||||
description: str = "",
|
||||
is_primary: bool = False,
|
||||
auto_id: bool = False,
|
||||
nullable: bool = False,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* is_primary: specifies whether the column is a primary key.
|
||||
|
||||
* auto_id: specifies whether the column value increases automatically.
|
||||
|
||||
* nullable: specifies whether the column can be null.
|
||||
|
||||
#### Example
|
||||
|
||||
```python
|
||||
schema = self.client.create_schema()
|
||||
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
|
||||
schema.add_field(field_name="title", datatype=DataType.VARCHAR, max_length=512)
|
||||
schema.add_field(
|
||||
field_name="title_vector", datatype=DataType.FLOAT_VECTOR, dim=768
|
||||
)
|
||||
schema.add_field(field_name="link", datatype=DataType.VARCHAR, max_length=512)
|
||||
schema.add_field(field_name="reading_time", datatype=DataType.INT64)
|
||||
schema.add_field(
|
||||
field_name="publication", datatype=DataType.VARCHAR, max_length=512
|
||||
)
|
||||
schema.add_field(field_name="claps", datatype=DataType.INT64)
|
||||
schema.add_field(field_name="responses", datatype=DataType.INT64)
|
||||
|
||||
self.client.create_collection(
|
||||
collection_name="medium_articles_2020", schema=schema
|
||||
)
|
||||
```
|
||||
|
||||
### Index-related APIs
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def create_index(<br/>self,<br/>collection_name: str,<br/>index_params: IndexParams,<br/>timeout: Optional[float] = None,<br/>**kwargs,<br/>)` | Creates a vector index table based on the constructed IndexParams (for more information about how to use IndexParams, see the prepare_index_params and add_index APIs).<ul><li>collection_name: the table name</li><li>index_params: the index parameters</li><li>timeout: not used in seekdb, but maintained for API compatibility</li><li>kwargs: other parameters, currently not used, maintained for compatibility</li></ul> | |
|
||||
| `def drop_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>timeout: Optional[float] = None,<br/>**kwargs,<br/>)` | Drops an index table.<ul><li>collection_name: the table name</li><li>index_name: the index name</li></ul> | |
|
||||
| `def refresh_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>trigger_threshold: int = 10000,<br/>)` | Refreshes a vector index table to improve read performance. It can be understood as a process of moving incremental data.<ul><li>collection_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the refresh action. A refresh is triggered when the data volume of the index table exceeds the threshold.</li></ul> | An API introduced
|
||||
| `def rebuild_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>trigger_threshold: float = 0.2,<br/>)` | Rebuilds a vector index table to improve read performance. It can be understood as a process of merging incremental data into baseline index data.<ul><li>collection_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the rebuild action. The value range is 0 to 1. A rebuild is triggered when the proportion of incremental data to full data reaches the threshold.</li></ul> | An API introduced by seekdb.<br/>Not compatible with Milvus. |
|
||||
| `def search(<br/>self,<br/>collection_name: str,<br/>data: list,<br/>anns_field: str,<br/>with_dist: bool = False,<br/>filter=None,limit: int = 10,output_fields: Optional[List[str]] = None,<br/>search_params: Optional[dict] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Executes a vector approximate nearest neighbor search.<ul><li>collection_name: the table name</li><li>data: the vector data to be searched</li><li>anns_field: the name of the vector column to be searched</li><li>with_dist: specifies whether to return results with vector distances</li><li>filter: uses vector approximate nearest neighbor search with filter conditions</li><li>limit: top K</li><li>output_fields: the output columns (also known as projection columns)</li><li>search_params: supports only the `metric_type` value of `l2`/`neg_ip` (`for example: search_params = {"metric_type": "neg_ip"}`)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul><ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values.</ul> | `res = self.client.search(<br/>collection_name=test_collection_name,<br/>data=[0, 0, 1],<br/>anns_field="embedding",<br/>limit=5,<br/>output_fields=["id"],<br/>search_params={"metric_type": "neg_ip"}<br/>)<br/>self.assertEqual(<br/> set([r['id'] for r in res]), set([12, 111, 11, 112, 10]))` |
|
||||
| `def query(<br/>self,<br/>collection_name: str,<br/>flter=None,<br/>output_fields: Optional[List[str]] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Reads data records using the specified filter condition.<ul><li>collection_name: the table name</li><li>flter: uses vector approximate nearest neighbor search with filter conditions</li><li>output_fields: the output columns (also known as projection columns)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul><ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values.</ul> | `table = self.client.load_table(collection_name=test_collection_name)<br/>where_clause = [table.c["id"] < 100]<br/>res = self.client.query(<br/> collection_name=test_collection_name,<br/> output_fields=["id"],<br/> flter=where_clause,<br/>)` |
|
||||
| `def get(<br/>self,<br/>collection_name: str,<br/>ids: Union[list, str, int],<br/>output_fields: Optional[List[str]] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Retrieves records based on the specified primary keys `ids`:<ul><li>collection_name: the table name</li><li>ids: a single ID or a list of IDs. Note: The ids parameter of MilvusLikeClient get interface is different from ObVecClient get. For details, see <a href="#DML%20operations">ObVecClient get</a></li><li>output_fields: the output columns (also known as projection columns)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values. | `res = self.client.get(<br/> collection_name=test_collection_name,<br/> output_fields=["id", "meta"],<br/> ids=[80, 12, 112],<br/>)` |
|
||||
| `def delete(<br/>self,<br/>collection_name: str,<br/>ids: Optional[Union[list, str, int]] = None,<br/>timeout: Optional[float] = None, # pylint: disable=unused-argument<br/>flter=None,<br/>partition_name: Optional[str] = "",<br/>**kwargs, # pylint: disable=unused-argument<br/>)` | Deletes data in a collection.<ul><li>collection_name: the table name</li><li>ids: a single ID or a list of IDs</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>flter: uses vector approximate nearest neighbor search with filter conditions</li><li>partition_name: limits the deletion operation to a partition</li></ul> | `self.client.delete(<br/> collection_name=test_collection_name, ids=[12, 112], partition_name="p0"<br/>)` |
|
||||
| `def insert(<br/> self, <br/> collection_name: str, <br/> data: Union[Dict, List[Dict]], <br/> timeout: Optional[float] = None, <br/> partition_name: Optional[str] = ""<br/>)` | Inserts data into a table.<ul><li>collection_name: the table name</li><li>data: the data to be inserted, described in Key-Value form</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_name: limits the insertion operation to a partition</li></ul> | `data = [<br/> {"id": 12, "embedding": [1, 2, 3], "meta": {"doc": "document 1"}},<br/> {<br/> "id": 90,<br/> "embedding": [0.13, 0.123, 1.213],<br/> "meta": {"doc": "document 1"},<br/> },<br/> {"id": 112, "embedding": [1, 2, 3], "meta": None},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": None},<br/>]<br/>self.client.insert(collection_name=test_collection_name, data=data)` |
|
||||
| `def upsert(<br/>self,<br/>collection_name: str,<br/>data: Union[Dict, List[Dict]],<br/>timeout: Optional[float] = None, # pylint: disable=unused-argument<br/>partition_name: Optional[str] = "",<br/>) -> List[Union[str, int]]` | Updates data in a table. If a primary key already exists, updates the corresponding record; otherwise, inserts a new record.<ul><li>collection_name: the table name</li><li>data: the data to be inserted or updated, in the same format as the insert interface</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_name: limits the operation to a specified partition</li></ul> | `data = [<br/> {"id": 112, "embedding": [1, 2, 3], "meta": {'doc':'hhh1'}},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": {'doc':'hhh2'}},<br/>]<br/>self.client.upsert(collection_name=test_collection_name, data=data)` |
|
||||
| `def perform_raw_text_sql(self, text_sql: str):<br/> return super().perform_raw_text_sql(text_sql)` | Executes an SQL statement directly.<ul><li>text_sql: the SQL statement to be executed</li></ul>Return value:<br/>Returns an iterator that provides result sets from SQLAlchemy. | |
|
||||
|
||||
## ObVecClient
|
||||
|
||||
### Constructor
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
uri: str = "127.0.0.1:2881",
|
||||
user: str = "root@test",
|
||||
password: str = "",
|
||||
db_name: str = "test",
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
### Table mode-related operations
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def check_table_exists(self, table_name: str)` | Checks whether a table exists.<ul><li>table_name: the table name</li></ul> | |
|
||||
| `def create_table(<br/>self,<br/>table_name: str,<br/>columns: List[Column],<br/>indexes: Optional[List[Index]] = None,<br/>partitions: Optional[ObPartition] = None,<br/>)` | Creates a table.<ul><li>table_name: the table name</li><li>columns: the column schema of the table, defined using SQLAlchemy</li><li>indexes: a set of index schemas, defined using SQLAlchemy</li><li>partitions: optional partition rules (see the section on using ObPartition to define partition rules)</li></ul> | |
|
||||
| `@classmethod<br/>def prepare_index_params(cls)` | Creates an IndexParams object to record the schema definition of a vector index table.`class IndexParams:<br/> """Vector index parameters for MilvusLikeClient"<br/> def __init__(self):<br/> self._indexes = {}`<br/>The definition of IndexParams is very simple, with only one dictionary member internally<br/>that stores a mapping from a tuple of (column name, index name) to an IndexParam structure.<br/>The constructor of the IndexParam class is:`def __init__(<br/> self,<br/> index_name: str,<br/> field_name: str,<br/> index_type: Union[VecIndexType, str],<br/> **kwargs<br/>)`<ul><li>index_name: the vector index table name</li><li>field_name: the vector column name</li><li>index_type: an enumerated class for vector index algorithm types. Currently, only HNSW is supported.</li></ul>After obtaining an IndexParams by calling `prepare_index_params`, you can register an IndexParam using the `add_index` interface:`def add_index(<br/> self,<br/> field_name: str,<br/> index_type: VecIndexType,<br/> index_name: str,<br/> **kwargs<br/>)`The parameter meanings are the same as those in the IndexParam constructor. | Here is a usage example for creating a vector index: `idx_params = self.client.prepare_index_params()<br/>idx_params.add_index(<br/> field_name="title_vector",<br/> index_type="HNSW",<br/> index_name="vidx_title_vector",<br/> metric_type="L2",<br/> params={"M": 16, "efConstruction": 256},<br/>)<br/>self.client.create_collection(<br/> collection_name=test_collection_name,<br/> schema=schema,<br/> <br/>index_params=idx_params,<br/>)`Note that the `prepare_index_params` function is recommended for use in MilvusLikeClient, not in ObVecClient. In ObVecClient mode, you should use the `create_index` interface to define a vector index table. (For details, see the create_index interface.) |
|
||||
| `def create_table_with_index_params(<br/>self,<br/>table_name: str,<br/>columns: List[Column],<br/>indexes: Optional[List[Index]] = None,<br/>vidxs: Optional[IndexParams] = None,<br/>partitions: Optional[ObPartition] = None,<br/>) | Creates a table and a vector index at the same time using optional index_params.<ul><li>table_name: the table name</li><li>columns: the column schema of the table, defined using SQLAlchemy</li><li>indexes: a set of index schemas, defined using SQLAlchemy</li><li>vidxs: the vector index schema, specified using IndexParams</li><li>partitions: optional partition rules (see the section on using ObPartition to define partition rules)</li></ul> | Recommended for use in MilvusLikeClient, not recommended for use in ObVecClient |
|
||||
| `def create_index(<br/>self,<br/>table_name: str,<br/>is_vec_index: bool,<br/>index_name: str,<br/>column_names: List[str],<br/>vidx_params: Optional[str] = None,<br/>**kw,<br/>)` | Supports creating both normal indexes and vector indexes.<ul><li>table_name: the table name</li><li>is_vec_index: specifies whether to create a normal index or a vector index</li><li>index_name: the index name</li><li>column_names: the columns on which to create the index</li><li>vidx_params: the vector index parameters, for example: `"distance=l2, type=hnsw, lib=vsag"`</li></ul>Currently, seekdb supports only `type=hnsw` and `lib=vsag`. Please retain these settings. The distance can be set to `l2` or `inner_product`. | `self.client.create_index(<br/> test_collection_name,<br/> is_vec_index=True,<br/> index_name="vidx",<br/> column_names=["embedding"],<br/> vidx_params="distance=l2, type=hnsw, lib=vsag",<br/>) |
|
||||
| `def create_vidx_with_vec_index_param(<br/>self,<br/>table_name: str,<br/>vidx_param: IndexParam,<br/>)` | Creates a vector index using vector index parameters.<ul><li>table_name: the table name</li><li>vidx_param: the vector index parameters constructed using IndexParam</li></ul> | |
|
||||
| `def drop_table_if_exist(self, table_name: str)` | Drops a table.<ul><li>table_name: the table name</li></ul> | |
|
||||
| `def drop_index(self, table_name: str, index_name: str)` | Drops an index.<ul><li>table_name: the table name</li><li>index_name: the index name</li></ul> | |
|
||||
| `def refresh_index(<br/>self,<br/>table_name: str,<br/>index_name: str,<br/>trigger_threshold: int = 10000,<br/>)` | Refreshes a vector index table to improve read performance. It can be understood as a process of moving incremental data.<ul><li>table_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the refresh action. A refresh is triggered when the data volume of the index table exceeds the threshold.</li></ul> | |
|
||||
| `def rebuild_index(<br/>self,<br/>table_name: str,<br/>index_name: str,<br/>trigger_threshold: float = 0.2,<br/>)` | Rebuilds a vector index table to improve read performance. It can be understood as a process of merging incremental data into baseline index data.<ul><li>table_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the rebuild action. The value range is 0 to 1. A rebuild is triggered when the proportion of incremental data to full data reaches the threshold.</li></ul> | |
|
||||
|
||||
### DML operations
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def insert(<br/>self,<br/>table_name: str,<br/>data: Union[Dict, List[Dict]],<br/>partition_name: Optional[str] = "",<br/>)` | Inserts data into a table.<ul><li>table_name: the table name</li><li>data: the data to be inserted, described in Key-Value form</li><li>partition_name: limits the insertion operation to a partition</li></ul> | `vector_value1 = [0.748479, 0.276979, 0.555195]<br/>vector_value2 = [0, 0, 0]<br/>data1 = [{"id": i, "embedding": vector_value1} for i in range(10)]<br/>data1.extend([{"id": i, "embedding": vector_value2} for i in range(10, 13)])<br/>data1.extend([{"id": i, "embedding": vector_value2} for i in range(111, 113)])<br/>self.client.insert(test_collection_name, data=data1)` |
|
||||
| `def upsert(<br/>self,<br/>table_name: str,<br/>data: Union[Dict, List[Dict]],<br/>partition_name: Optional[str] = "",<br/>)` | Inserts or updates data in a table. If a primary key already exists, updates the corresponding record; otherwise, inserts a new record.<ul><li>table_name: the table name</li><li>data: the data to be inserted or updated, in Key-Value format</li><li>partition_name: limits the operation to a specified partition</li></ul> | |
|
||||
| `def update(<br/>self,<br/>table_name: str,<br/>values_clause,<br/>where_clause=None,<br/>partition_name: Optional[str] = "",<br/>)` | Updates data in a table. If a primary key is repeated, it will be replaced.<ul><li>table_name: the table name</li><li>values_clause: the values of the columns to be updated</li><li>where_clause: the condition for updating</li><li>partition_name: limits the update operation to some partitions</li></ul> | `data = [<br/> {"id": 112, "embedding": [1, 2, 3], "meta": {'doc':'hhh1'}},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": {'doc':'hhh2'}},<br/>]<br/>client.insert(collection_name=test_collection_name, data=data)<br/>client.update(<br/> table_name=test_collection_name,<br/> values_clause=[{'meta':{'doc':'HHH'}}],<br/> where_clause=[text("id=112")]<br/>)` |
|
||||
| `def delete(<br/>self,<br/>table_name: str,<br/>ids: Optional[Union[list, str, int]] = None,<br/>where_clause=None,<br/>partition_name: Optional[str] = "",<br/>)` | Deletes data from a table.<ul><li>table_name: the table name</li><li>ids: a single ID or a list of IDs</li><li>where_clause: the condition for deletion</li><li>partition_name: limits the deletion operation to some partitions</li></ul> | `self.client.delete(test_collection_name, ids=["bcd", "def"])` |
|
||||
| `def get(<br/>self,<br/>table_name: str,<br/>ids: Optional[Union[list, str, int]],<br/>where_clause = None,<br/>output_column_name: Optional[List[str]] = None,<br/>partition_names: Optional[List[str]] = None,<br/>)` | Retrieves records based on the specified primary keys `ids`.<ul><li>table_name: the table name</li><li>ids: a single ID or a list of IDs. Optional parameter, can be `ids=None` if not provided. The ids parameter of ObVecClient get interface is different from MilvusLikeClient get. For details, see <a href="#Index-related%20APIs">MilvusLikeClient get</a></li><li>where_clause: the condition for retrieval</li><li>output_column_name: a list of output column or projection column names</li><li>partition_names: limits the retrieval operation to some partitions</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | `res = self.client.get(<br/> test_collection_name,<br/> ids=["abc", "bcd", "cde", "def"],<br/> where_clause=[text("meta->'$.page' > 1")],<br/> output_column_name=['id']<br/>) |
|
||||
| `def set_ob_hnsw_ef_search(self, ob_hnsw_ef_search: int)` | Set the efSearch parameter of the HNSW index. This is a session-level variable. The larger the value of ef_search, the higher the recall rate but the poorer the query performance. <ul><li>ob_hnsw_ef_search: the efSearch parameter of the HNSW index</li></ul> | |
|
||||
| `def get_ob_hnsw_ef_search(self) -> int` | Get the efSearch parameter of the HNSW index. | |
|
||||
| `def ann_search(<br/>self,<br/>table_name: str,<br/>vec_data: list,<br/>vec_column_name: str,<br/>distance_func,<br/>with_dist: bool = False,<br/>topk: int = 10,<br/>output_column_names: Optional[List[str]] = None,<br/>extra_output_cols: Optional[List] = None,<br/>where_clause=None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>)` | Executes a vector approximate nearest neighbor search.<ul><li>table_name: the table name</li><li>vec_data: the vector data to be searched</li><li>vec_column_name: the name of the vector column to be searched</li><li>distance_func: the distance function. Provides an extension of SQLAlchemy func, with optional values: `func.l2_distance`/`func.cosine_distance`/`func.inner_product`/`func.negative_inner_product`, representing the l2 distance function, cosine distance function, inner product distance function, and negative inner product distance function, respectively</li><li>with_dist: specifies whether to return results with vector distances</li><li>topk: the number of nearest vectors to retrieve</li><li>output_column_names: a list of output column or projection column names</li><li>extra_output_cols: additional output columns that allow more complex output expressions</li><li>where_clause: the filter condition</li><li>partition_names: limits the query to some partitions</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | `res = self.client.ann_search(<br/> test_collection_name,<br/> vec_data=[0, 0, 0],<br/> vec_column_name="embedding",<br/> distance_func=func.l2_distance,<br/> with_dist=True,<br/> topk=5,<br/> output_column_names=["id"],<br/>) |
|
||||
| `def precise_search(<br/>self,<br/>table_name: str,<br/>vec_data: list,<br/>vec_column_name: str,<br/>distance_func,<br/>topk: int = 10,<br/>output_column_names: Optional[List[str]] = None,<br/>where_clause=None,<br/>**kwargs,<br/>) | Executes a precise neighbor search algorithm.<ul><li>table_name: the table name</li><li>vec_data: the query vector</li><li>vec_column_name: the vector column name</li><li>distance_func: the vector distance function. Provides an extension of SQLAlchemy func, with optional values: func.l2_distance/func.cosine_distance/func.inner_product/func.negative_inner_product, representing the l2 distance function, cosine distance function, inner product distance function, and negative inner product distance function, respectively</li><li>topk: the number of nearest vectors to retrieve</li><li>output_column_names: a list of output column or projection column names</li><li>where_clause: the filter condition</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | |
|
||||
| `def perform_raw_text_sql(self, text_sql: str)` | Executes an SQL statement directly.<ul><li>text_sql: the SQL statement to be executed</li></ul>Return value:<br/>Returns an iterator that provides result sets from SQLAlchemy. | |
|
||||
|
||||
## Define partitioning rules by using ObPartition
|
||||
|
||||
pyobvector supports the following types for range/range columns, list/list columns, hash, key, and subpartitioning:
|
||||
|
||||
* ObRangePartition: specifies to perform range partitioning. Set `is_range_columns` to `True` when you construct this object to create range column partitioning.
|
||||
|
||||
* ObListPartition: specifies to perform list partitioning. Set `is_list_columns` to `True` when you construct this object to create list column partitioning.
|
||||
|
||||
* ObHashPartition: specifies to perform hash partitioning.
|
||||
|
||||
* ObKeyPartition: specifies to perform key partitioning.
|
||||
|
||||
* ObSubRangePartition: specifies to perform sub-range partitioning. Set `is_range_columns` to `True` when you construct this object to create sub-range column partitioning.
|
||||
|
||||
* ObSubListPartition: specifies to perform sub-list partitioning. Set `is_list_columns` to `True` when you construct this object to create sub-list column partitioning.
|
||||
|
||||
* ObSubHashPartition: specifies to perform sub-hash partitioning.
|
||||
|
||||
* ObSubKeyPartition: specifies to perform sub-key partitioning.
|
||||
|
||||
### Example of range partitioning
|
||||
|
||||
```python
|
||||
range_part = ObRangePartition(
|
||||
False,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("p0", 100),
|
||||
RangeListPartInfo("p1", "maxvalue"),
|
||||
],
|
||||
range_expr="id",
|
||||
)
|
||||
```
|
||||
|
||||
### Example of list partitioning
|
||||
|
||||
```python
|
||||
list_part = ObListPartition(
|
||||
False,
|
||||
list_part_infos=[
|
||||
RangeListPartInfo("p0", [1, 2, 3]),
|
||||
RangeListPartInfo("p1", [5, 6]),
|
||||
RangeListPartInfo("p2", "DEFAULT"),
|
||||
],
|
||||
list_expr="col1",
|
||||
)
|
||||
```
|
||||
|
||||
### Example of hash partitioning
|
||||
|
||||
```python
|
||||
hash_part = ObHashPartition("col1", part_count=60)
|
||||
```
|
||||
|
||||
### Example of multi-level partitioning
|
||||
|
||||
```python
|
||||
# Perform range partitioning
|
||||
range_columns_part = ObRangePartition(
|
||||
True,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("p0", 100),
|
||||
RangeListPartInfo("p1", 200),
|
||||
RangeListPartInfo("p2", 300),
|
||||
],
|
||||
col_name_list=["col1"],
|
||||
)
|
||||
# Perform sub-range partitioning
|
||||
range_sub_part = ObSubRangePartition(
|
||||
False,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("mp0", 1000),
|
||||
RangeListPartInfo("mp1", 2000),
|
||||
RangeListPartInfo("mp2", 3000),
|
||||
],
|
||||
range_expr="col3",
|
||||
)
|
||||
range_columns_part.add_subpartition(range_sub_part)
|
||||
```
|
||||
|
||||
## Pure SQLAlchemy API mode
|
||||
|
||||
If you prefer to use a purely SQLAlchemy API for seekdb's vector retrieval functionality, you can obtain a synchronized database engine through the following methods:
|
||||
|
||||
* Method 1: Use ObVecClient to create a database engine
|
||||
|
||||
```python
|
||||
from pyobvector import ObVecClient
|
||||
|
||||
client = ObVecClient(uri="127.0.0.1:2881", user="test@test")
|
||||
engine = client.engine
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
* Method 2: Call the `create_engine` interface of ObVecClient to create a database engine
|
||||
|
||||
```python
|
||||
import pyobvector
|
||||
from sqlalchemy.dialects import registry
|
||||
from sqlalchemy import create_engine
|
||||
|
||||
uri: str = "127.0.0.1:2881"
|
||||
user: str = "root@test"
|
||||
password: str = ""
|
||||
db_name: str = "test"
|
||||
registry.register("mysql.oceanbase", "pyobvector.schema.dialect", "OceanBaseDialect")
|
||||
connection_str = (
|
||||
# mysql+oceanbase indicates using the MySQL standard with seekdb's synchronous driver.
|
||||
f"mysql+oceanbase://{user}:{password}@{uri}/{db_name}?charset=utf8mb4"
|
||||
)
|
||||
engine = create_engine(connection_str, **kwargs)
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
If you want to use asynchronous APIs of SQLAlchemy, you can use seekdb's asynchronous driver:
|
||||
|
||||
```python
|
||||
import pyobvector
|
||||
from sqlalchemy.dialects import registry
|
||||
from sqlalchemy.ext.asyncio import create_async_engine
|
||||
|
||||
uri: str = "127.0.0.1:2881"
|
||||
user: str = "root@test"
|
||||
password: str = ""
|
||||
db_name: str = "test"
|
||||
registry.register("mysql.aoceanbase", "pyobvector", "AsyncOceanBaseDialect")
|
||||
connection_str = (
|
||||
# mysql+aoceanbase indicates using the MySQL standard with seekdb's asynchronous driver.
|
||||
f"mysql+aoceanbase://{user}:{password}@{uri}/{db_name}?charset=utf8mb4"
|
||||
)
|
||||
engine = create_async_engine(connection_str)
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
## More examples
|
||||
|
||||
For more examples, visit the [pyobvector repository](https://github.com/oceanbase/pyobvector).
|
||||
@@ -0,0 +1,470 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-java-sdk
|
||||
---
|
||||
|
||||
# Java SDK API reference
|
||||
|
||||
obvec_jdbc is a Java SDK specifically designed for seekdb vector storage scenarios and JSON Table virtual table scenarios. This topic explains how to use obvec_jdbc.
|
||||
|
||||
## Installation
|
||||
|
||||
You can install obvec_jdbc using either of the following methods.
|
||||
|
||||
### Maven dependency
|
||||
|
||||
Add the obvec_jdbc dependency to the `pom.xml` file of your project.
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.oceanbase</groupId>
|
||||
<artifactId>obvec_jdbc</artifactId>
|
||||
<version>1.0.4</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
### Source code installation
|
||||
|
||||
1. Install obvec_jdbc.
|
||||
|
||||
```bash
|
||||
# Clone the obvec_jdbc repository.
|
||||
git clone https://github.com/oceanbase/obvec_jdbc.git
|
||||
# Go to the obvec_jdbc directory.
|
||||
cd obvec_jdbc
|
||||
# Install obvec_jdbc.
|
||||
mvn install
|
||||
```
|
||||
|
||||
2. Add the dependency.
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.oceanbase</groupId>
|
||||
<artifactId>obvec_jdbc</artifactId>
|
||||
<version>1.0.4</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
## API definition and usage
|
||||
|
||||
obvec_jdbc provides the `ObVecClient` object for working with seekdb's vector search features and JSON Table virtual table functionalities.
|
||||
|
||||
### Use vector search
|
||||
|
||||
#### Create a client
|
||||
|
||||
You can use the following interface definition to construct an ObVecClient object:
|
||||
|
||||
```java
|
||||
# uri: the connection string, which contains the address, port, and name of the database to which you want to connect.
|
||||
# user: the username.
|
||||
# password: the password.
|
||||
public ObVecClient(String uri, String user, String password);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.ObVecClient;
|
||||
|
||||
String uri = "jdbc:oceanbase://127.0.0.1:2881/test";
|
||||
String user = "root@test";
|
||||
String password = "";
|
||||
String tb_name = "JAVA_TEST";
|
||||
|
||||
ObVecClient ob = new ObVecClient(uri, user, password);
|
||||
```
|
||||
|
||||
#### ObFieldSchema class
|
||||
|
||||
This class is used to define the column schema of a table. The constructor is as follows:
|
||||
|
||||
```java
|
||||
# name: the column name.
|
||||
# dataType: the data type.
|
||||
public ObFieldSchema(String name, DataType dataType);
|
||||
```
|
||||
|
||||
The following table describes the data types supported by the class.
|
||||
|
||||
| Data type | Description |
|
||||
|---|---|
|
||||
| BOOL | Equivalent to TINYINT |
|
||||
| INT8 | Equivalent to TINYINT |
|
||||
| INT16 | Equivalent to SMALLINT |
|
||||
| INT32 | Equivalent to INT |
|
||||
| INT64 | Equivalent to BIGINT |
|
||||
| FLOAT | Equivalent to FLOAT |
|
||||
| DOUBLE | Equivalent to DOUBLE |
|
||||
| STRING | Equivalent to LONGTEXT |
|
||||
| VARCHAR | Equivalent to VARCHAR |
|
||||
| JSON | Equivalent to JSON |
|
||||
| FLOAT_VECTOR | Equivalent to VECTOR |
|
||||
|
||||
:::tip
|
||||
For more complex types, constraints, and other functionalities, you can use seekdb JDBC's interface directly instead of using obvec_jdbc.
|
||||
:::
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| String getName() | Obtains the column name. |
|
||||
| ObFieldSchema Name(String name) | Sets the column name and returns the object itself to support chain operations. |
|
||||
| ObFieldSchema DataType(DataType dataType) | Sets the data type. |
|
||||
| boolean getIsPrimary() | Specifies whether the column is the primary key. |
|
||||
| ObFieldSchema IsPrimary(boolean isPrimary) | Specifies whether the column is the primary key. |
|
||||
| ObFieldSchema IsAutoInc(boolean isAutoInc) | Specifies whether the column is auto-increment. <main id="notice" type='notice'><h4>Notice</h4><p>IsAutoInc takes effect only if IsPrimary is true. </p></main> |
|
||||
| ObFieldSchema IsNullable(boolean isNullable) | Specifies whether the column can contain NULL values. <main id="notice" type='notice'><h4>Notice</h4><p>IsNullable is set to false by default, which is different from the behavior in MySQL. </p></main> |
|
||||
| ObFieldSchema MaxLength(int maxLength) | Sets the maximum length for the VARCHAR data type. |
|
||||
| ObFieldSchema Dim(int dim) | Sets the dimension for the VECTOR data type. |
|
||||
|
||||
#### IndexParams/IndexParam
|
||||
|
||||
IndexParam is used to set a single index parameter. IndexParams is used to set a group of vector index parameters, which is used when multiple vector indexes are created on a table.
|
||||
|
||||
:::tip
|
||||
obvec_jdbc supports only the creation of vector indexes. To create other indexes, use seekdb JDBC.
|
||||
:::
|
||||
|
||||
The constructor of IndexParam is as follows:
|
||||
|
||||
```java
|
||||
# vidx_name: the index name.
|
||||
# vector_field_name: the name of the vector column.
|
||||
public IndexParam(String vidx_name, String vector_field_name);
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| IndexParam M(int m) | Sets the maximum number of neighbors for each vector in the HNSW algorithm. |
|
||||
| IndexParam EfConstruction(int ef_construction) | Sets the maximum number of candidate vectors for search during the construction of the HNSW algorithm. |
|
||||
| IndexParam EfSearch(int ef_search) | Sets the maximum number of candidate vectors for search in the HNSW algorithm. |
|
||||
| IndexParam Lib(String lib) | Sets the type of the vector library. |
|
||||
| IndexParam MetricType(String metric_type) | Sets the type of the vector distance function. |
|
||||
|
||||
The constructor of IndexParams is as follows:
|
||||
|
||||
```
|
||||
public IndexParams();
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| void addIndex(IndexParam index_param) | Adds an index definition. |
|
||||
|
||||
#### ObCollectionSchema class
|
||||
|
||||
When creating a table, you need to rely on the configuration of the ObCollectionSchema object. Below are its constructors and interfaces.
|
||||
|
||||
The constructor of ObCollectionSchema is as follows:
|
||||
|
||||
```java
|
||||
public ObCollectionSchema();
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| void addField(ObFieldSchema field) | Adds a column definition. |
|
||||
| void setIndexParams(IndexParams index_params) | Sets the vector index parameters of the table. |
|
||||
|
||||
#### Drop a table
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
public void dropCollection(String table_name);
|
||||
```
|
||||
|
||||
#### Check whether a table exists
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
public boolean hasCollection(String table_name);
|
||||
```
|
||||
|
||||
#### Create a table
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the table to be created.
|
||||
# collection: an ObCollectionSchema object that specifies the schema of the table.
|
||||
public void createCollection(String table_name, ObCollectionSchema collection);
|
||||
```
|
||||
|
||||
You can use ObFieldSchema, ObCollectionSchema, and IndexParams to create a table. Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.DataType;
|
||||
import com.oceanbase.obvec_jdbc.ObCollectionSchema;
|
||||
import com.oceanbase.obvec_jdbc.ObFieldSchema;
|
||||
import com.oceanbase.obvec_jdbc.IndexParam;
|
||||
import com.oceanbase.obvec_jdbc.IndexParams;
|
||||
|
||||
# Define the schema of the table.
|
||||
ObCollectionSchema collectionSchema = new ObCollectionSchema();
|
||||
ObFieldSchema c1_field = new ObFieldSchema("c1", DataType.INT32);
|
||||
c1_field.IsPrimary(true).IsAutoInc(true);
|
||||
ObFieldSchema c2_field = new ObFieldSchema("c2", DataType.FLOAT_VECTOR);
|
||||
c2_field.Dim(3).IsNullable(false);
|
||||
ObFieldSchema c3_field = new ObFieldSchema("c3", DataType.JSON);
|
||||
c3_field.IsNullable(true);
|
||||
collectionSchema.addField(c1_field);
|
||||
collectionSchema.addField(c2_field);
|
||||
collectionSchema.addField(c3_field);
|
||||
|
||||
# Define the index.
|
||||
IndexParams index_params = new IndexParams();
|
||||
IndexParam index_param = new IndexParam("vidx1", "c2");
|
||||
index_params.addIndex(index_param);
|
||||
collectionSchema.setIndexParams(index_params);
|
||||
|
||||
ob.createCollection(tb_name, collectionSchema);
|
||||
```
|
||||
|
||||
#### Create a vector index after table creation
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the table.
|
||||
# index_param: an IndexParam object that specifies the vector index parameters of the table.
|
||||
public void createIndex(String table_name, IndexParam index_param)
|
||||
```
|
||||
|
||||
#### Insert data
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# column_names: an array of column names in the target table.
|
||||
# rows: the data rows. ArrayList<Sqlizable[]>, each row is an Sqlizable array. Sqlizable is a wrapper class that converts Java data types to SQL data types.
|
||||
public void insert(String table_name, String[] column_names, ArrayList<Sqlizable[]> rows);
|
||||
```
|
||||
|
||||
The supported data types for rows include:
|
||||
|
||||
* SqlInteger: wraps integer data.
|
||||
* SqlFloat: wraps floating-point data.
|
||||
* SqlDouble: wraps double-precision data.
|
||||
* SqlText: wraps string data.
|
||||
* SqlVector: wraps vector data.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.SqlInteger;
|
||||
import com.oceanbase.obvec_jdbc.SqlText;
|
||||
import com.oceanbase.obvec_jdbc.SqlVector;
|
||||
import com.oceanbase.obvec_jdbc.Sqlizable;
|
||||
|
||||
ArrayList<Sqlizable[]> insert_rows = new ArrayList<>();
|
||||
Sqlizable[] ir1 = { new SqlVector(new float[] {1.0f, 2.0f, 3.0f}), new SqlText("{\"doc\": \"oceanbase doc 1\"}") };
|
||||
insert_rows.add(ir1);
|
||||
Sqlizable[] ir2 = { new SqlVector(new float[] {1.1f, 2.2f, 3.3f}), new SqlText("{\"doc\": \"oceanbase doc 2\"}") };
|
||||
insert_rows.add(ir2);
|
||||
Sqlizable[] ir3 = { new SqlVector(new float[] {0f, 0f, 0f}), new SqlText("{\"doc\": \"oceanbase doc 3\"}") };
|
||||
insert_rows.add(ir3);
|
||||
ob.insert(tb_name, new String[] {"c2", "c3"}, insert_rows);
|
||||
```
|
||||
|
||||
#### Delete data
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# primary_key_name: the name of the primary key column.
|
||||
# primary_keys: an array of primary key column values for the target rows.
|
||||
public void delete(String table_name, String primary_key_name, ArrayList<Sqlizable> primary_keys);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
ArrayList<Sqlizable> ids = new ArrayList<>();
|
||||
ids.add(new SqlInteger(2));
|
||||
ids.add(new SqlInteger(1));
|
||||
ob.delete(tb_name, "c1", ids);
|
||||
```
|
||||
|
||||
#### ANN queries
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# vec_col_name: the name of the vector column.
|
||||
# metric_type: the type of the vector distance function. l2: corresponds to the L2 distance function. cosine: corresponds to the cosine distance function. ip: corresponds to the negative inner product distance function.
|
||||
# qv: the vector value to be queried.
|
||||
# topk: the number of the most similar results to be returned.
|
||||
# output_fields: the projected columns, that is, the array of the fields to be returned.
|
||||
# output_datatypes: the data types of the projected columns, that is, the data types of the fields to be returned, for direct conversion to Java data types.
|
||||
# where_expr: the WHERE condition expression.
|
||||
public ArrayList<HashMap<String, Sqlizable>> query(
|
||||
String table_name,
|
||||
String vec_col_name,
|
||||
String metric_type,
|
||||
float[] qv,
|
||||
int topk,
|
||||
String[] output_fields,
|
||||
DataType[] output_datatypes,
|
||||
String where_expr);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
ArrayList<HashMap<String, Sqlizable>> res = ob.query(tb_name, "c2", "l2",
|
||||
new float[] {0f, 0f, 0f}, 10,
|
||||
new String[] {"c1", "c3", "c2"},
|
||||
new DataType[] {
|
||||
DataType.INT32,
|
||||
DataType.JSON,
|
||||
DataType.FLOAT_VECTOR,
|
||||
"c1 > 0"});
|
||||
if (res != null) {
|
||||
for (int i = 0; i < res.size(); i++) {
|
||||
for (HashMap.Entry<String, Sqlizable> entry : res.get(i).entrySet()) {
|
||||
System.out.printf("%s : %s, ", entry.getKey(), entry.getValue().toString());
|
||||
}
|
||||
System.out.print("\n");
|
||||
}
|
||||
} else {
|
||||
System.out.println("res is null");
|
||||
}
|
||||
```
|
||||
|
||||
### Use the JSON table feature
|
||||
|
||||
The JSON table feature of obvec_jdbc relies on seekdb's ability to handle JSON data types (including `JSON_VALUE`/`JSON_TABLE`/`JSON_REPLACE`, etc.) to implement a virtual table mechanism. Multiple users (distinguished by user ID) can perform DDL or DML operations on virtual tables over the same physical table while ensuring data isolation between users. Admin users can perform DDL operations, while regular users can perform DML operations.
|
||||
|
||||
This design combines the structured management capabilities of relational databases with the flexibility of JSON, showcasing seekdb's multi-model integration capabilities. Users can enjoy the power and ease of use of SQL while also handling semi-structured data, meeting the diverse data model requirements of modern applications. Although operations are still performed on "tables," data is stored in a more flexible JSON format at the underlying level, better supporting complex and varied application scenarios.
|
||||
|
||||
#### How it works
|
||||
|
||||
<!-- The following figure illustrates the principle of JSON Table.
|
||||
|
||||
|
||||
|
||||
Detailed explanation:-->
|
||||
|
||||
1. User operations: Users still interact with the system using familiar standard SQL statements (such as `CREATE TABLE` to create table structures, `INSERT` to insert data, and `SELECT` to query data). They do not need to worry about how data is stored at the underlying level, just like operating ordinary relational database tables. The tables created by users using SQL statements are logical tables, which correspond to two physical tables (`meta_json_t` and `data_json_t`) within seekdb.
|
||||
|
||||
2. JSON Table SDK: Within the application, there is a JSON Table SDK (Software Development Kit). This SDK is the key that connects users' SQL operations and seekdb's actual storage. When SQL statements are executed, the SDK intercepts these requests and intelligently converts them into read and write operations on seekdb's internal tables `meta_json_t` and `data_json_t`.
|
||||
|
||||
3. seekdb internal storage:
|
||||
|
||||
* `meta_json_t` (stores table schema): stores the metadata of the logical tables created by users, which is the schema information of the table (for example, which columns are created and what data type each column is). When `CREATE TABLE` is executed, the SDK records this schema information in `meta_json_t`.
|
||||
* `data_json_t` (stores row data as JSON type): stores the actual inserted data. Unlike traditional relational databases that directly store row data, the JSON Table feature encapsulates each row of inserted data into a JSON object and stores it in a column of the `data_json_t` table. This allows for efficient storage even with flexible data structures.
|
||||
|
||||
4. Data query: When query operations such as `SELECT` are executed, the SDK reads JSON-format data from `data_json_t` and combines it with the schema information from `meta_json_t` to re-parse and present the JSON data in a familiar tabular format, returning it to your application.
|
||||
|
||||
The `meta_json_t` table stores the metadata of the JSON table, which is the logical table schema defined by the user using the `CREATE TABLE` statement. It records the column information of each logical table, with the following schema:
|
||||
|
||||
| Field | Description | Example |
|
||||
|--------|------|------|
|
||||
| `user_id` | The user ID, used to distinguish the logical tables of different users. | `0`, `1`, `2` |
|
||||
| `jtable_name` | The name of the logical table. | `test_count` |
|
||||
| `jcol_id` | The column ID of the logical table. | `1`, `2`, `3` |
|
||||
| `jcol_name` | The column name of the logical table. | `c1`, `c2`, `c3` |
|
||||
| `jcol_type` | The data type of the column. | `INT`, `VARCHAR(124)`, `DECIMAL(10,2)` |
|
||||
| `jcol_nullable` | Indicates whether the column allows null values. | `0`, `1` |
|
||||
| `jcol_has_default` | Indicates whether the column has a default value. | `0`, `1` |
|
||||
| `jcol_default` | The default value of the column. | `{'default': null}` |
|
||||
|
||||
When a user executes the `CREATE TABLE` statement, the JSON table SDK parses and inserts the column definition information into the `meta_json_t` table.
|
||||
|
||||
The `data_json_t` table stores the actual data of the JSON table, which is the data inserted by the user using the `INSERT` statement. It records the row data of each logical table, with the following schema:
|
||||
|
||||
| Field | Description | Example |
|
||||
|--------|------|------|
|
||||
| `user_id` | The user ID, used to distinguish the logical tables of different users. | `0`, `1`, `2` |
|
||||
| `admin_id` | The administrator user ID. | `0` |
|
||||
| `jtable_name` | The name of the logical table, used to associate the metadata in `meta_json_t`. | `test_count` |
|
||||
| `jdata_id` | The data ID, a unique identifier for the JSON data, corresponding to each row in the logical table. | `1`, `2`, `3` |
|
||||
| `jdata` | A column of the JSON type, used to store the actual row data of the logical table. | `{"c1": 1, "c2": "test", "c3": 1.23}` |
|
||||
|
||||
#### Examples
|
||||
|
||||
1. Create a client
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# uri: the connection string, which contains the address, port, and name of the database to which you want to connect.
|
||||
# user: the username.
|
||||
# password: the password.
|
||||
# user_id: the user ID.
|
||||
# log_level: the log level.
|
||||
public ObVecJsonClient(String uri, String user, String password, String user_id, Level log_level);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.ObVecJsonClient;
|
||||
|
||||
String uri = "jdbc:oceanbase://127.0.0.1:2881/test";
|
||||
String user = "root@test";
|
||||
String password = "";
|
||||
ObVecJsonClient client = new ObVecJsonClient(uri, user, password, 0, Level.INFO);
|
||||
```
|
||||
|
||||
2. Execute DDL statements
|
||||
|
||||
You can directly call the `parseJsonTableSQL2NormalSQL` interface and pass in the specific SQL statements.
|
||||
|
||||
* Create a table
|
||||
|
||||
```java
|
||||
String sql = "CREATE TABLE `t2` (c1 INT NOT NULL DEFAULT 10, c2 VARCHAR(30) DEFAULT 'ca', c3 VARCHAR NOT NULL, c4 DECIMAL(10, 2), c5 TIMESTAMP DEFAULT CURRENT_TIMESTAMP);";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE CHANGE COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 CHANGE COLUMN c2 changed_col INT";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE ADD COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 ADD COLUMN email VARCHAR(100) default 'example@example.com'";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE MODIFY COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 MODIFY COLUMN changed_col TIMESTAMP NOT NULL DEFAULT current_timestamp";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE DROP COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 DROP c1";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE RENAME
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 RENAME TO alter_test";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
@@ -0,0 +1,20 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-faq
|
||||
---
|
||||
|
||||
# Vector search FAQs
|
||||
|
||||
This topic describes some common issues that may occur when using vector search, as well as their causes and solutions.
|
||||
|
||||
## Must all rows in a vector column have the same data dimensionality?
|
||||
|
||||
Yes. A data dimensionality must be specified when a vector column is defined, and the dimensionality must be verified when vector data is written into the column.
|
||||
|
||||
## What is the maximum number of rows of vector data that can be written?
|
||||
|
||||
Unlimited. It depends on the database memory resources.
|
||||
|
||||
## How do I create an index on a vector with more than 4096 dimensions?
|
||||
|
||||
You need to compress the data to within 4096 dimensions before creating an index.
|
||||
Reference in New Issue
Block a user