Initial commit
This commit is contained in:
@@ -0,0 +1,84 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-intro
|
||||
---
|
||||
|
||||
# Overview of vector search
|
||||
|
||||
This topic introduces the core concepts of vector databases and vector search.
|
||||
|
||||
seekdb supports dense float vectors with up to 16,000 dimensions, as well as sparse vectors. It supports various types of vector distance calculations, including Manhattan distance, Euclidean distance, inner product, and cosine distance. seekdb also supports the creation of HNSW/IVF-based vector indexes, as well as incremental updates and deletions, with these operations having no impact on recall rate.
|
||||
|
||||
seekdb vector search offers hybrid retrieval capabilities with scalar filtering. It also provides flexible access interfaces: you can use SQL via the MySQL protocol from clients in various programming languages, or access it using a Python SDK. In addition, seekdb is fully adapted to AI application development frameworks such as LlamaIndex, DB-GPT, and the AI application development platform Dify, offering better support for AI application development.
|
||||
|
||||
<video data-code="9002093" src="https://obbusiness-private.oss-cn-shanghai.aliyuncs.com/doc/video/03%20OceanBase%20Vector%20Search-An%20Official%20In-depth%20Perspective.mp4" controls width="811px" height="456.188px"></video>
|
||||
|
||||
## Key concepts
|
||||
|
||||
### Unstructured data
|
||||
|
||||
Unstructured data is data that does not have a predefined data format or organizational structure. It typically includes data in forms such as text, images, audio, and video, as well as social media content, emails, and log files. Due to the complexity and diversity of unstructured data, processing it requires specific tools and techniques, such as natural language processing, image recognition, and machine learning.
|
||||
|
||||
### Vector
|
||||
|
||||
A vector is the projection of an object in a high-dimensional space. Mathematically, a vector is a floating-point array with the following characteristics:
|
||||
|
||||
* Each element in the array is a floating-point number that represents a dimension of the vector.
|
||||
|
||||
* The size, namely, the number of elements, of the vector array indicates the dimensionality of the entire vector space.
|
||||
|
||||
### Vector embedding
|
||||
|
||||
Vector embedding is the process of using a deep learning neural network to extract content and semantics from unstructured data such as images and videos, and convert them into feature vectors. Embedding technology maps original data from a high-dimensional space to a low-dimensional space and converts multimodal data with rich features into multi-dimensional vector data.
|
||||
|
||||
### Vector similarity search
|
||||
|
||||
In today's era of information explosion, users often need to quickly retrieve specific information from massive datasets. Whether it's online literature databases, e-commerce product catalogs, or rapidly growing multimedia content libraries, efficient retrieval systems are essential for locating content of interest. As data volumes continue to grow, traditional keyword-based search methods can no longer meet the demands for both accuracy and speed, giving rise to vector search technology. Vector similarity search uses feature extraction and vectorization techniques to convert unstructured data—such as text, images, and audio—into vectors. By applying similarity measurement methods to compare these vectors, it captures the deeper semantic meaning of the data. This approach delivers more precise and efficient search results, addressing the shortcomings of traditional search methods.
|
||||
|
||||
## Why seekdb vector search?
|
||||
|
||||
seekdb's vector search capabilities are built on its integrated multi-model capabilities, excelling in areas such as hybrid retrieval, high performance, high availability, cost efficiency, and data security.
|
||||
|
||||
### Hybrid retrieval
|
||||
|
||||
seekdb supports hybrid retrieval across multiple data types, including vector data, spatial data, document data, and scalar data. With support for various indexes such as vector indexes, spatial indexes, and full-text indexes, seekdb delivers exceptional performance in multi-model hybrid retrieval. It enables a single database to handle diverse storage and retrieval needs for applications.
|
||||
|
||||
### Scalability
|
||||
|
||||
seekdb vector search supports the storage and retrieval of massive amounts of vector data, meeting the requirements of large-scale vector data applications.
|
||||
|
||||
### High performance
|
||||
|
||||
seekdb vector search capabilities integrate the VSAG indexing algorithm library, which demonstrates outstanding performance on the 960-dimensional GIST dataset. In the ANN-Benchmarks tests, the VSAG library significantly outperformed other algorithms.
|
||||
|
||||
### High availability
|
||||
|
||||
seekdb vector search provides reliable data storage and access capabilities. For in-memory HNSW indexes, it ensures stable retrieval performance.
|
||||
|
||||
### Transactions
|
||||
|
||||
seekdb's transaction capabilities ensure the consistency and integrity of vector data. It also offers effective concurrency control and fault recovery mechanisms.
|
||||
|
||||
### Cost efficiency
|
||||
|
||||
seekdb's storage encoding and compression capabilities significantly reduce the storage space required for vectors, helping to lower application storage costs.
|
||||
|
||||
### Data security
|
||||
|
||||
seekdb already supports comprehensive enterprise-grade security features, including identity authentication and verification, access control, data encryption, monitoring and alerts, and security auditing. These features effectively ensure data security in vector search scenarios.
|
||||
|
||||
### Ease of use
|
||||
|
||||
seekdb vector search provides flexible access interfaces, enabling SQL access through MySQL protocol clients across various programming languages, as well as seamless integration via a Python SDK. Furthermore, seekdb has been optimized for AI application development frameworks like LangChain and LlamaIndex, offering better support for AI application development.
|
||||
|
||||
### Comprehensive toolset
|
||||
|
||||
seekdb features a comprehensive database toolset, supporting data development, migration, operations, diagnostics, and full lifecycle data management, safeguarding the development and maintenance of AI applications.
|
||||
|
||||
## Application scenarios
|
||||
|
||||
* Retrieval-Augmented Generation (RAG): RAG is an artificial intelligence (AI) framework that retrieves facts from external knowledge bases to provide the most accurate and latest information for Large Language Models (LLMs) and allow users to have an insight into the generation process of an LLM. RAG is commonly used in intelligent Q&A systems and knowledge bases.
|
||||
|
||||
* Personalized recommendation: The recommendation system can recommend items that users may be interested in based on their historical behavior and preferences. When a recommendation request is initiated, the system will calculate the similarity based on the characteristics of the user, and then return items that the user may be interested in as the recommendation results, such as recommended restaurants and scenic spots.
|
||||
|
||||
* Image search/Text search: An image/text search task aims to find results that are most similar to the specified image in a large-scale image/text database. The text/image features used in the search can be stored in a vector database, and efficient similarity calculation can be achieved based on high-performance index-based storage, thereby returning image/text results that match the search criteria. This applies to scenarios such as facial recognition.
|
||||
@@ -0,0 +1,28 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-workflow
|
||||
---
|
||||
|
||||
# AI application workflow using seekdb vector search
|
||||
|
||||
This topic describes the AI application workflow using seekdb vector search.
|
||||
|
||||
## Convert unstructured data into feature vectors through vector embedding
|
||||
|
||||
Unstructured data (such as videos, documents, and images) is the starting point of the entire workflow. Various forms of unstructured data, including videos, text files (documents), and images, are transformed into vector representations through vector embedding models. The task of these models is to convert raw, unstructured data that is difficult to directly calculate similarity into high-dimensional vector data. These vectors capture the semantic information and features of the data, and can express the similarity of data through distances in the vector space. For more information, see [Vector embedding technology](../150.vector-embedding-technology.md).
|
||||
|
||||
## Store vector embeddings and create vector indexes in seekdb
|
||||
|
||||
As the core storage layer, seekdb is responsible for storing all data. This includes traditional relational tables (used for storing business data), the original unstructured data, and the vector data generated after vector embedding. For more information, see [Store vector data](../160.store-vector-data.md).
|
||||
|
||||
To enable efficient vector search, seekdb internally builds vector indexes for the vector data. Vector indexes are specialized data structures that significantly accelerate nearest neighbor searches in high-dimensional vector spaces. Since calculating vector similarity is computationally expensive, exact searches (calculating distances for all vectors one by one) ensure accuracy but can severely impact query performance. Through vector indexes, the system can quickly locate candidate vectors, significantly reducing the number of vectors that need distance calculations, thereby improving query efficiency while maintaining high accuracy. For more information, see [Create vector indexes](../200.vector-index/200.dense-vector-index.md).
|
||||
|
||||
## Perform nearest neighbor search and hybrid search through SQL/SDK
|
||||
|
||||
Users interact with the AI application through clients or programming languages by submitting queries that may involve text, images, or other formats. For more information, see [Supported clients and languages](../700.vector-search-reference/900.vector-search-supported-clients-and-languages/100.vector-search-supported-clients-and-languages-overview.md).
|
||||
|
||||
seekdb uses SQL statements to query and manage relational data, enabling hybrid searches that combine scalar and vector data. When a user initiates a query—if it is unstructured—the system first converts it into a vector using the embedding model. Then, leveraging both vector and scalar indexes, the system quickly retrieves the most similar vectors that also meet scalar filter conditions, thus identifying the most relevant unstructured data. For detailed information about nearest neighbor search, see [Nearest neighbor search](../300.vector-similarity-search.md).
|
||||
|
||||
## Generate prompts and send them to the LLM for inference
|
||||
|
||||
In the final stage, an optimized prompt is generated based on the hybrid search results and sent to the large language model (LLM) to complete the inference process. The LLM generates a natural language response based on this contextual information. There is a feedback loop between the LLM and the vector embedding model, meaning that the output of the LLM or user feedback can be used to optimize the embedding model, creating a cycle of continuous learning and improvement.
|
||||
@@ -0,0 +1,339 @@
|
||||
---
|
||||
|
||||
slug: /vector-embedding-technology
|
||||
---
|
||||
|
||||
# Vector embedding technology
|
||||
|
||||
This topic introduces vector embedding technology in vector retrieval.
|
||||
|
||||
## What is vector embedding?
|
||||
|
||||
Vector embedding is a technique for converting unstructured data into numerical vectors. These vectors can capture the semantic information of unstructured data, enabling computers to "understand" and process the meaning of such data. Specifically:
|
||||
|
||||
* Vector embedding maps unstructured data such as text, images, or audio/video to points in a high-dimensional vector space.
|
||||
|
||||
* In this vector space, semantically similar unstructured data is mapped to nearby locations.
|
||||
|
||||
* Vectors are typically composed of hundreds of numbers (such as 512 or 1024 dimensions).
|
||||
|
||||
* Mathematical methods (such as cosine similarity) can be used to calculate the similarity between vectors.
|
||||
|
||||
* Common vector embedding models include Word2Vec, BERT, and BGE. For example, when developing RAG applications, text data is often embedded into vector data and stored in a vector database, while other structured data is stored in a relational database.
|
||||
|
||||
In seekdb, vector data can be stored as a data type in a relational table, allowing vectors and traditional scalar data to be stored in an orderly and efficient manner within seekdb.
|
||||
|
||||
## Generate vector embeddings using AI function service in seekdb
|
||||
|
||||
In seekdb, you can use the AI function service to generate vector embeddings. Users do not need to install any dependencies. After registering the model information, you can use the AI function service to generate vector embeddings in seekdb. For details, see [AI function service usage and examples](../300.ai-function/200.ai-function.md).
|
||||
|
||||
## Common text embedding methods
|
||||
|
||||
This section introduces common text embedding methods.
|
||||
|
||||
### Prerequisites
|
||||
|
||||
You need to have the `pip` command installed in advance.
|
||||
|
||||
### Use an offline, locally pre-trained embedding model
|
||||
|
||||
Using pre-trained models for local text embedding is the most flexible approach, but it requires significant computing resources. Commonly used models include:
|
||||
|
||||
#### Use Sentence Transformers
|
||||
|
||||
Sentence Transformers is an NLP model designed to convert sentences or paragraphs into vector embeddings. It uses deep learning technology, particularly the Transformer architecture, to effectively capture the semantic information of text. Since direct access to Hugging Face's domain often times out in China, please set the Hugging Face mirror address `export HF_ENDPOINT=https://hf-mirror.com` in advance. After setting it, run the code below:
|
||||
|
||||
```shell
|
||||
from sentence_transformers import SentenceTransformer
|
||||
|
||||
model = SentenceTransformer("BAAI/bge-m3")
|
||||
|
||||
sentences = [
|
||||
"That is a happy person",
|
||||
"That is a happy dog",
|
||||
"That is a very happy person",
|
||||
"Today is a sunny day"
|
||||
]
|
||||
embeddings = model.encode(sentences)
|
||||
print(embeddings)
|
||||
# [[-0.01178016 0.00884024 -0.05844684 ... 0.00750248 -0.04790139
|
||||
# 0.00330675]
|
||||
# [-0.03470375 -0.00886354 -0.05242309 ... 0.00899352 -0.02396279
|
||||
# 0.02985837]
|
||||
# [-0.01356584 0.01900942 -0.05800966 ... 0.00523864 -0.05689549
|
||||
# 0.00077098]
|
||||
# [-0.02149693 0.02998871 -0.05638731 ... 0.01443702 -0.02131325
|
||||
# -0.00112451]]
|
||||
similarities = model.similarity(embeddings, embeddings)
|
||||
print(similarities.shape)
|
||||
# torch.Size([4, 4])
|
||||
```
|
||||
|
||||
#### Use Hugging Face Transformers
|
||||
|
||||
Hugging Face Transformers is an open-source library that provides a wide range of pre-trained deep learning models, especially for NLP tasks. Due to geographical reasons, direct access to Hugging Face's domain may time out. Please set the Hugging Face mirror address `export HF_ENDPOINT=https://hf-mirror.com` in advance. After setting it, run the code below:
|
||||
|
||||
```shell
|
||||
from transformers import AutoTokenizer, AutoModel
|
||||
import torch
|
||||
|
||||
# Load the model and tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained("BAAI/bge-m3")
|
||||
model = AutoModel.from_pretrained("BAAI/bge-m3")
|
||||
|
||||
# Prepare the input
|
||||
texts = ["This is an example text."]
|
||||
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
|
||||
|
||||
# Generate embeddings
|
||||
with torch.no_grad():
|
||||
outputs = model(**inputs)
|
||||
embeddings = outputs.last_hidden_state[:, 0] # Use the [CLS] token's output
|
||||
print(embeddings)
|
||||
# tensor([[-1.4136, 0.7477, -0.9914, ..., 0.0937, -0.0362, -0.1650]])
|
||||
print(embeddings.shape)
|
||||
# torch.Size([1, 1024])
|
||||
```
|
||||
|
||||
#### Ollama
|
||||
|
||||
[Ollama](https://ollama.com) is an open-source model runtime that allows users to easily run, manage, and use various large language models locally. In addition to supporting open-source language models like Llama 3 and Mistral, it also supports embedding models like bge-m3.
|
||||
|
||||
1. Deploy Ollama
|
||||
|
||||
On MacOS and Windows, you can directly download and install the package from the official website. For installation instructions, refer to Ollama's official website. After installation, Ollama runs as a background service.
|
||||
|
||||
To install Ollama on Linux:
|
||||
|
||||
```shell
|
||||
curl -fsSL https://ollama.ai/install.sh | sh
|
||||
```
|
||||
|
||||
2. Pull an embedding model
|
||||
|
||||
Ollama supports using the bge-m3 model for text embeddings:
|
||||
|
||||
```shell
|
||||
ollama pull bge-m3
|
||||
```
|
||||
|
||||
3. Use Ollama for text embeddings
|
||||
|
||||
You can use Ollama's embedding capabilities through HTTP API or Python SDK:
|
||||
|
||||
* HTTP API
|
||||
|
||||
```shell
|
||||
import requests
|
||||
|
||||
def get_embedding(text: str) -> list:
|
||||
"""Get text embeddings using Ollama's HTTP API"""
|
||||
response = requests.post(
|
||||
'http://localhost:11434/api/embeddings',
|
||||
json={
|
||||
'model': 'bge-m3',
|
||||
'prompt': text
|
||||
}
|
||||
)
|
||||
return response.json()['embedding']
|
||||
|
||||
# Example usage
|
||||
text = "This is an example text."
|
||||
embedding = get_embedding(text)
|
||||
print(embedding)
|
||||
# [-1.4269912242889404, 0.9092104434967041, ...]
|
||||
```
|
||||
|
||||
* Python SDK
|
||||
|
||||
First, install Ollama's Python SDK:
|
||||
|
||||
```shell
|
||||
pip install ollama
|
||||
```
|
||||
|
||||
Then you can use it like this:
|
||||
|
||||
```shell
|
||||
import ollama
|
||||
|
||||
# Example usage
|
||||
texts = ["First sentence", "Second sentence"]
|
||||
embeddings = ollama.embed(model="bge-m3", input=texts)['embeddings']
|
||||
print(embeddings)
|
||||
# [[0.03486196, 0.0625187, ...], [...]]
|
||||
```
|
||||
|
||||
4. Advantages and limitations of Ollama
|
||||
|
||||
Advantages:
|
||||
|
||||
* Fully local deployment, no internet connection required
|
||||
* Open-source and free, no API Key required
|
||||
* Supports multiple models, easy to switch and compare
|
||||
* Relatively low resource usage
|
||||
|
||||
Limitations:
|
||||
|
||||
* Limited selection of embedding models
|
||||
* Performance may not match commercial services
|
||||
* Requires self-maintenance and updates
|
||||
* Lacks enterprise-level support
|
||||
|
||||
When choosing whether to use Ollama, you need to weigh these factors. If your application scenario has high privacy requirements, or you want to run completely offline, Ollama is a good choice. However, if you need more stable service quality and better performance, you may need to consider commercial services.
|
||||
|
||||
<!-- ### Use online, remote embedding services
|
||||
|
||||
Using offline, local embedding models usually requires high hardware specifications for the deployment machine and also demands advanced management of processes such as model loading and unloading. As a result, many users have a strong need for online embedding services. Currently, many AI inference service providers offer corresponding text embedding services. Taking Tongyi Qwen's text embedding service as an example, you can first register for an account with [Alibaba Cloud Model Studio](https://bailian.console.aliyun.com) and obtain an API Key. Then, you can call its public API to get text embeddings.
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
-->
|
||||
|
||||
#### HTTP call
|
||||
|
||||
After obtaining the credentials, you can try performing text embedding with the following code. If the requests package is not installed in your Python environment, you need to install it first with `pip install requests` to enable sending network requests.
|
||||
|
||||
```shell
|
||||
import requests
|
||||
from typing import List
|
||||
|
||||
class RemoteEmbedding():
|
||||
def __init__(
|
||||
self,
|
||||
base_url: str,
|
||||
api_key: str,
|
||||
model: str,
|
||||
dimensions: int = 1024,
|
||||
**kwargs,
|
||||
):
|
||||
self._base_url = base_url
|
||||
self._api_key = api_key
|
||||
self._model = model
|
||||
self._dimensions = dimensions
|
||||
|
||||
"""
|
||||
OpenAI compatible embedding API. Tongyi, Baichuan, Doubao, etc.
|
||||
"""
|
||||
|
||||
def embed_documents(
|
||||
self,
|
||||
texts: List[str],
|
||||
) -> List[List[float]]:
|
||||
"""Embed search docs.
|
||||
|
||||
Args:
|
||||
texts: List of text to embed.
|
||||
|
||||
Returns:
|
||||
List of embeddings.
|
||||
"""
|
||||
res = requests.post(
|
||||
f"{self._base_url}",
|
||||
headers={"Authorization": f"Bearer {self._api_key}"},
|
||||
json={
|
||||
"input": texts,
|
||||
"model": self._model,
|
||||
"encoding_format": "float",
|
||||
"dimensions": self._dimensions,
|
||||
},
|
||||
)
|
||||
data = res.json()
|
||||
embeddings = []
|
||||
try:
|
||||
for d in data["data"]:
|
||||
embeddings.append(d["embedding"][: self._dimensions])
|
||||
return embeddings
|
||||
except Exception as e:
|
||||
print(data)
|
||||
print("Error", e)
|
||||
raise e
|
||||
|
||||
def embed_query(self, text: str, **kwargs) -> List[float]:
|
||||
"""Embed query text.
|
||||
|
||||
Args:
|
||||
text: Text to embed.
|
||||
|
||||
Returns:
|
||||
Embedding.
|
||||
"""
|
||||
return self.embed_documents([text])[0]
|
||||
|
||||
embedding = RemoteEmbedding(
|
||||
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings",
|
||||
api_key="your-api-key", # Enter your API Key
|
||||
model="text-embedding-v3",
|
||||
)
|
||||
|
||||
print("Embedding result:", embedding.embed_query("The weather is nice today"), "\n")
|
||||
# Embedding result: [-0.03573227673768997, 0.0645645260810852, ...]
|
||||
print("Embedding results:", embedding.embed_documents(["The weather is nice today", "What about tomorrow?"]), "\n")
|
||||
# Embedding results: [[-0.03573227673768997, 0.0645645260810852, ...], [-0.05443647876381874, 0.07368793338537216, ...]]
|
||||
```
|
||||
|
||||
#### Use Qwen SDK
|
||||
|
||||
Qwen provides an SDK called dashscope for quickly accessing model capabilities. After installing it using `pip install dashscope`, you can obtain text embeddings.
|
||||
|
||||
```shell
|
||||
import dashscope
|
||||
from dashscope import TextEmbedding
|
||||
|
||||
# Set the API Key
|
||||
dashscope.api_key = "your-api-key"
|
||||
|
||||
# Prepare the input text
|
||||
texts = ["This is the first sentence", "This is the second sentence"]
|
||||
|
||||
# Call the embedding service
|
||||
response = TextEmbedding.call(
|
||||
model="text-embedding-v3",
|
||||
input=texts
|
||||
)
|
||||
|
||||
# Get the embedding results
|
||||
if response.status_code == 200:
|
||||
print(response.output['embeddings'])
|
||||
# [{"embedding": [-0.03193652629852295, 0.08152323216199875, ...]}, {"embedding": [...]}]
|
||||
```
|
||||
|
||||
## Common image embedding methods
|
||||
|
||||
This section introduces image embedding methods.
|
||||
|
||||
### Use an offline, locally pre-trained embedding model
|
||||
|
||||
#### Use CLIP
|
||||
|
||||
CLIP (Contrastive Language-Image Pretraining) is a model proposed by OpenAI for multimodal learning by combining images and text. CLIP can understand and process the relationships between images and text, making it perform well in various tasks such as image classification, image retrieval, and text generation.
|
||||
|
||||
```shell
|
||||
from PIL import Image
|
||||
from transformers import CLIPProcessor, CLIPModel
|
||||
|
||||
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
|
||||
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
|
||||
|
||||
# Prepare the input image
|
||||
image = Image.open("path_to_your_image.jpg")
|
||||
texts = ["This is the first sentence", "This is the second sentence"]
|
||||
|
||||
# Call the embedding service
|
||||
inputs = processor(text=texts, images=image, return_tensors="pt", padding=True)
|
||||
outputs = model(**inputs)
|
||||
|
||||
# Obtain the embedding results
|
||||
if outputs.status_code == 200:
|
||||
print(outputs.output['embeddings'])
|
||||
# [{"embedding": [-0.03193652629852295, 0.08152323216199875, ...]}, {"embedding": [...]}]
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Store vector embeddings](160.store-vector-data.md)
|
||||
* [Vector data types](700.vector-search-reference/100.vector-data-type.md)
|
||||
@@ -0,0 +1,50 @@
|
||||
---
|
||||
|
||||
slug: /store-vector-data
|
||||
---
|
||||
|
||||
# Store vector data
|
||||
|
||||
This topic introduces how to store unstructured, semi-structured, and structured data in a unified way within seekdb. This not only fully leverages the foundational capabilities of seekdb, but also provides strong support for hybrid search.
|
||||
|
||||
## How it works
|
||||
|
||||
seekdb can store data of different modalities and supports hybrid search by converting various types of data (such as text, images, and videos) into vectors. Searches are performed by calculating the distances between these vectors. Hybrid search can be divided into two types: simple search, which is based on similarity search for a single vector, and complex search, which involves combining vector and scalar searches.
|
||||
|
||||
Since vector search is inherently approximate, it is necessary to employ multiple techniques in practical applications to improve accuracy. Only precise search results can deliver greater value to your business.
|
||||
|
||||
## Create a vector column
|
||||
|
||||
The following example shows a table that stores vector data, spatial data, and relational data. The data type of the vector column is `VECTOR`, and the dimension must be specified when the column is created. The maximum supported dimension is 16,000. The data type of the spatial column is `GEOMETRY`:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t (
|
||||
-- Store relational data (structured data).
|
||||
id INT PRIMARY KEY,
|
||||
-- Store spatial data (semi-structured data).
|
||||
g GEOMETRY,
|
||||
-- Store vector data (unstructured data).
|
||||
vec VECTOR(3)
|
||||
);
|
||||
```
|
||||
|
||||
|
||||
## Use the `INSERT` statement to insert vector data
|
||||
|
||||
Once you create a table that contains a column of the `VECTOR` data type, you can directly use the `INSERT` statement to insert vectors into the table. When you insert data, the vector must match the dimension specified when the table is created. Otherwise, an error will be returned. This design ensures data consistency and query efficiency. Vectors are represented in standard floating-point number arrays. Each dimension must have a valid floating-point number. Here is a simple example:
|
||||
|
||||
```sql
|
||||
INSERT INTO t (id, g, vec) VALUES (
|
||||
-- Insert structured data.
|
||||
1,
|
||||
-- Insert semi-structured data.
|
||||
ST_GeomFromText('POINT(1 1)'),
|
||||
-- Insert unstructured data.
|
||||
'[0.1, 0.2, 0.3]'
|
||||
);
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Vector embedding technology](150.vector-embedding-technology.md)
|
||||
* [Create vector indexes](200.vector-index/200.dense-vector-index.md)
|
||||
@@ -0,0 +1,600 @@
|
||||
---
|
||||
|
||||
slug: /dense-vector-index
|
||||
---
|
||||
|
||||
# Dense vector index
|
||||
|
||||
This topic describes how to create, query, maintain, and drop a dense vector index in seekdb.
|
||||
|
||||
## Index types
|
||||
|
||||
The following table describes the vector index types supported by seekdb.
|
||||
|
||||
| Index type | Description | Scenarios |
|
||||
|-----------|------|----------|
|
||||
| HNSW | The maximum dimension of indexed columns is 4096. The HNSW index is a memory-based index that must be fully loaded into memory. It supports DML and real-time queries. | |
|
||||
| HNSW_SQ | The HNSW_SQ index offers similar construction speed, query performance, and recall rate as the HNSW index, but reduces overall memory usage to 1/2 to 1/3 of the original. | Scenarios with high performance and recall rate requirements. |
|
||||
| HNSW_BQ | The HNSW_BQ index has a slightly lower recall rate compared to the HNSW index, but significantly reduces memory usage. The BQ quantization compression algorithm (Rabitq) can compress vectors to 1/32 of their original size. The memory optimization effect of the HNSW_BQ index becomes more pronounced as the vector dimension increases. | |
|
||||
| IVF| An IVF index implemented based on database tables, which does not require resident memory. | Scenarios with lower performance requirements but large data volumes and cost sensitivity. |
|
||||
| IVF_PQ| An IVF_PQ index implemented based on database tables, which does not require resident memory. On top of IVF, PQ quantization technology is applied. The recall rate of the index is slightly lower than that of the IVF index, but the performance is higher. The PQ quantization compression algorithm can generally compress vectors to 1/16 to 1/32 of their original size. | Scenarios with lower performance requirements but large data volumes and cost sensitivity. |
|
||||
| IVF_SQ (Experimental feature)| An IVF_SQ index implemented based on database tables, which does not require resident memory. On top of IVF, SQ quantization technology is applied. The recall rate of the index is slightly lower than that of the IVF index, but the performance is higher. The SQ quantization compression algorithm can generally compress vectors to 1/3 to 1/4 of their original size. | Scenarios with lower performance requirements but large data volumes and cost sensitivity. |
|
||||
|
||||
Some other notes:
|
||||
|
||||
* Dense vector indexes support L2, inner product (IP), and cosine distance as the index distance algorithm.
|
||||
* Vector index queries support calling some distance functions. For more information, see [Use SQL functions](../250.vector-function.md).
|
||||
* Vector queries with filter conditions are supported. The filter conditions can be scalar conditions or spatial relationships, such as ST_Intersects. Multi-value indexes, full-text indexes, and global indexes are not supported as pre-filterers.
|
||||
* You can create vector and full-text indexes on the same table.
|
||||
* For more information about how vector indexes support offline DDL operations, see [Offline DDL](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974221).
|
||||
|
||||
The limitations are described as follows:
|
||||
|
||||
* For V1.0.0, creating columnstore vector indexes is currently not supported.
|
||||
|
||||
## Index memory estimation and actual usage query
|
||||
|
||||
You can estimate the memory required for vector indexes using the `DBMS_VECTOR` system package:
|
||||
|
||||
* Before creating a table, you can estimate index memory requirements by using the [INDEX_VECTOR_MEMORY_ADVISOR](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754002) procedure.
|
||||
* After a table is created and data is inserted, you can estimate index memory requirements by using the [INDEX_VECTOR_MEMORY_ESTIMATE](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754001) procedure.
|
||||
|
||||
The vector index memory estimation provides two key pieces of information: the minimum memory configuration required to create a vector index, and the actual memory usage after creating HNSW_SQ and IVF indexes.
|
||||
|
||||
We also provide the configuration item `load_vector_index_on_follower` to control whether the follower role automatically loads in-memory vector indexes. For syntax and examples, see [load_vector_index_on_follower](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002969407). If weak reads are not needed, you can disable this configuration item to reduce the memory used by vector indexes.
|
||||
|
||||
## Creation syntax and description
|
||||
|
||||
seekdb vector indexes can be created during table creation or after the table is created. When creating a vector index, note the following:
|
||||
|
||||
* The `VECTOR` keyword is required when creating a vector index.
|
||||
* The parameters and descriptions for an index created after the table is created are the same as those for an index created during table creation.
|
||||
* If a large amount of data is involved, we recommend that you write the data first and then create the index to achieve the optimal query performance.
|
||||
* It is recommended to create HNSW_SQ, IVF, IVF_SQ, and IVF_PQ indexes after data is inserted, and to rebuild the indexes after a significant amount of new data is added. For detailed instructions on creating each index, see the specific examples below.
|
||||
|
||||
:::tab
|
||||
tab HNSW/HNSW_SQ/HNSW_BQ
|
||||
|
||||
Syntax for creating an index during table creation:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 data_type1,
|
||||
column_name2 data_type2,
|
||||
...,
|
||||
VECTOR INDEX index_name (column_name) WITH (param1=value1, param2=value2, ...)
|
||||
);
|
||||
```
|
||||
|
||||
Syntax for creating an index after table creation:
|
||||
|
||||
```sql
|
||||
-- Creating an index after table creation supports setting parallel degree to improve index construction performance. The maximum parallel degree should not exceed CPU cores * 2
|
||||
CREATE [/*+ paralell $value*/] VECTOR INDEX index_name ON table_name(column_name) WITH (param1=value1, param2=value2, ...);
|
||||
```
|
||||
|
||||
`param` parameter description:
|
||||
|
||||
| Parameter | Default value | Value range | Required | Description | Remarks |
|
||||
|------|--------|----------|----------|------|------|
|
||||
| distance | | l2/inner_product/cosine | Yes | The vector distance function type. | l2 indicates the Euclidean distance, inner_product indicates the inner product distance, and cosine indicates the cosine distance. |
|
||||
| type | | currently supported `hnsw` / `hnsw_sq`/ `hnsw_bq`. | Yes | The index type. | |
|
||||
| lib | vsag | vsag | No | The vector index library type. | At present, only the VSAG vector library is supported. |
|
||||
| m | 16 | [5,128] | No | The maximum number of neighbors of each node. | The larger the value, the slower the index construction, but the better the query performance. |
|
||||
| ef_construction | 200 | [5,1000] | No | The size of the candidate set during index construction. | The larger the value, the slower the index construction, but the better the index quality. `ef_construction` must be greater than `m`. |
|
||||
| ef_search | 64 | [1,1000] | No | The size of the candidate set during a query. | The larger the value, the slower the query, but the higher the recall rate. |
|
||||
| extra_info_max_size | 0 | [0,16384] | No | The maximum size of each primary key information (in bytes). Storing the primary key of the table in the index can speed up queries. | <code>0</code>: The primary key information is not stored.<br/><code>1</code>: The primary key information is forcibly stored, regardless of the size limit. In this case, the primary key type (see below) must be a supported type.<br/><code>Greater than 1</code>: The maximum size of the primary key information (in bytes) is specified. In this case, the following conditions must be met:<ul><li>The size of the primary key information (calculation method see below) must be less than the specified size limit.</li><li>The primary key type must be a supported type.</li><li>The table is not a table without a primary key.</li></ul> |
|
||||
| refine_k | 4.0 | [1.0,1000.0] | No | <main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an HNSW_BQ index. </p></main> This parameter is a floating-point number used to adjust the rearrangement ratio for quantized vector indexes. | This parameter can be specified when you create an index or during a query:<ul><li>If this parameter is not specified during a query, the value specified when the index is created is used. </li><li>If this parameter is specified during a query, the value specified during the query is used. </li></ul> |
|
||||
| refine_type | sq8 <main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an HNSW_BQ index. </p></main> This parameter specifies the construction precision of quantized vector indexes. | This parameter improves the efficiency of index construction by reducing the memory usage and the construction time, but may affect the recall rate. |
|
||||
| bq_bits_query | 32 | 0/4/32 | No | <main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an HNSW_BQ index. </p></main> This parameter specifies the query precision of quantized vector indexes in bits. | This parameter improves the efficiency of index construction by reducing the memory usage and the construction time, but may affect the recall rate. |
|
||||
| bq_use_fht | true <main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an HNSW_BQ index. </p></main> This parameter specifies whether to use FHT for queries. FHT (Fast Hadamard Transform) is an algorithm used to accelerate vector inner product calculations. | |
|
||||
|
||||
The supported primary key types for `extra_info_max_size` include:
|
||||
|
||||
* [Numeric types](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001975803): Integer types, floating-point types, and BIT_VALUE types.
|
||||
* [Datetime types](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001975805)
|
||||
* [Character types](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001975810): VARCHAR type is supported.
|
||||
|
||||
The calculation method for the primary key information size:
|
||||
|
||||
```sql
|
||||
SET @table_name = 'test'; -- Replace this with the table name to be queried.
|
||||
|
||||
SELECT
|
||||
CASE
|
||||
WHEN COUNT(*) <> COUNT(result_value) THEN 'not support'
|
||||
ELSE COALESCE(SUM(result_value), 'not support')
|
||||
END AS extra_info_size
|
||||
FROM (
|
||||
SELECT
|
||||
CASE
|
||||
WHEN vdt.data_type_class IN (1, 2, 3, 4, 6, 8, 9, 14, 27, 28) THEN 8 -- For numeric types, extra_info_size += 8
|
||||
WHEN oc.data_type = 22 THEN oc.data_length -- For varchar types, extra_info_size += data_length
|
||||
ELSE NULL -- Other types are not supported
|
||||
END AS result_value
|
||||
FROM
|
||||
oceanbase.__all_column oc
|
||||
JOIN
|
||||
oceanbase.__all_virtual_data_type vdt
|
||||
ON
|
||||
oc.data_type = vdt.data_type
|
||||
WHERE
|
||||
oc.rowkey_position != 0
|
||||
AND oc.table_id = (SELECT table_id FROM oceanbase.__all_table WHERE table_name = @table_name)
|
||||
) AS result_table;
|
||||
|
||||
-- The result is 8 bytes.
|
||||
```
|
||||
|
||||
tab IVF/IVF_SQ (Experimental feature)/IVF_PQ
|
||||
|
||||
Syntax for creating an index during table creation:
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 data_type1,
|
||||
column_name2 data_type2,
|
||||
...,
|
||||
VECTOR INDEX index_name (column_name) WITH (param1=value1, param2=value2, ...)
|
||||
);
|
||||
```
|
||||
|
||||
Syntax for creating an index after table creation:
|
||||
|
||||
```sql
|
||||
-- Creating an index after table creation supports setting parallel degree to improve index construction performance. The maximum parallel degree should not exceed CPU cores * 2
|
||||
CREATE [/*+ paralell $value*/] VECTOR INDEX index_name ON table_name(column_name) WITH (param1=value1, param2=value2, ...);
|
||||
```
|
||||
|
||||
`param` parameter description:
|
||||
|
||||
| Parameter | Default value | Value range | Required? | Description | Remarks |
|
||||
|------|--------|----------|----------|------|------|
|
||||
| distance | | l2/inner_product/cosine | Yes | The vector distance function type. | l2 indicates the Euclidean distance, inner_product indicates the inner product distance, and cosine indicates the cosine distance. |
|
||||
| type | | ivf_flat/ivf_sq8/ivf_pq | Yes | The IVF index type. | |
|
||||
| lib | ob | ob | No | The vector index library type. | |
|
||||
| nlist | 128 | [1,65536] | No | The number of clusters. | |
|
||||
| sample_per_nlist | 256 | [1,int64_max] | Yes | The number of samples for each cluster center, which is used when creating an index after table creation. | |
|
||||
| nbits | 8 | [1,24] | No | The number of quantization bits.<main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an IVF_PQ index.</p></main> | The recommended value is 8. The recommended value range is [8,10]. The larger the value, the higher the quantization accuracy and query accuracy, but the query performance will be affected. |
|
||||
| m | No default value, must be specified | [1,65536] | Yes | The dimension of the quantized vectors.<main id="notice" type="notice"><p>This parameter is supported starting from V1.0.0. You can specify this parameter only when you create an IVF_PQ index.</p></main> | The larger the value, the slower the index construction, and the higher the query accuracy, but the query performance will be affected. |
|
||||
|
||||
:::
|
||||
|
||||
## Query syntax and description
|
||||
|
||||
Vector index queries are approximate nearest neighbor queries and do not guarantee 100% accuracy. The accuracy of vector queries is measured by recall. For example, if a query for the 10 nearest neighbors can stably return 9 correct results, the recall is 90%. The recall is described as follows:
|
||||
|
||||
* The recall is affected by the build parameters and query parameters.
|
||||
* The index query parameters are specified when the index is created and cannot be modified. However, you can set session variables to specify the parameters. The `ob_hnsw_ef_search` variable specifies the parameters for the HNSW/HNSW_SQ/HNSW_BQ index, and the `ob_ivf_nprobes` variable specifies the parameters for the IVF index. If you set a session variable, its value is prioritized. For more information, see [ob_hnsw_ef_search](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001976680) and [ob_ivf_nprobes](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002179539).
|
||||
|
||||
The syntax for dense vector indexes is as follows:
|
||||
|
||||
```sql
|
||||
SELECT ... FROM $table_name ORDER BY $distance_function($column_name, $vector_expr) [APPROXIMATE|APPROX] LIMIT $num (OFFSET $num);
|
||||
```
|
||||
|
||||
Query usage notes are as follows:
|
||||
|
||||
* Syntax requirements:
|
||||
* The `APPROXIMATE`/`APPROX` keyword must be specified for the query to use the vector index instead of a full table scan.
|
||||
* The query must include the `ORDER BY` and `LIMIT` clauses.
|
||||
* The `ORDER BY` clause only supports a single vector condition.
|
||||
* The value of `LIMIT + OFFSET` must be in the range `(0, 16384]`.
|
||||
|
||||
* Rules for distance functions:
|
||||
* If `APPROXIMATE`/`APPROX` is specified, a supported distance function is called, and it matches the vector index algorithm, the query will use the vector index.
|
||||
* If `APPROXIMATE`/`APPROX` is specified, but the distance function does not match the vector index algorithm, the query will not use the vector index, but no error is returned.
|
||||
* If `APPROXIMATE`/`APPROX` is specified, but the distance function is not supported in the current version, the query will not use the vector index, and an error is returned.
|
||||
* If `APPROXIMATE`/`APPROX` is not specified, and a supported distance function is called, the query will not use the vector index, but no error is returned.
|
||||
|
||||
* Other notes:
|
||||
* The `WHERE` condition will serve as a filter after the vector index query.
|
||||
* Specifying the `LIMIT` clause is required; otherwise, an error will be returned.
|
||||
|
||||
## Create, query, and delete examples
|
||||
|
||||
### Create an index during table creation
|
||||
|
||||
#### Example of dense vector index
|
||||
|
||||
##### HNSW example
|
||||
|
||||
:::tip
|
||||
|
||||
When you create an HNSW index, the index name must be less than 25 characters in length. Otherwise, an exception may occur because the auxiliary table name exceeds the <code>index_name</code> limit. In future versions, the index name can be longer.
|
||||
:::
|
||||
|
||||
Create a test table.
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1(c1 INT, c0 INT, c2 VECTOR(10), c3 VECTOR(10), PRIMARY KEY(c1), VECTOR INDEX idx1(c2) WITH (distance=l2, type=hnsw, lib=vsag), VECTOR INDEX idx2(c3) WITH (distance=l2, type=hnsw, lib=vsag));
|
||||
```
|
||||
|
||||
Write test data.
|
||||
|
||||
```sql
|
||||
INSERT INTO t1 VALUES(1, 1,'[0.203846,0.205289,0.880265,0.824340,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833]', '[0.203846,0.205289,0.880265,0.824340,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833]');
|
||||
|
||||
INSERT INTO t1 VALUES(2, 2, '[0.735541,0.670776,0.903237,0.447223,0.232028,0.659316,0.765661,0.226980,0.579658,0.933939]', '[0.213846,0.205289,0.880265,0.824340,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833]');
|
||||
|
||||
INSERT INTO t1 VALUES(3, 3, '[0.327936,0.048756,0.084670,0.389642,0.970982,0.370915,0.181664,0.940780,0.013905,0.628127]', '[0.223846,0.205289,0.880265,0.824340,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833]');
|
||||
```
|
||||
|
||||
Perform an approximate nearest neighbor query.
|
||||
|
||||
```sql
|
||||
SELECT * FROM t1 ORDER BY l2_distance(c2, [0.712338,0.603321,0.133444,0.428146,0.876387,0.763293,0.408760,0.765300,0.560072,0.900498]) APPROXIMATE LIMIT 1;
|
||||
```
|
||||
|
||||
The query result is as follows:
|
||||
|
||||
```shell
|
||||
+----+------+-------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------+
|
||||
| c1 | c0 | c2 | c3 |
|
||||
+----+------+-------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------+
|
||||
| 3 | 3 | [0.327936,0.048756,0.08467,0.389642,0.970982,0.370915,0.181664,0.94078,0.013905,0.628127] | [0.223846,0.205289,0.880265,0.82434,0.615737,0.496899,0.983632,0.865571,0.248373,0.542833] |
|
||||
+----+------+-------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
##### HNSW_SQ example
|
||||
|
||||
```sql
|
||||
CREATE TABLE t2 (c1 INT AUTO_INCREMENT, c2 VECTOR(3), PRIMARY KEY(c1), VECTOR INDEX idx1(c2) WITH (distance=l2, type=hnsw_sq, lib=vsag));
|
||||
```
|
||||
|
||||
##### HNSW_BQ example
|
||||
|
||||
```sql
|
||||
CREATE TABLE t3 (c1 INT AUTO_INCREMENT, c2 VECTOR(3), PRIMARY KEY(c1), VECTOR INDEX idx3(c2) WITH (distance=l2, type=hnsw_bq, lib=vsag));
|
||||
```
|
||||
|
||||
The `distance` parameter of HNSW_BQ supports only the l2 value.
|
||||
|
||||
##### IVF example
|
||||
|
||||
:::tip
|
||||
|
||||
When you create an IVF index, the index name must be less than 33 characters in length. Otherwise, an exception may occur because the auxiliary table name exceeds the <code>index_name</code> limit. In future versions, the index name can be longer.
|
||||
:::
|
||||
|
||||
```sql
|
||||
CREATE TABLE ivf_vecindex_suite_table_test (c1 INT, c2 VECTOR(3), PRIMARY KEY(c1), VECTOR INDEX idx2(c2) WITH (distance=l2, type=ivf_flat));
|
||||
```
|
||||
|
||||
### Create an index after table creation
|
||||
|
||||
:::tip
|
||||
|
||||
Currently, only dense vector indexes can be created after table creation.
|
||||
:::
|
||||
|
||||
#### Example of HNSW index
|
||||
|
||||
Create a test table.
|
||||
|
||||
```sql
|
||||
CREATE TABLE vec_table_hnsw (id INT, c2 VECTOR(10));
|
||||
```
|
||||
|
||||
Create an HNSW index.
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX vec_idx1 ON vec_table_hnsw(c2) WITH (distance=l2, type=hnsw);
|
||||
```
|
||||
|
||||
View the created table.
|
||||
|
||||
```sql
|
||||
SHOW CREATE TABLE vec_table_hnsw;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Table | Create Table |
|
||||
+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| vec_table_hnsw | CREATE TABLE `vec_table_hnsw` (
|
||||
`id` int(11) DEFAULT NULL,
|
||||
`c2` VECTOR(10) DEFAULT NULL,
|
||||
VECTOR KEY `vec_idx1` (`c2`) WITH (DISTANCE=L2, TYPE=HNSW, LIB=VSAG, M=16, EF_CONSTRUCTION=200, EF_SEARCH=64) BLOCK_SIZE 16384
|
||||
) DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 2 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 |
|
||||
+-----------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
```sql
|
||||
SHOW INDEX FROM vec_table_hnsw;
|
||||
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
|
||||
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible | Expression |
|
||||
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
|
||||
| vec_table | 1 | vec_idx1 | 1 | c2 | A | NULL | NULL | NULL | YES | VECTOR | available | | YES | NULL |
|
||||
+-----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+-----------+---------------+---------+------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
#### Example of HNSW_SQ index
|
||||
|
||||
Create a test table.
|
||||
|
||||
```sql
|
||||
CREATE TABLE vec_table_hnsw_sq (c1 INT AUTO_INCREMENT, c2 VECTOR(3), PRIMARY KEY(c1));
|
||||
```
|
||||
|
||||
Create an HNSW_SQ index.
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX vec_idx2 ON vec_table_hnsw_sq(c2) WITH (distance=l2, type=hnsw_sq, lib=vsag, m=16, ef_construction = 200);
|
||||
```
|
||||
|
||||
##### Example of HNSW_BQ index
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX vec_idx3 ON vec_table_hnsw_bq(c2) WITH (distance=l2, type=hnsw_bq, lib=vsag, m=16, ef_construction = 200);
|
||||
```
|
||||
|
||||
The `distance` parameter of the HNSW_BQ index can be used only with the L2 algorithm.
|
||||
|
||||
#### Example of IVF index
|
||||
|
||||
Create a test table.
|
||||
|
||||
```sql
|
||||
CREATE TABLE vec_table_ivf (c1 INT, c2 VECTOR(3), PRIMARY KEY(c1));
|
||||
```
|
||||
|
||||
Create an IVF index.
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX vec_idx3 ON vec_table_ivf(c2) WITH (distance=l2, type=ivf_flat);
|
||||
```
|
||||
|
||||
### Drop an index
|
||||
|
||||
```sql
|
||||
DROP INDEX vec_idx1 ON vec_table;
|
||||
```
|
||||
|
||||
View the dropped index.
|
||||
|
||||
```sql
|
||||
SHOW INDEX FROM vec_table;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
Empty set
|
||||
```
|
||||
|
||||
<!--## Monitoring
|
||||
|
||||
seekdb vector indexes provide monitoring capabilities:
|
||||
|
||||
* You can view the basic information and real-time status of HNSW/HNSW_SQ/HNSW_BQ indexes through the [GV$OB_HNSW_INDEX_INFO](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000004017373) view.
|
||||
* You can view the basic information and real-time status of IVF/IVF_SQ/IVF_PQ indexes through the [GV$OB_IVF_INDEX_INFO](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000004017374) view.-->
|
||||
|
||||
## Maintenance
|
||||
|
||||
When there is a large amount of incremental data, the query performance decreases. To reduce the amount of incremental data in the table, seekdb introduced the `DBMS_VECTOR` package for maintaining vector indexes.
|
||||
|
||||
### Incremental refresh
|
||||
|
||||
:::tip
|
||||
|
||||
IVF/IVF_SQ/IVF_PQ indexes do not support incremental refresh.
|
||||
:::
|
||||
|
||||
If a large amount of data is written after the index is created, we recommend that you perform an incremental refresh by using the `REFRESH_INDEX` procedure. For more information, see [REFRESH_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002753999).
|
||||
|
||||
The system checks for incremental data every 15 minutes. If more than 10,000 incremental data records are found, the system automatically performs an incremental refresh.
|
||||
|
||||
### Full refresh (rebuild)
|
||||
|
||||
#### Manual full table rebuild
|
||||
|
||||
If a large amount of data is updated or deleted after an index is created, it is recommended to use the `REBUILD_INDEX` procedure to perform a full refresh. For details and examples, see [REBUILD_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754000).
|
||||
|
||||
A full refresh is automatically checked every 24 hours. If the newly added data exceeds 20% of the original data, a full refresh will be triggered automatically. The full refresh runs asynchronously in the background: a new index is created first, and then the old index is replaced. During the rebuild process, the old index remains available, but the overall process is relatively slow.
|
||||
|
||||
We also provide the configuration item `vector_index_memory_saving_mode` to control the memory usage during index rebuild. Enabling this mode can reduce the memory consumption during vector index rebuild for partitioned tables. Typically, vector index rebuild requires memory equivalent to twice the index size. After enabling the memory-saving mode, the system will temporarily delete the memory index of a partition after building that partition to release memory, effectively reducing the total memory required for the rebuild operation. For syntax and examples, see [vector_index_memory_saving_mode](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002969408).
|
||||
|
||||
Notes:
|
||||
|
||||
* When executing offline DDL operations (such as `ALTER TABLE` to modify the table structure or primary key), the index table will be rebuilt. Since parallel degree cannot be specified for index rebuild, the system uses single-threaded execution by default. Therefore, when the data volume is large, the rebuild process will be slow, affecting the efficiency of the entire offline DDL operation.
|
||||
* When rebuilding an index, if you need to modify index parameters, you must specify both `type` and `distance` in the parameter list, and `type` and `distance` must match the original index type. For example, if the original index type is `hnsw` and the distance algorithm is `l2`, you must specify both `type=hnsw` and `distance=l2` during rebuild.
|
||||
* When rebuilding an index, the following are supported:
|
||||
* Modifying `m`, `ef_search`, and `ef_construction` values.
|
||||
* Online rebuild of the `ef_search` parameter.
|
||||
* Index type rebuild between `hnsw` - `hnsw_sq`.
|
||||
* Index type rebuild between `ivf_flat` - `ivf_flat`, `ivf_sq8` - `ivf_sq8`, `ivf_pq` - `ivf_pq`.
|
||||
* Setting parallel degree during rebuild. For examples, see [REBUILD_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754000).
|
||||
* When rebuilding an index, the following are not supported:
|
||||
* Modifying `type` and `distance` types.
|
||||
* Index rebuild between `hnsw` - `ivf`.
|
||||
* Index rebuild between `hnsw` - `hnsw_bq`.
|
||||
* Cross rebuild between `ivf_flat`, `ivf_pq`, and `ivf_sq8`.
|
||||
|
||||
#### Automatic partition rebuild (recommended)
|
||||
|
||||
:::tip
|
||||
<li>This feature is supported starting from V1.0.0. If your vector database is upgraded from an earlier version to V1.0.0, you need to manually rebuild all vector indexes for the entire table after the upgrade. Otherwise, automatic partition rebuild tasks may not be executed after the upgrade.</li><li>This feature only supports HNSW/HNSW_SQ/HNSW_BQ indexes.</li>
|
||||
:::
|
||||
|
||||
There are two scenarios that trigger automatic partition rebuild tasks in the current version:
|
||||
|
||||
* When executing vector index query statements.
|
||||
* Scheduled checks, with configurable execution cycle.
|
||||
|
||||
1. Configure execution cycle
|
||||
|
||||
In the `seekdb` database, configure the execution cycle through the configuration item `vector_index_optimize_duty_time`. Example:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET vector_index_optimize_duty_time='[23:00:00, 24:00:00]';
|
||||
```
|
||||
After the above configuration, partition rebuild tasks will only be executed between 23:00:00 and 24:00:00, and will not be initiated at other times. For detailed parameter descriptions, see the corresponding configuration item documentation.
|
||||
|
||||
2. View task progress/history
|
||||
|
||||
You can view task progress and history through the `CDB/DBA_OB_VECTOR_INDEX_TASKS` or `CDB/DBA_OB_VECTOR_INDEX_TASK_HISTORY` view.
|
||||
|
||||
Determine the current task status through the `status` field:
|
||||
|
||||
* 0 (PREPARE): The task is waiting to be executed.
|
||||
* 1 (RUNNING): The task is being executed.
|
||||
* 2 (PENDING): The task is paused.
|
||||
* 3 (FINISHED): The task has been completed.
|
||||
|
||||
Completed tasks, i.e., tasks with `status=FINISHED`, will be archived to the history table regardless of whether they succeeded. For detailed usage examples, see the corresponding view documentation.
|
||||
|
||||
3. Cancel task
|
||||
|
||||
To cancel a task, obtain the trace_id from the `DBA_OB_VECTOR_INDEX_TASKS` or `CDB_OB_VECTOR_INDEX_TASKS` view, then execute the following command:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM CANCEL TASK <trace_id>;
|
||||
```
|
||||
Example:
|
||||
```sql
|
||||
ALTER SYSTEM CANCEL TASK "Y61480BA2D976-00063084E80435E2-0-1";
|
||||
```
|
||||
|
||||
## Performance optimization
|
||||
|
||||
:::tip
|
||||
Only the IVF index is supported.
|
||||
:::
|
||||
|
||||
seekdb provides an automatic performance optimization mechanism for the IVF index to improve query performance through cache management and regular maintenance.
|
||||
|
||||
### Optimization mechanism
|
||||
|
||||
IVF index performance optimization includes two types of automated tasks:
|
||||
|
||||
1. Cache warming task: Periodically checks all IVF indexes. If it finds that the cache corresponding to an index does not exist, it automatically triggers cache warming and loads the index data into memory. Additionally, cache warming is automatically performed when an IVF index is created.
|
||||
2. Cache cleanup task: Periodically checks all IVF caches. If it finds that the cache corresponds to an index that has been deleted, it automatically cleans up the invalid cache and releases memory resources. Additionally, cache cleanup is automatically performed when an IVF index is deleted.
|
||||
|
||||
### Configure the optimization cycle
|
||||
|
||||
The system allows you to customize the execution time window for performance optimization tasks to avoid impacting performance during peak business hours.
|
||||
|
||||
In the `seekdb` database, you can set the execution cycle using the `vector_index_optimize_duty_time` parameter:
|
||||
|
||||
```sql
|
||||
ALTER SYSTEM SET vector_index_optimize_duty_time='[23:00:00, 24:00:00]';
|
||||
```
|
||||
|
||||
The configuration is described as follows:
|
||||
|
||||
* The time format is `[start time, end time]`.
|
||||
* The above configuration means that optimization tasks will only be executed between 23:00:00 and 24:00:00.
|
||||
* Optimization tasks will not be initiated at other times to avoid impacting normal business operations.
|
||||
|
||||
### Monitor optimization tasks
|
||||
|
||||
seekdb vector indexes provide monitoring capabilities for optimization tasks:
|
||||
|
||||
* You can view tasks that are being executed or waiting to be executed through the `DBA_OB_VECTOR_INDEX_TASKS` view.
|
||||
* You can view historical task records through the `DBA_OB_VECTOR_INDEX_TASK_HISTORY` view.
|
||||
|
||||
Usage examples:
|
||||
|
||||
1. View the current task status
|
||||
|
||||
View tasks that are being executed or waiting to be executed through the `DBA_OB_VECTOR_INDEX_TASKS` view:
|
||||
|
||||
```sql
|
||||
SELECT * FROM oceanbase.DBA_OB_VECTOR_INDEX_TASKS;
|
||||
```
|
||||
|
||||
Sample return result:
|
||||
|
||||
```shell
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| TABLE_ID | TABLET_ID | TASK_ID | START_TIME | MODIFY_TIME | TRIGGER_TYPE | STATUS | TASK_TYPE | TASK_SCN | RET_CODE | TRACE_ID |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| 500020 | 1152921504606846990 | 2002281 | 1970-08-23 17:10:23.174127 | 1970-08-23 17:10:23.174137 | USER | FINISHED | 2 | 1750671687770026 | 0 | YAFF00B9E4D97-00063839E6BD9BBC-0-1 |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
Description of the task status:
|
||||
|
||||
* `STATUS = 0`: PREPARE, the task is waiting to be executed.
|
||||
* `STATUS = 1`: RUNNING, the task is being executed.
|
||||
* `STATUS = 3`: FINISHED, the task has been completed.
|
||||
|
||||
Description of the task type:
|
||||
|
||||
* `TASK_TYPE = 2`: IVF cache warming task.
|
||||
* `TASK_TYPE = 3`: IVF invalid cache cleanup task.
|
||||
|
||||
2. View the history task records
|
||||
|
||||
Completed tasks (with `STATUS = 3`) are automatically archived to the history table every 10 seconds, regardless of whether they were successful. View the history through the `DBA_OB_VECTOR_INDEX_TASKS_HISTORY` view:
|
||||
|
||||
```sql
|
||||
-- Query the history of a specified task ID
|
||||
SELECT * FROM oceanbase.DBA_OB_VECTOR_INDEX_TASKS_HISTORY WHERE TASK_ID=2002281;
|
||||
```
|
||||
|
||||
Sample return result:
|
||||
|
||||
```shell
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| TABLE_ID | TABLET_ID | TASK_ID | START_TIME | MODIFY_TIME | TRIGGER_TYPE | STATUS | TASK_TYPE | TASK_SCN | RET_CODE | TRACE_ID |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| 500020 | 1152921504606846990 | 2002281 | 1970-08-23 17:10:23.174127 | 1970-08-23 17:10:23.174137 | AUTO | FINISHED | 2 | 1750671687770026 | 0 | YAFF00B9E4D97-00063839E6BD9BBC-0-1 |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Cancel an optimization task
|
||||
|
||||
You can cancel a specified task by using the following command:
|
||||
|
||||
```sql
|
||||
-- trace_id is obtained from the DBA_OB_VECTOR_INDEX_TASKS_HISTORY view
|
||||
ALTER SYSTEM CANCEL TASK <trace_id>;
|
||||
```
|
||||
|
||||
:::tip
|
||||
You can cancel a task only in the failed retry phase by executing the <code>ALTER SYSTEM CANCEL TASK</code> statement. If a background task is stuck in a specific execution phase, it cannot be canceled by using this statement.
|
||||
:::
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
-- Log in to the system and obtain the trace_id of the specified task
|
||||
SELECT * FROM oceanbase.DBA_OB_VECTOR_INDEX_TASK_HISTORY WHERE TASK_ID=2037736;
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| TABLE_ID | TABLET_ID | TASK_ID | START_TIME | MODIFY_TIME | TRIGGER_TYPE | STATUS | TASK_TYPE | TASK_SCN | RET_CODE | TRACE_ID |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| 500041 | 1152921504606847008 | 2037736 | 1970-08-23 17:10:23.203821 | 1970-08-23 17:10:23.203821 | USER | PREPARED | 2 | 1750682301145225 | -1 | YAFF00B9E4D97-00063839E6BDDEE0-0-1 |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
```sql
|
||||
-- Cancel the task
|
||||
ALTER SYSTEM CANCEL TASK "YAFF00B9E4D97-00063839E6BDDEE0-0-1";
|
||||
```
|
||||
|
||||
After the task is canceled, the task status changes to `CANCELLED`.
|
||||
|
||||
```sql
|
||||
-- Log in to the user database and query the task status
|
||||
SELECT * FROM oceanbase.DBA_OB_VECTOR_INDEX_TASK_HISTORY;
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| TABLE_ID | TABLET_ID | TASK_ID | START_TIME | MODIFY_TIME | TRIGGER_TYPE | STATUS | TASK_TYPE | TASK_SCN | RET_CODE | TRACE_ID |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
| 500041 | 1152921504606847008 | 2037736 | 1970-08-23 17:10:23.203821 | 1970-08-23 17:10:23.203821 | USER | FINISHED | 2 | 1750682301145225 | -4072 | YAFF00B9E4D97-00063839E6BDDEE0-0-1 |
|
||||
+----------+---------------------+---------+----------------------------+----------------------------+--------------+----------+-----------+------------------+----------+------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Use SQL functions](../250.vector-function.md)
|
||||
@@ -0,0 +1,374 @@
|
||||
---
|
||||
|
||||
slug: /hybrid-vector-index
|
||||
---
|
||||
|
||||
# Create a hybrid vector index
|
||||
|
||||
This topic describes how to create a hybrid vector index in seekdb.
|
||||
|
||||
## Overview
|
||||
|
||||
Hybrid vector indexes leverage seekdb's built-in embedding capabilities to greatly simplify the vector index usage process. They make the vector concept transparent to users: you can directly write raw data (such as text) that needs to be stored, and seekdb will automatically convert it to vectors and build indexes internally. During retrieval, you only need to provide the raw query content, and seekdb will also automatically perform embedding and retrieve the vector index, significantly improving ease of use.
|
||||
|
||||
Considering the performance overhead of embedding models, hybrid vector indexes provide two embedding modes for users to choose from:
|
||||
* Synchronous mode: Embedding and indexing are performed immediately after data is written, ensuring real-time data visibility.
|
||||
* Asynchronous mode: Background tasks perform data embedding and indexing in batches, which can significantly improve write performance. You can flexibly set the trigger cycle of background tasks based on your requirements for real-time data visibility.
|
||||
|
||||
In addition, this feature also provides the capability to perform brute-force search on hybrid vector indexes to help verify the correctness of search results. Brute-force search refers to performing a search using a full table scan to obtain the exact results of the n nearest rows.
|
||||
|
||||
## Feature support
|
||||
|
||||
:::tip
|
||||
This feature currently supports only HNSW/HNSW_BQ indexes.
|
||||
:::
|
||||
|
||||
This feature supports the full lifecycle of hybrid vector indexes, including creation, update, deletion, and retrieval, and is compatible with `REFRESH_INDEX` and `REBUILD_INDEX` in the `DBMS_VECTOR` system package. The syntax for update, deletion, and retrieval is exactly the same as that for regular vector indexes. In asynchronous mode, `REFRESH_INDEX` will additionally trigger data embedding. For details about creation and retrieval, see the sections below.
|
||||
|
||||
The supported features are as follows:
|
||||
|
||||
| Module | Feature | Description |
|
||||
|------|--------|------|
|
||||
| DDL | Create a hybrid vector index during table creation | You can create a hybrid vector index on a `VARCHAR` column when creating a table |
|
||||
| DDL | Create a hybrid vector index after table creation | Supports creating a hybrid vector index on a `VARCHAR` column of an existing table |
|
||||
| Retrieval | `semantic_distance` function | Pass raw data through this function for vector retrieval |
|
||||
| Retrieval | `semantic_vector_distance` function | Pass vectors through this function for retrieval. There are two usage modes: <ul><li>When the SQL statement includes the `APPROXIMATE`/`APPROX` clause, vector index retrieval is used.</li><li>When the `APPROXIMATE`/`APPROX` clause is not included, brute-force search using a full table scan is performed.</li></ul> |
|
||||
| DBMS_VECTOR | `REFRESH_INDEX` | The usage is the same as that for regular vector indexes. Performs incremental index refresh and embedding in asynchronous mode |
|
||||
| DBMS_VECTOR | `REBUILD_INDEX` | The usage is the same as that for regular vector indexes. Performs full index rebuild |
|
||||
|
||||
Some usage notes are as follows:
|
||||
|
||||
* In synchronous mode, write performance may be affected by embedding performance. In asynchronous mode, data visibility will be delayed.
|
||||
* For repeated retrieval scenarios, it is recommended to use AI Function Service to pre-obtain query vectors to avoid embedding for each retrieval.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using hybrid vector indexes, you must register an embedding model and endpoint. The following is a registration example:
|
||||
|
||||
```sql
|
||||
CALL DBMS_AI_SERVICE.DROP_AI_MODEL ('ob_embed');
|
||||
CALL DBMS_AI_SERVICE.DROP_AI_MODEL_ENDPOINT ('ob_embed_endpoint');
|
||||
|
||||
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL(
|
||||
'ob_embed', '{
|
||||
"type": "dense_embedding",
|
||||
"model_name": "BAAI/bge-m3"
|
||||
}');
|
||||
|
||||
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
|
||||
'ob_embed_endpoint', '{
|
||||
"ai_model_name": "ob_embed",
|
||||
"url": "https://api.siliconflow.cn/v1/embeddings",
|
||||
"access_key": "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxx",
|
||||
"provider": "siliconflow"
|
||||
}');
|
||||
```
|
||||
|
||||
:::info
|
||||
Replace <code>access_key</code> with your actual API Key. The BAAI/bge-m3 model has a vector dimension of 1024, so you need to use <code>dim=1024</code> when creating a hybrid vector index.
|
||||
:::
|
||||
|
||||
## Creation syntax and description
|
||||
|
||||
Hybrid vector indexes support two creation methods: **creation during table creation** and **creation after table creation**. When creating an index, note the following:
|
||||
|
||||
* The index must be created on a column of the `VARCHAR` type.
|
||||
* The `model` and `sync_mode` parameters are not supported for regular vector indexes.
|
||||
* The parameters and descriptions for an index created after table creation are the same as those for an index created during table creation.
|
||||
|
||||
### Create during table creation
|
||||
|
||||
You can use the `CREATE TABLE` statement to create a hybrid vector index. Through index parameters, background tasks can be initiated synchronously or asynchronously. In synchronous mode, `VARCHAR` data is automatically converted to vector data when data is inserted. In asynchronous mode, data conversion is performed periodically or manually.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 data_type1,
|
||||
column_name2 VARCHAR, -- Text column
|
||||
...,
|
||||
VECTOR INDEX index_name (column_name2) WITH (param1=value1, param2=value2, ...)
|
||||
);
|
||||
```
|
||||
|
||||
#### Parameter description
|
||||
|
||||
| Parameter | Default value | Value range | Required | Description | Remarks |
|
||||
|------|--------|----------|----------|------|------|
|
||||
| `distance` | | `l2`/`inner_product`/`cosine` | Yes | Specifies the vector distance algorithm type. | `l2` indicates Euclidean distance, `inner_product` indicates inner product distance, and `cosine` indicates cosine distance. |
|
||||
| `type` | | Currently supports `hnsw` / `hnsw_bq` | Yes | Specifies the index algorithm type. | |
|
||||
| `lib` | `vsag` | `vsag` | No | Specifies the vector index library type. | Currently, only the VSAG vector library is supported. |
|
||||
| `model` | | Registered model name | Yes | Specifies the large language model name used for embedding. | The model must be registered using AI Function Service before creating the index.<main id="notice" type='notice'><h4>Note</h4><p>Regular vector indexes do not support setting this parameter.</p></main> |
|
||||
| `dim` | | Positive integer, maximum 4096 | Yes | Specifies the vector dimension after embedding. | Must match the dimension provided by the model. |
|
||||
| `sync_mode` | `async` | `immediate`/`manual`/`async` | No | Specifies the data and index synchronization mode. | `immediate` indicates synchronous mode, `manual` indicates manual mode, and `async` indicates asynchronous mode.<main id="notice" type='notice'><h4>Note</h4><p>Regular vector indexes do not support setting this parameter.</p></main> |
|
||||
| `sync_interval` | `10s` | Time interval, such as `10s`, `1h`, `1d`, etc. | No | Sets the trigger cycle of background tasks in asynchronous mode. | The numeric part must be positive. Units supported include seconds (s), hours (h), days (d), etc. |
|
||||
|
||||
The usage of other vector index parameters (such as `m`, `ef_construction`, `ef_search`, etc.) is the same as that for regular vector indexes. For details, see the related documentation.
|
||||
|
||||
### Create after table creation
|
||||
|
||||
Supports creating a hybrid vector index on a `VARCHAR` column of an existing table. When creating an index after table creation, synchronous or asynchronous background tasks are initiated through the provided index parameters. In synchronous mode, all existing `VARCHAR` data is converted to vector data. In asynchronous mode, data conversion is performed periodically or manually.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX index_name
|
||||
ON table_name(varchar_column_name)
|
||||
WITH (param1=value1, param2=value2, ...);
|
||||
```
|
||||
|
||||
#### Parameter description
|
||||
|
||||
The parameter description is the same as that for creating an index during table creation. For details, see the section above.
|
||||
|
||||
## Create, update, and delete examples
|
||||
|
||||
DML operations (`INSERT`, `UPDATE`, `DELETE`) for hybrid vector indexes are exactly the same as those for regular vector indexes. When inserting or updating data of the `VARCHAR` type, the system automatically or asynchronously performs embedding based on the `sync_mode` parameter setting.
|
||||
|
||||
### Create during table creation
|
||||
|
||||
Create the `vector_idx` index when creating the test table `items`:
|
||||
|
||||
```sql
|
||||
-- Assume that the ob_embed model has been created previously (please refer to the "Prerequisites" section to register the model)
|
||||
CREATE TABLE items (
|
||||
id BIGINT PRIMARY KEY,
|
||||
doc VARCHAR(100),
|
||||
VECTOR INDEX vector_idx(doc)
|
||||
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=async, sync_interval=10s)
|
||||
);
|
||||
```
|
||||
|
||||
Insert a row of data into the test table `items`. The system will automatically perform embedding:
|
||||
|
||||
```sql
|
||||
INSERT INTO items(id, doc) VALUES(1, 'Rose');
|
||||
```
|
||||
|
||||
### Create after table creation
|
||||
|
||||
After creating the test table `items`, use the `CREATE VECTOR INDEX` statement to create the `vector_idx` index:
|
||||
|
||||
```sql
|
||||
CREATE TABLE items (
|
||||
id BIGINT PRIMARY KEY,
|
||||
doc VARCHAR(100)
|
||||
);
|
||||
|
||||
-- Assume that the ob_embed model has been created previously (please refer to the "Prerequisites" section to register the model)
|
||||
CREATE VECTOR INDEX vector_idx
|
||||
ON items (doc)
|
||||
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=async, sync_interval=10s);
|
||||
```
|
||||
|
||||
Insert a row of data into the test table `items`. The system will automatically perform embedding:
|
||||
|
||||
```sql
|
||||
INSERT INTO items(id, doc) VALUES(1, 'Rose');
|
||||
```
|
||||
|
||||
### Update
|
||||
|
||||
When updating data of the `VARCHAR` type, the system will re-perform embedding:
|
||||
|
||||
* Synchronous mode: Re-embedding is performed immediately after update.
|
||||
* Asynchronous mode: Re-embedding is performed by background tasks at the next trigger cycle after update.
|
||||
|
||||
Usage example:
|
||||
|
||||
```sql
|
||||
UPDATE items SET doc = 'Lily' WHERE id = 1;
|
||||
```
|
||||
|
||||
### Delete
|
||||
|
||||
The delete operation is the same as that for regular vector indexes. You can directly delete the data.
|
||||
|
||||
Usage example:
|
||||
|
||||
```sql
|
||||
DELETE FROM items WHERE id = 1;
|
||||
```
|
||||
|
||||
## Retrieval
|
||||
|
||||
Hybrid vector indexes support two retrieval methods:
|
||||
|
||||
* Retrieve using raw text
|
||||
* Retrieve using vectors
|
||||
|
||||
For detailed usage of the `APPROXIMATE`/`APPROX` clause, see the related documentation on creating vector indexes at the end of this topic.
|
||||
|
||||
### Retrieve using raw text
|
||||
|
||||
Use the `semantic_distance` expression to pass raw text for vector retrieval.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
SELECT ... FROM table_name
|
||||
ORDER BY semantic_distance(column_name, 'query_text') [APPROXIMATE|APPROX]
|
||||
LIMIT n;
|
||||
```
|
||||
|
||||
Where:
|
||||
* `column_name`: The text column specified when creating the hybrid vector index.
|
||||
* `query_text`: The raw text for retrieval.
|
||||
* `n`: The number of result rows to return.
|
||||
|
||||
#### Usage example
|
||||
|
||||
```sql
|
||||
-- Assume that the ob_embed model has been created previously
|
||||
CREATE TABLE items (
|
||||
id INT PRIMARY KEY,
|
||||
doc varchar(100),
|
||||
VECTOR INDEX vector_idx(doc)
|
||||
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=immediate)
|
||||
);
|
||||
|
||||
INSERT INTO items(id, doc) VALUES(1, 'Rose');
|
||||
INSERT INTO items(id, doc) VALUES(2, 'Sunflower');
|
||||
INSERT INTO items(id, doc) VALUES(3, 'Rose');
|
||||
INSERT INTO items(id, doc) VALUES(4, 'Sunflower');
|
||||
INSERT INTO items(id, doc) VALUES(5, 'Rose');
|
||||
|
||||
-- Retrieve using raw text
|
||||
SELECT id, doc FROM items
|
||||
ORDER BY semantic_distance(doc, 'Sunflower')
|
||||
APPROXIMATE LIMIT 3;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```sql
|
||||
+----+-----------+
|
||||
| id | doc |
|
||||
+----+-----------+
|
||||
| 2 | Sunflower |
|
||||
| 4 | Sunflower |
|
||||
| 5 | Rose |
|
||||
+----+-----------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
### Retrieve using vectors (with APPROXIMATE clause)
|
||||
|
||||
Use the `semantic_vector_distance` expression to pass vectors for retrieval. When the retrieval statement includes the `APPROXIMATE`/`APPROX` clause, vector index retrieval is used.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
SELECT ... FROM table_name
|
||||
ORDER BY semantic_vector_distance(column_name, 'query_vector') [APPROXIMATE|APPROX]
|
||||
LIMIT n;
|
||||
```
|
||||
|
||||
Where:
|
||||
* `column_name`: The text column specified when creating the hybrid vector index.
|
||||
* `query_vector`: The query vector.
|
||||
* `n`: The number of result rows to return.
|
||||
|
||||
#### Usage example
|
||||
|
||||
```sql
|
||||
-- Assume that the ob_embed model has been created previously (please refer to the "Prerequisites" section to register the model)
|
||||
CREATE TABLE items (
|
||||
id INT PRIMARY KEY,
|
||||
doc varchar(100),
|
||||
VECTOR INDEX vector_idx(doc)
|
||||
WITH (distance=l2, lib=vsag, type=hnsw, model=ob_embed, dim=1024, sync_mode=immediate)
|
||||
);
|
||||
|
||||
INSERT INTO items(id, doc) VALUES(1, 'Rose');
|
||||
INSERT INTO items(id, doc) VALUES(2, 'Lily');
|
||||
INSERT INTO items(id, doc) VALUES(3, 'Sunflower');
|
||||
INSERT INTO items(id, doc) VALUES(4, 'Rose');
|
||||
|
||||
-- First, obtain the query vector
|
||||
SET @query_vector = AI_EMBED('ob_embed', 'Sunflower');
|
||||
|
||||
-- Retrieve using vectors with index
|
||||
SELECT id, doc FROM items
|
||||
ORDER BY semantic_vector_distance(doc, @query_vector)
|
||||
APPROXIMATE LIMIT 3;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+-----------+
|
||||
| id | doc |
|
||||
+----+-----------+
|
||||
| 3 | Sunflower |
|
||||
| 1 | Rose |
|
||||
| 4 | Rose |
|
||||
+----+-----------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
### Retrieve using vectors (without APPROXIMATE clause)
|
||||
|
||||
Use the `semantic_vector_distance` expression to pass vectors for retrieval. When the `APPROXIMATE`/`APPROX` clause is not included, brute-force search using a full table scan is performed to obtain the exact results of the n nearest rows. During retrieval execution, the `distance` type is obtained from the table schema, and then a full table scan is performed. Vector distance is calculated for each row to ensure accurate results.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
SELECT ... FROM table_name
|
||||
ORDER BY semantic_vector_distance(column_name, 'query_vector')
|
||||
LIMIT n;
|
||||
```
|
||||
|
||||
Where:
|
||||
* `column_name`: The text column specified when creating the hybrid vector index.
|
||||
* `query_vector`: The query vector.
|
||||
* `n`: The number of result rows to return.
|
||||
|
||||
#### Usage example
|
||||
|
||||
```sql
|
||||
-- Retrieve using vectors with brute-force search (exact results)
|
||||
SELECT id, doc FROM items
|
||||
ORDER BY semantic_vector_distance(doc, @query_vector)
|
||||
LIMIT 3;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+-----------+
|
||||
| id | doc |
|
||||
+----+-----------+
|
||||
| 3 | Sunflower |
|
||||
| 4 | Rose |
|
||||
| 1 | Rose |
|
||||
+----+-----------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
## Index maintenance
|
||||
|
||||
Hybrid vector indexes support using the `DBMS_VECTOR` system package for index maintenance, including incremental refresh and full rebuild.
|
||||
|
||||
### Incremental refresh
|
||||
|
||||
If a large amount of data is written after the index is created, it is recommended to use the `REFRESH_INDEX` procedure for incremental refresh. For descriptions and examples, see the related documentation.
|
||||
|
||||
Special notes for hybrid vector indexes:
|
||||
* The usage is the same as that for regular vector indexes. For details, see the related documentation.
|
||||
* In asynchronous mode, `REFRESH_INDEX` will additionally trigger data embedding to ensure that incremental data is correctly converted to vectors and added to the index.
|
||||
|
||||
### Full refresh (rebuild)
|
||||
|
||||
If a large amount of data is updated or deleted after the index is created, it is recommended to use the `REBUILD_INDEX` procedure for full refresh. For descriptions and examples, see the related documentation.
|
||||
|
||||
Special notes for hybrid vector indexes:
|
||||
* The usage is the same as that for regular vector indexes. For details, see the related documentation.
|
||||
* The task merges incremental data and snapshots.
|
||||
|
||||
## Related documentation
|
||||
|
||||
* [AI Function Service](../../300.ai-function/200.ai-function.md)
|
||||
* [Create a vector index](200.dense-vector-index.md)
|
||||
* [REFRESH_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002753999)
|
||||
* [REBUILD_INDEX](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002754000)
|
||||
@@ -0,0 +1,279 @@
|
||||
---
|
||||
|
||||
slug: /in-memory-sparse-vector-index
|
||||
---
|
||||
|
||||
# In-memory sparse vector index
|
||||
|
||||
This topic describes how to create, query, and use in-memory sparse vector indexes in seekdb.
|
||||
|
||||
## Overview
|
||||
|
||||
In-memory sparse vector indexes are an efficient index type provided by seekdb for sparse vector data (vectors where most elements are zero). In-memory sparse vector indexes must be fully loaded into memory and support DML and real-time queries.
|
||||
|
||||
To improve the query performance of sparse vectors, seekdb integrates the sparse vector index (SINDI) from the VSAG algorithm library. This index performs better than disk-based sparse vector indexes and is suitable for use when memory resources are sufficient.
|
||||
|
||||
## Feature support
|
||||
|
||||
In-memory sparse vector indexes support the following features:
|
||||
|
||||
| Module | Feature | Description |
|
||||
|------|--------|------|
|
||||
| DDL | Create a sparse vector index during table creation | You can create a sparse vector index on a `SPARSEVECTOR` column when creating a table. The maximum supported dimension is 500,000. |
|
||||
| DDL | Create a sparse vector index after table creation | Supports creating a sparse vector index on a `SPARSEVECTOR` column of an existing table. The maximum supported dimension is 500,000. |
|
||||
| DML | Insert, update, delete | The syntax for DML operations is exactly the same as that for regular vector indexes. |
|
||||
| Retrieval | Vector retrieval | Supports retrieval using SQL functions. |
|
||||
| Retrieval | Query parameters | Supports setting query-level parameters through the `parameters` clause during retrieval. |
|
||||
| DBMS_VECTOR | `REFRESH_INDEX` | Performs incremental index refresh. |
|
||||
| DBMS_VECTOR | `REBUILD_INDEX` | Performs full index rebuild. |
|
||||
|
||||
## Index memory estimation and actual usage query
|
||||
|
||||
Supports index memory estimation through the `DBMS_VECTOR` system package. The usage is the same as that for dense indexes. Here, only the special requirements for sparse vector indexes are described:
|
||||
|
||||
* The `IDX_TYPE` parameter must be set to `SINDI`, case-insensitive.
|
||||
|
||||
## Creation syntax and description
|
||||
|
||||
In-memory sparse vector indexes support two creation methods: **creation during table creation** and **creation after table creation**. When creating an index, note the following:
|
||||
|
||||
* The maximum supported dimension for columns on which sparse vector indexes are created is 500,000.
|
||||
* Sparse vector indexes must be created on columns of the `SPARSEVECTOR` type.
|
||||
* The `VECTOR` keyword is required when creating an index.
|
||||
* The index type must be set to `sindi`, which indicates creating an in-memory sparse vector index.
|
||||
* Only the `inner_product` (inner product) distance algorithm is supported.
|
||||
* The parameters and descriptions for an index created after table creation are the same as those for an index created during table creation.
|
||||
|
||||
### Create during table creation
|
||||
|
||||
Supports using the `CREATE TABLE` statement to create a sparse vector index.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
CREATE TABLE table_name (
|
||||
column_name1 data_type1,
|
||||
column_name2 SPARSEVECTOR,
|
||||
...,
|
||||
VECTOR INDEX index_name (column_name2) WITH (param1=value1, param2=value2, ...)
|
||||
);
|
||||
```
|
||||
|
||||
#### Parameter description
|
||||
|
||||
| Parameter | Default value | Value range | Required | Description | Remarks |
|
||||
|------|--------|----------|----------|------|------|
|
||||
| `distance` | | `inner_product` | Yes | Specifies the vector distance algorithm type. | Sparse vector indexes support only inner product (`inner_product`) as the distance algorithm. |
|
||||
| `type` | | `sindi` | Yes | Specifies the index algorithm type. | Indicates creating an in-memory sparse vector index. |
|
||||
| `lib` | `vsag` | `vsag` | No | Specifies the vector index library type. | Currently, only the VSAG vector library is supported. |
|
||||
| `prune` | `false` | `true`/`false` | No | Whether to perform pruning on vectors. | When `prune` is `true`, you need to set the `refine` and `drop_ratio_build` parameters. When `prune` is `false`, full-precision retrieval can be provided. If `refine` is set to `true` or `drop_ratio_build` is not `0`, an error will be returned. |
|
||||
| `refine` | `false` | `true`/`false` | No | Whether reranking is needed. | When set to `true`, the original sparse vectors are retrieved for the search results to perform high-precision distance calculation and reranking, which means an additional copy of the original vector data needs to be stored. Can be set only when `prune=true`. |
|
||||
| `drop_ratio_build` | `0` | `[0, 0.9]` | No | The pruning ratio for sparse vector data. | When a new sparse vector is inserted, the `query_length * drop_ratio_build` smallest values are pruned based on value size. If `refine` is `true`, the original vector data is preserved. Otherwise, only the pruned data is retained. Can be set only when `prune=true`. |
|
||||
| `drop_ratio_search` | `0` | `[0, 0.9]` | No | The pruning ratio for sparse vector values during retrieval. | The larger the value, the more pruning is performed, the lower the accuracy, and the higher the performance. Can also be set through the `parameters` clause during retrieval, and query parameters have higher priority. |
|
||||
| `refine_k` | `4.0` | `[1.0, 1000.0]` | No | Indicates the proportion of results participating in reranking. | Retrieves `limit_k * refine_k` results and obtains the original vectors for reranking. Meaningful only when `refine=true`. Can also be set through the `parameters` clause during retrieval, and query parameters have higher priority. |
|
||||
|
||||
### Create after table creation
|
||||
|
||||
Supports creating a sparse vector index on a `SPARSEVECTOR` column of an existing table.
|
||||
|
||||
#### Syntax
|
||||
|
||||
```sql
|
||||
CREATE VECTOR INDEX index_name ON table_name(column_name) WITH (param1=value1, param2=value2, ...);
|
||||
```
|
||||
|
||||
#### Parameter description
|
||||
|
||||
The parameter description is the same as that for creating an index during table creation. For details, see the section above.
|
||||
|
||||
## Create, update, and delete examples
|
||||
|
||||
### Create during table creation
|
||||
|
||||
Create the test table `sparse_t1` and create a sparse vector index:
|
||||
|
||||
```sql
|
||||
CREATE TABLE sparse_t1 (
|
||||
c1 INT PRIMARY KEY,
|
||||
c2 SPARSEVECTOR,
|
||||
VECTOR INDEX sparse_idx1(c2)
|
||||
WITH (lib=vsag, type=sindi, distance=inner_product)
|
||||
);
|
||||
```
|
||||
|
||||
Insert sparse vector data into the test table:
|
||||
|
||||
```sql
|
||||
INSERT INTO sparse_t1 VALUES(1, '{1:0.1, 2:0.2, 3:0.3}');
|
||||
INSERT INTO sparse_t1 VALUES(2, '{3:0.3, 2:0.2, 4:0.4}');
|
||||
INSERT INTO sparse_t1 VALUES(3, '{3:0.3, 4:0.4, 5:0.5}');
|
||||
```
|
||||
|
||||
Query the test table:
|
||||
|
||||
```sql
|
||||
SELECT * FROM sparse_t1;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```
|
||||
+----+---------------------+
|
||||
| c1 | c2 |
|
||||
+----+---------------------+
|
||||
| 1 | {1:0.1,2:0.2,3:0.3} |
|
||||
| 2 | {2:0.2,3:0.3,4:0.4} |
|
||||
| 3 | {3:0.3,4:0.4,5:0.5} |
|
||||
+----+---------------------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
### Create after table creation
|
||||
|
||||
Create a sparse vector index after creating the test table:
|
||||
|
||||
```sql
|
||||
CREATE TABLE sparse_t2 (
|
||||
c1 INT PRIMARY KEY,
|
||||
c2 SPARSEVECTOR
|
||||
);
|
||||
|
||||
CREATE VECTOR INDEX sparse_idx2 ON sparse_t2(c2)
|
||||
WITH (lib=vsag, type=sindi, distance=inner_product,
|
||||
prune=true, refine=true, drop_ratio_build=0.1,
|
||||
drop_ratio_search=0.5, refine_k=2.0);
|
||||
```
|
||||
|
||||
Insert sparse vector data into the test table:
|
||||
|
||||
```sql
|
||||
INSERT INTO sparse_t2 VALUES(1, '{1:0.1, 2:0.2, 3:0.3}');
|
||||
```
|
||||
|
||||
Query the test table:
|
||||
|
||||
```sql
|
||||
SELECT * FROM sparse_t2;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+---------------------+
|
||||
| c1 | c2 |
|
||||
+----+---------------------+
|
||||
| 1 | {1:0.1,2:0.2,3:0.3} |
|
||||
+----+---------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Update
|
||||
|
||||
When updating sparse vector data, the index is automatically maintained:
|
||||
|
||||
```sql
|
||||
UPDATE sparse_t1 SET c2 = '{1:0.1}' WHERE c1 = 1;
|
||||
```
|
||||
|
||||
### Delete
|
||||
|
||||
The delete operation is the same as that for regular vector indexes. You can directly delete the data:
|
||||
|
||||
```sql
|
||||
DELETE FROM sparse_t1 WHERE c1 = 1;
|
||||
```
|
||||
|
||||
## Retrieval
|
||||
|
||||
The retrieval syntax for sparse vector indexes is similar to that for dense vector indexes, using the `APPROXIMATE`/`APPROX` keyword for approximate nearest neighbor retrieval.
|
||||
|
||||
### Syntax
|
||||
|
||||
```sql
|
||||
SELECT ... FROM table_name
|
||||
ORDER BY inner_product(column_name, query_vector) [APPROXIMATE|APPROX]
|
||||
LIMIT n [PARAMETERS(param1=value1, param2=value2)];
|
||||
```
|
||||
|
||||
Where:
|
||||
* `column_name`: The `SPARSEVECTOR` column specified when creating the sparse vector index.
|
||||
* `query_vector`: The query vector, which can be a string in sparse vector format, such as `'{1:2.4, 3:1.5}'`.
|
||||
* `n`: The number of result rows to return.
|
||||
* `PARAMETERS`: Optional query-level parameters for setting `drop_ratio_search` and `refine_k`.
|
||||
|
||||
### Retrieval usage notes
|
||||
|
||||
For detailed requirements, see [Dense vector index](../200.dense-vector-index.md). Here, only the special requirements for sparse vector indexes are described:
|
||||
|
||||
* Query parameter priority: Query-level parameters set by `PARAMETERS` > Query parameters set when building the index > Default values.
|
||||
* `drop_ratio_search`: Value range `[0, 0.9]`, default value `0`. The pruning ratio for sparse vector values during retrieval. The larger the value, the more pruning is performed, the lower the accuracy, and the higher the performance. Prunes the `query_length * drop_ratio_search` smallest values based on value size. Since pruning all values is meaningless, at least one value is always retained.
|
||||
* `refine_k`: Value range `[1.0, 1000.0]`, default value `4.0`. Indicates the proportion of results participating in reranking. Queries `limit_k * refine_k` results and obtains the original vectors for reranking. Effective only when `refine=true`.
|
||||
|
||||
### Usage examples
|
||||
|
||||
#### Regular query
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1 (
|
||||
c1 INT PRIMARY KEY,
|
||||
c2 SPARSEVECTOR,
|
||||
VECTOR INDEX idx1(c2)
|
||||
WITH (lib=vsag, type=sindi, distance=inner_product)
|
||||
);
|
||||
|
||||
INSERT INTO t1 VALUES(1, '{1:0.1, 2:0.2, 3:0.3}');
|
||||
INSERT INTO t1 VALUES(2, '{3:0.3, 2:0.2, 4:0.4}');
|
||||
INSERT INTO t1 VALUES(3, '{3:0.3, 4:0.4, 5:0.5}');
|
||||
INSERT INTO t1 VALUES(4, '{5:0.5, 4:0.4, 6:0.6}');
|
||||
INSERT INTO t1 VALUES(5, '{5:0.5, 6:0.6, 7:0.7}');
|
||||
|
||||
SELECT * FROM t1
|
||||
ORDER BY negative_inner_product(c2, '{3:0.3, 4:0.4}')
|
||||
APPROXIMATE LIMIT 4;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+---------------------+
|
||||
| c1 | c2 |
|
||||
+----+---------------------+
|
||||
| 2 | {2:0.2,3:0.3,4:0.4} |
|
||||
| 3 | {3:0.3,4:0.4,5:0.5} |
|
||||
| 4 | {4:0.4,5:0.5,6:0.6} |
|
||||
| 1 | {1:0.1,2:0.2,3:0.3} |
|
||||
+----+---------------------+
|
||||
```
|
||||
|
||||
#### Use query parameters
|
||||
|
||||
```sql
|
||||
SELECT *, negative_inner_product(c2, '{3:0.3, 4:0.4}')
|
||||
AS score FROM t1
|
||||
ORDER BY score APPROXIMATE LIMIT 4
|
||||
PARAMETERS(drop_ratio_search=0.5);
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----+---------------------+---------------------+
|
||||
| c1 | c2 | score |
|
||||
+----+---------------------+---------------------+
|
||||
| 4 | {4:0.4,5:0.5,6:0.6} | -0.1600000113248825 |
|
||||
| 3 | {3:0.3,4:0.4,5:0.5} | -0.2500000149011612 |
|
||||
| 2 | {2:0.2,3:0.3,4:0.4} | -0.2500000149011612 |
|
||||
+----+---------------------+---------------------+
|
||||
3 rows in set
|
||||
```
|
||||
|
||||
## Index monitoring and maintenance
|
||||
|
||||
In-memory sparse vector indexes provide monitoring views and support using the `DBMS_VECTOR` system package for index maintenance, including incremental refresh and full rebuild. The usage is the same as that for dense indexes.
|
||||
|
||||
## Related documentation
|
||||
|
||||
* For detailed information about sparse vector data types, see [Vector data type](../../700.vector-search-reference/100.vector-data-type.md).
|
||||
* For detailed information about vector distance functions, see [Vector functions](../../250.vector-function.md).
|
||||
* For monitoring and maintenance of dense vector indexes, see [Vector index monitoring/maintenance](../200.dense-vector-index.md).
|
||||
* For index memory estimation and actual usage query of vector indexes, see [Index memory estimation and actual usage query](../200.dense-vector-index.md).
|
||||
@@ -0,0 +1,611 @@
|
||||
---
|
||||
|
||||
slug: /vector-function
|
||||
---
|
||||
|
||||
# Use SQL functions
|
||||
|
||||
This topic describes the vector functions supported by seekdb and the considerations for using them.
|
||||
|
||||
## Considerations
|
||||
|
||||
* Vectors with different dimensions are not allowed to perform the following operations. An error `different vector dimensions %d and %d` is returned.
|
||||
|
||||
* When the result exceeds the floating-point number range, an error `value out of range: overflow / underflow` is returned.
|
||||
|
||||
* Dense vector indexes support L2, inner product, and cosine distance as index distance algorithms. Memory-based sparse vector indexes support inner product as the distance algorithm. For details, see [Create vector indexes](200.vector-index/200.dense-vector-index.md).
|
||||
|
||||
* Vector index search supports calling the `L2_distance`, `Cosine_distance`, and `Inner_product` distance functions in this document.
|
||||
|
||||
## Distance functions
|
||||
|
||||
Distance functions are used to calculate the distance between two vectors. The calculation method varies depending on the distance algorithm used.
|
||||
|
||||
### L2_distance
|
||||
|
||||
Euclidean distance reflects the distance between the coordinates of the compared vectors -- essentially the straight-line distance between two vectors. It is calculated by applying the Pythagorean theorem to vector coordinates:
|
||||
|
||||
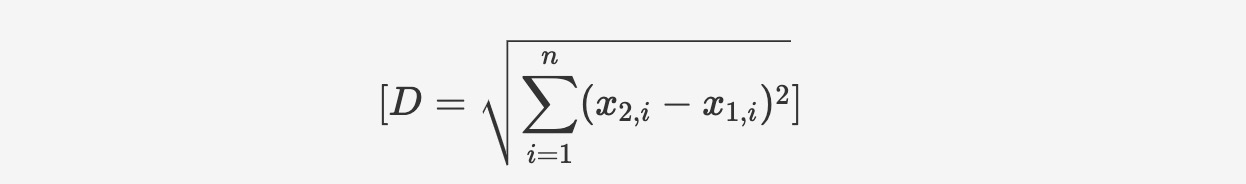
|
||||
|
||||
The function syntax is as follows:
|
||||
|
||||
```sql
|
||||
l2_distance(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1(c1 vector(3));
|
||||
INSERT INTO t1 VALUES('[1,2,3]');
|
||||
SELECT l2_distance(c1, [1,2,3]), l2_distance([1,2,3],[1,1,1]), l2_distance('[1,1,1]','[1,2,3]') FROM t1;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+--------------------------+------------------------------+----------------------------------+
|
||||
| l2_distance(c1, [1,2,3]) | l2_distance([1,2,3],[1,1,1]) | l2_distance('[1,1,1]','[1,2,3]') |
|
||||
+--------------------------+------------------------------+----------------------------------+
|
||||
| 0 | 2.23606797749979 | 2.23606797749979 |
|
||||
+--------------------------+------------------------------+----------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### L2_squared
|
||||
|
||||
L2 Squared distance is the square of the Euclidean distance (L2 Distance). It omits the square root operation in the Euclidean distance formula, thereby reducing computational cost while maintaining the relative order of distances. The calculation method is as follows:
|
||||
|
||||
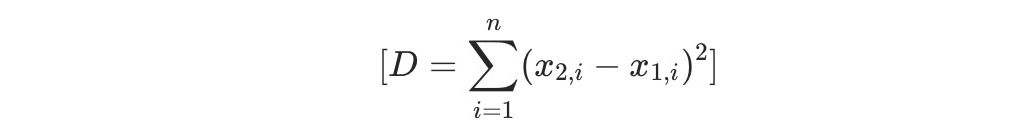
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
l2_squared(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1(c1 vector(3));
|
||||
INSERT INTO t1 VALUES('[1,2,3]');
|
||||
SELECT l2_squared(c1, [1,2,3]), l2_squared([1,2,3],[1,1,1]), l2_squared('[1,1,1]','[1,2,3]') FROM t1;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+-------------------------+-----------------------------+---------------------------------+
|
||||
| l2_squared(c1, [1,2,3]) | l2_squared([1,2,3],[1,1,1]) | l2_squared('[1,1,1]','[1,2,3]') |
|
||||
+-------------------------+-----------------------------+---------------------------------+
|
||||
| 0 | 5 | 5 |
|
||||
+-------------------------+-----------------------------+---------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### L1_distance
|
||||
|
||||
The Manhattan distance is used to calculate the sum of absolute axis distances between two points in a standard coordinate system. The calculation formula is as follows:
|
||||
|
||||
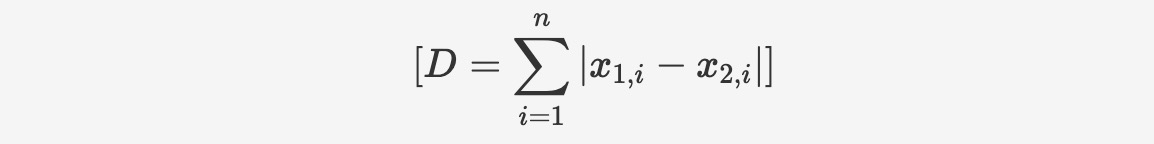
|
||||
|
||||
The function syntax is as follows:
|
||||
|
||||
```sql
|
||||
l1_distance(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t2(c1 vector(3));
|
||||
INSERT INTO t2 VALUES('[1,2,3]');
|
||||
INSERT INTO t2 VALUES('[1,1,1]');
|
||||
SELECT l1_distance(c1, [1,2,3]) FROM t2;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+--------------------------+
|
||||
| l1_distance(c1, [1,2,3]) |
|
||||
+--------------------------+
|
||||
| 0 |
|
||||
| 3 |
|
||||
+--------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
### Cosine_distance
|
||||
|
||||
Cosine similarity measures the angular difference between two vectors and reflects their directional similarity, regardless of their lengths (magnitude). The value range of cosine similarity is `[-1, 1]`, where `1` indicates vectors in exactly the same direction, `0` indicates orthogonality, and `-1` indicates completely opposite directions.
|
||||
|
||||
The calculation method for cosine similarity is as follows:
|
||||
|
||||
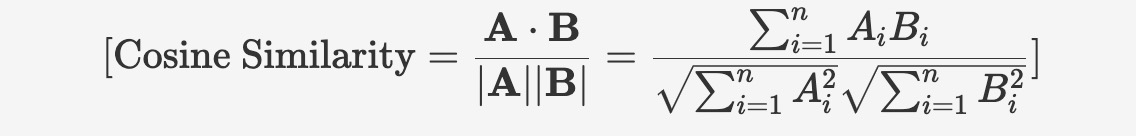
|
||||
|
||||
Since cosine similarity closer to 1 indicates greater similarity, cosine distance (or cosine dissimilarity) is sometimes used as a measure of distance between vectors. Cosine distance can be calculated by subtracting cosine similarity from 1:
|
||||
|
||||
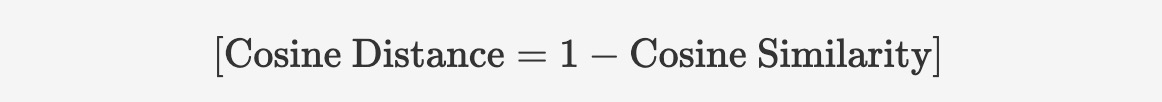
|
||||
|
||||
The value range of cosine distance is `[0, 2]`, where `0` indicates exactly the same direction (no distance) and `2` indicates completely opposite directions.
|
||||
|
||||
The function syntax is as follows:
|
||||
|
||||
```sql
|
||||
cosine_distance(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t3(c1 vector(3));
|
||||
INSERT INTO t3 VALUES('[1,2,3]');
|
||||
INSERT INTO t3 VALUES('[1,2,1]');
|
||||
SELECT cosine_distance(c1, [1,2,3]) FROM t3;
|
||||
```
|
||||
|
||||
```shell
|
||||
+------------------------------+
|
||||
| cosine_distance(c1, [1,2,3]) |
|
||||
+------------------------------+
|
||||
| 0 |
|
||||
| 0.12712843905603044 |
|
||||
+------------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
### Inner_product
|
||||
|
||||
The inner product, also known as the dot product or scalar product, represents a type of multiplication between two vectors. In geometric terms, the inner product indicates the direction and magnitude relationship between two vectors. The calculation method for the inner product is as follows:
|
||||
|
||||
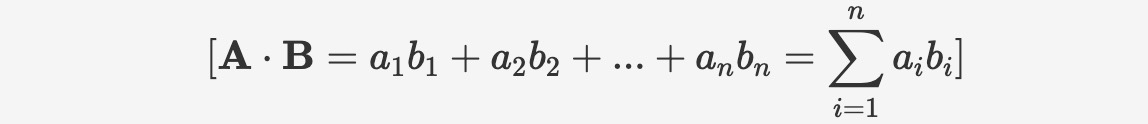
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
inner_product(vector v1, vector v2)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
* For sparse vectors using this function, one parameter can be a string in sparse vector format, such as `c2,'{1:2.4}'`. Two parameters cannot both be strings.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Dense vector example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t4(c1 vector(3));
|
||||
INSERT INTO t4 VALUES('[1,2,3]');
|
||||
INSERT INTO t4 VALUES('[1,2,1]');
|
||||
SELECT inner_product(c1, [1,2,3]) FROM t4;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----------------------------+
|
||||
| inner_product(c1, [1,2,3]) |
|
||||
+----------------------------+
|
||||
| 14 |
|
||||
| 8 |
|
||||
+----------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
Sparse vector example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t4(c1 INT, c2 SPARSEVECTOR, c3 SPARSEVECTOR);
|
||||
INSERT INTO t4 VALUES(1, '{1:1.1, 2:2.2}', '{1:2.4}');
|
||||
INSERT INTO t4 VALUES(2, '{1:1.5, 3:3.6}', '{4:4.5}');
|
||||
SELECT inner_product(c2,c3) FROM t4;
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----------------------+
|
||||
| inner_product(c2,c3) |
|
||||
+----------------------+
|
||||
| 2.640000104904175 |
|
||||
| 0 |
|
||||
+----------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
### Vector_distance
|
||||
|
||||
The vector_distance function calculates the distance between two vectors. You can specify parameters to select different distance algorithms.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
vector_distance(vector v1, vector v2 [, string metric])
|
||||
```
|
||||
|
||||
The `vector v1/v2` parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The `metric` parameter is used to specify the distance algorithm. Options:
|
||||
|
||||
* If not specified, the default algorithm is `euclidean`.
|
||||
|
||||
* If specified, the only valid values are:
|
||||
|
||||
* `euclidean`. Represents Euclidean distance, same as L2_distance.
|
||||
|
||||
* `manhattan`. Represents Manhattan distance, same as L1_distance.
|
||||
|
||||
* `cosine`. Represents cosine distance, same as Cosine_distance.
|
||||
|
||||
* `dot`. Represents inner product, same as Inner_product.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `distance(double)` distance value.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t5(c1 vector(3));
|
||||
INSERT INTO t5 VALUES('[1,2,3]');
|
||||
INSERT INTO t5 VALUES('[1,2,1]');
|
||||
SELECT vector_distance(c1, [1,2,3], euclidean) FROM t5;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+-----------------------------------------+
|
||||
| vector_distance(c1, [1,2,3], euclidean) |
|
||||
+-----------------------------------------+
|
||||
| 0 |
|
||||
| 2 |
|
||||
+-----------------------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
## Arithmetic functions
|
||||
|
||||
Arithmetic functions provide element-wise addition (+), subtraction (-), and multiplication (*) operations between vector types and vector types, single-level array types, and special string types, as well as between single-level array types and single-level array types, and special string types. The calculation method is element-wise, as shown for addition:
|
||||
|
||||
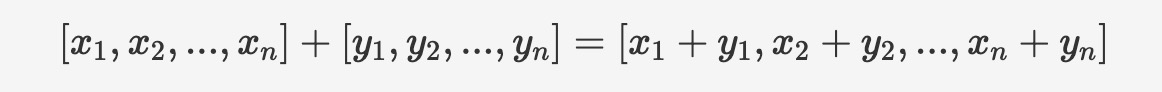
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
v1 + v2
|
||||
v1 - v2
|
||||
v1 * v2
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`). **Note**: Two parameters cannot both be string types. At least one parameter must be a vector or single-level array type.
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* When at least one of the two parameters is a vector type, the return value is of the same vector type as the vector parameter.
|
||||
|
||||
* When both parameters are single-level array types, the return value is of the `array(float)` type.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t6(c1 vector(3));
|
||||
INSERT INTO t6 VALUES('[1,2,3]');
|
||||
SELECT [1,2,3] + '[1.12,1000.0001, -1.2222]', c1 - [1,2,3] FROM t6;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------------------------------------+--------------+
|
||||
| [1,2,3] + '[1.12,1000.0001, -1.2222]' | c1 - [1,2,3] |
|
||||
+---------------------------------------+--------------+
|
||||
| [2.12,1002,1.7778] | [0,0,0] |
|
||||
+---------------------------------------+--------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## Comparison functions
|
||||
|
||||
Comparison functions provide comparison calculations between vector types and vector types, single-level array types, and special string types, including the comparison operators `=`, `!=`, `>`, `>=`, `<`, and `<=`. The calculation method is element-wise dictionary order comparison.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
v1 = v2
|
||||
v1 != v2
|
||||
v1 > v2
|
||||
v1 < v2
|
||||
v1 >= v2
|
||||
v1 <= v2
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
:::tip
|
||||
One of the two parameters must be a vector type.
|
||||
:::
|
||||
|
||||
* The dimensions of the two parameters must be the same.
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is of the bool type.
|
||||
|
||||
* If any parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t7(c1 vector(3));
|
||||
INSERT INTO t7 VALUES('[1,2,3]');
|
||||
SELECT c1 = '[1,2,3]' FROM t7;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+----------------+
|
||||
| c1 = '[1,2,3]' |
|
||||
+----------------+
|
||||
| 1 |
|
||||
+----------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## Aggregate functions
|
||||
|
||||
:::tip
|
||||
Vector columns cannot be used as GROUP BY conditions, and DISTINCT is not supported.
|
||||
:::
|
||||
|
||||
### Sum
|
||||
|
||||
The Sum function is used to calculate the sum of vectors in a vector column of a table, using element-wise accumulation to obtain the sum vector.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
sum(vector v1)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Only the vector type is supported.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `sum (vector)` value.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t8(c1 vector(3));
|
||||
INSERT INTO t8 VALUES('[1,2,3]');
|
||||
SELECT sum(c1) FROM t8;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------+
|
||||
| sum(c1) |
|
||||
+---------+
|
||||
| [1,2,3] |
|
||||
+---------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Avg
|
||||
|
||||
The Avg function is used to calculate the average of vectors in a vector column of a table.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
avg(vector v1)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Only the vector type is supported.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is an `avg (vector)` value.
|
||||
|
||||
* `NULL` rows in the vector column are not counted.
|
||||
|
||||
* When the input parameter is empty, the output is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t9(c1 vector(3));
|
||||
INSERT INTO t9 VALUES('[1,2,3]');
|
||||
SELECT avg(c1) FROM t9;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------+
|
||||
| avg(c1) |
|
||||
+---------+
|
||||
| [1,2,3] |
|
||||
+---------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## Other common vector functions
|
||||
|
||||
### Vector_norm
|
||||
|
||||
The Vector_norm function calculates the Euclidean norm (or length) of a vector, which represents the Euclidean distance between the vector and the origin. The calculation formula is as follows:
|
||||
|
||||
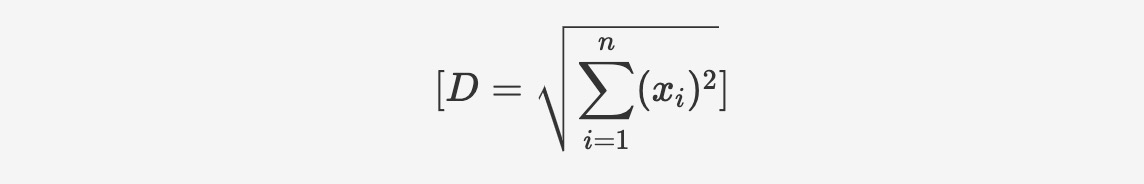
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
vector_norm(vector v1)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
* If a single-level array type parameter exists, its elements cannot be `NULL`.
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `norm(double)` modulus value.
|
||||
|
||||
* If the parameter is `NULL`, the return value is `NULL`.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t10(c1 vector(3));
|
||||
INSERT INTO t10 VALUES('[1,2,3]');
|
||||
SELECT vector_norm(c1),vector_norm([1,2,3]) FROM t10;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+--------------------+----------------------+
|
||||
| vector_norm(c1) | vector_norm([1,2,3]) |
|
||||
+--------------------+----------------------+
|
||||
| 3.7416573867739413 | 3.7416573867739413 |
|
||||
+--------------------+----------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Vector_dims
|
||||
|
||||
The Vector_dims function is used to return the vector dimension.
|
||||
|
||||
The syntax is as follows:
|
||||
|
||||
```sql
|
||||
vector_dims(vector v1)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* Apart from the vector type, other types that can be forcibly converted to the vector type are accepted, including single-level array types (such as `[1,2,3,..]`) and string types (such as `'[1,2,3]'`).
|
||||
|
||||
The return values are described as follows:
|
||||
|
||||
* The return value is a `dims(int64)` dimension value.
|
||||
|
||||
* If the parameter is `NULL`, an error is returned.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t11(c1 vector(3));
|
||||
INSERT INTO t11 VALUES('[1,2,3]');
|
||||
INSERT INTO t11 VALUES('[1,1,1]');
|
||||
SELECT vector_dims(c1), vector_dims('[1,2,3]') FROM t11;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+-----------------+------------------------+
|
||||
| vector_dims(c1) | vector_dims('[1,2,3]') |
|
||||
+-----------------+------------------------+
|
||||
| 3 | 3 |
|
||||
| 3 | 3 |
|
||||
+-----------------+------------------------+
|
||||
2 rows in set
|
||||
```
|
||||
@@ -0,0 +1,232 @@
|
||||
---
|
||||
|
||||
slug: /vector-similarity-search
|
||||
---
|
||||
|
||||
# Vector similarity search
|
||||
|
||||
Vector similarity search, also known as nearest neighbor search, is a search method based on distance metrics in vector space. Its core objective is to find the set of vectors most similar to a given query vector. Although specific distance metrics are used during computation, the final output is the Top K nearest vectors, sorted in ascending order of distance.
|
||||
|
||||
This topic describes two vector search methods in seekdb: exact nearest neighbor search based on full-scan and approximate nearest neighbor search based on vector index. It also provides examples to illustrate how to use these methods.
|
||||
|
||||
:::tip
|
||||
For readability, this document refers to vector nearest neighbor search as "vector search," exact nearest neighbor search as "exact search," and approximate nearest neighbor search as "approximate search."
|
||||
:::
|
||||
|
||||
## Perform exact search
|
||||
|
||||
Exact search uses a full scan strategy, calculating the distance between the query vector and all vectors in the dataset to perform an exact search. This method ensures complete accuracy of the search results, but because it requires calculating the distance for all data, the search performance decreases significantly as the dataset grows.
|
||||
|
||||
When executing an exact search, the system calculates and compares the distances between the query vector vₑ and all other vectors in the vector space. After completing the full distance calculations, the system selects the k vectors closest to the query as the search results.
|
||||
|
||||
### Example: Euclidean search
|
||||
|
||||
Euclidean similarity search is used to retrieve the top-k vectors in the vector space that are closest to the query vector, using Euclidean distance as the metric. The following example demonstrates how to use exact search to retrieve the top 5 vectors from a table that are closest to the query vector:
|
||||
|
||||
```sql
|
||||
-- Create a test table
|
||||
CREATE TABLE t1 (
|
||||
id INT PRIMARY KEY,
|
||||
c1 VECTOR(3)
|
||||
);
|
||||
|
||||
-- Insert data
|
||||
INSERT INTO t1 VALUES
|
||||
(1, '[0.1, 0.2, 0.3]'),
|
||||
(2, '[0.2, 0.3, 0.4]'),
|
||||
(3, '[0.3, 0.4, 0.5]'),
|
||||
(4, '[0.4, 0.5, 0.6]'),
|
||||
(5, '[0.5, 0.6, 0.7]'),
|
||||
(6, '[0.6, 0.7, 0.8]'),
|
||||
(7, '[0.7, 0.8, 0.9]'),
|
||||
(8, '[0.8, 0.9, 1.0]'),
|
||||
(9, '[0.9, 1.0, 0.1]'),
|
||||
(10, '[1.0, 0.1, 0.2]');
|
||||
|
||||
-- Perform an exact search
|
||||
SELECT c1
|
||||
FROM t1
|
||||
ORDER BY l2_distance(c1, '[0.1, 0.2, 0.3]') LIMIT 5;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------------+
|
||||
| c1 |
|
||||
+---------------+
|
||||
| [0.1,0.2,0.3] |
|
||||
| [0.2,0.3,0.4] |
|
||||
| [0.3,0.4,0.5] |
|
||||
| [0.4,0.5,0.6] |
|
||||
| [0.5,0.6,0.7] |
|
||||
+---------------+
|
||||
5 rows in set
|
||||
```
|
||||
|
||||
### Analyze the execution plan
|
||||
|
||||
Obtain the execution plan of the preceding example:
|
||||
|
||||
```sql
|
||||
EXPLAIN SELECT c1
|
||||
FROM t1
|
||||
ORDER BY l2_distance(c1, '[0.1, 0.2, 0.3]') LIMIT 5;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+---------------------------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+---------------------------------------------------------------------------------------------+
|
||||
| ================================================= |
|
||||
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
|
||||
| ------------------------------------------------- |
|
||||
| |0 |TOP-N SORT | |5 |3 | |
|
||||
| |1 |└─TABLE FULL SCAN|t1 |10 |3 | |
|
||||
| ================================================= |
|
||||
| Outputs & filters: |
|
||||
| ------------------------------------- |
|
||||
| 0 - output([t1.c1]), filter(nil), rowset=16 |
|
||||
| sort_keys([l2_distance(t1.c1, cast('[0.1, 0.2, 0.3]', ARRAY(18, -1))), ASC]), topn(5) |
|
||||
| 1 - output([t1.c1]), filter(nil), rowset=16 |
|
||||
| access([t1.c1]), partitions(p0) |
|
||||
| is_index_back=false, is_global_index=false, |
|
||||
| range_key([t1.id]), range(MIN ; MAX)always true |
|
||||
+---------------------------------------------------------------------------------------------+
|
||||
14 rows in set
|
||||
```
|
||||
|
||||
The analysis is as follows:
|
||||
|
||||
* Execution method:
|
||||
* The full-table scan method is used, which requires traversing all data in the table. The `TABLE FULL SCAN` operation in the execution plan scans all data in the `t1` table.
|
||||
* The system calculates the vector distance for each record and then sorts the records by distance. The `TOP-N SORT` operation in the execution plan calculates the vector distance using the `l2_distance` function and sorts the records by distance in ascending order.
|
||||
* The system returns the five records with the smallest distances. The `topn(5)` setting in the execution plan indicates that only the first five records of the sorted list are returned.
|
||||
|
||||
* Performance characteristics:
|
||||
* Advantages: The search results are completely accurate and ensure that the true nearest neighbors are returned.
|
||||
* Disadvantages: The system must scan all data in the table and calculate the distance between all vectors, leading to a significant drop in performance as the data volume increases.
|
||||
|
||||
* Applicable scenarios:
|
||||
* Scenarios with a small amount of data.
|
||||
* Scenarios where high result accuracy is required.
|
||||
* Scenarios where real-time queries are not suitable for large datasets.
|
||||
|
||||
## Perform approximate search by using vector indexes
|
||||
|
||||
Vector index search uses an approximate nearest neighbor (ANN) strategy, accelerating the search process through pre-built index structures. While it cannot guarantee 100% result accuracy, it can significantly improve search performance, allowing for a good balance between accuracy and efficiency in practical applications.
|
||||
|
||||
### Example: Approximate search by using the HNSW index
|
||||
|
||||
```sql
|
||||
-- Create a HNSW vector index with the table.
|
||||
CREATE TABLE t2 (
|
||||
id INT PRIMARY KEY,
|
||||
vec VECTOR(3),
|
||||
VECTOR INDEX idx(vec) WITH (distance=l2, type=hnsw, lib=vsag)
|
||||
);
|
||||
|
||||
-- Insert test data
|
||||
INSERT INTO t2 VALUES
|
||||
(1, '[0.1, 0.2, 0.3]'),
|
||||
(2, '[0.2, 0.3, 0.4]'),
|
||||
(3, '[0.3, 0.4, 0.5]'),
|
||||
(4, '[0.4, 0.5, 0.6]'),
|
||||
(5, '[0.5, 0.6, 0.7]'),
|
||||
(6, '[0.6, 0.7, 0.8]'),
|
||||
(7, '[0.7, 0.8, 0.9]'),
|
||||
(8, '[0.8, 0.9, 1.0]'),
|
||||
(9, '[0.9, 1.0, 0.1]'),
|
||||
(10, '[1.0, 0.1, 0.2]');
|
||||
|
||||
-- Perform approximate search and return the 5 most similar data records
|
||||
SELECT id, vec
|
||||
FROM t2
|
||||
ORDER BY l2_distance(vec, '[0.1, 0.2, 0.3]')
|
||||
APPROXIMATE
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
The return result is as follows. The result is the same as that of the exact search because the data volume is small:
|
||||
|
||||
```shell
|
||||
+------+---------------+
|
||||
| id | vec |
|
||||
+------+---------------+
|
||||
| 1 | [0.1,0.2,0.3] |
|
||||
| 2 | [0.2,0.3,0.4] |
|
||||
| 3 | [0.3,0.4,0.5] |
|
||||
| 4 | [0.4,0.5,0.6] |
|
||||
| 5 | [0.5,0.6,0.7] |
|
||||
+------+---------------+
|
||||
5 rows in set
|
||||
```
|
||||
|
||||
### Execution plan analysis
|
||||
|
||||
Obtain the execution plan of the preceding example:
|
||||
|
||||
```sql
|
||||
EXPLAIN SELECT id, vec
|
||||
FROM t2
|
||||
ORDER BY l2_distance(vec, '[0.1, 0.2, 0.3]')
|
||||
APPROXIMATE
|
||||
LIMIT 5;
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
```shell
|
||||
+--------------------------------------------------------------------------------------------------------------------+
|
||||
| Query Plan |
|
||||
+--------------------------------------------------------------------------------------------------------------------+
|
||||
| ==================================================== |
|
||||
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
|
||||
| ---------------------------------------------------- |
|
||||
| |0 |VECTOR INDEX SCAN|t2(idx)|10 |29 | |
|
||||
| ==================================================== |
|
||||
| Outputs & filters: |
|
||||
| ------------------------------------- |
|
||||
| 0 - output([t2.id], [t2.vec]), filter(nil), rowset=16 |
|
||||
| access([t2.id], [t2.vec]), partitions(p0) |
|
||||
| is_index_back=true, is_global_index=false, |
|
||||
| range_key([t2.__vid_1750162978114053], [t2.__type_17_1750162978114364]), range(MIN,MIN ; MAX,MAX)always true |
|
||||
+--------------------------------------------------------------------------------------------------------------------+
|
||||
11 rows in set
|
||||
```
|
||||
|
||||
The analysis is as follows:
|
||||
|
||||
* Execution method:
|
||||
* The vector index scan method is used, directly locating similar vectors through the pre-built HNSW index. The `VECTOR INDEX SCAN` operation in the execution plan uses the index `t2(idx)` for retrieval.
|
||||
* The graph structure of the index is used to quickly locate nearest neighbors without calculating the distance between all vectors. The `is_index_back=true` setting in the execution plan indicates that complete data is retrieved through index back-lookup.
|
||||
* The five records that the index considers to be the most similar are returned. The `output([t2.id], [t2.vec])` in the execution plan indicates that the id and vector data are returned.
|
||||
|
||||
* Performance characteristics:
|
||||
* Advantage: The search performance is high and remains stable as the data volume increases.
|
||||
* Disadvantage: A small amount of error may exist in the results, and 100% accuracy is not guaranteed.
|
||||
|
||||
* Applicable scenarios:
|
||||
* Real-time search for large-scale datasets.
|
||||
* Scenarios with high requirements for search performance.
|
||||
* Scenarios that can tolerate a small amount of result error.
|
||||
|
||||
## Summary
|
||||
|
||||
A comparison of the two search methods is as follows:
|
||||
|
||||
| Item | Exact search | Approximate search |
|
||||
|--------|----------------|----------------|
|
||||
| Execution method | Full-table scan (`TABLE FULL SCAN`) followed by sorting | Direct search through the vector index (`VECTOR INDEX SCAN`) |
|
||||
| Execution plan | Contains two operators: `TABLE FULL SCAN` and `TOP-N SORT` | Contains only one operator: `VECTOR INDEX SCAN` |
|
||||
| Performance characteristics | Requires full-table scan and sorting, and performance decreases significantly as the data volume increases | Directly locates target data through the index, and performance is stable |
|
||||
| Result accuracy | 100% accurate, ensuring real nearest neighbors are returned | Approximately accurate, with a small amount of error possible |
|
||||
| Applicable scenarios | Scenarios with small data volumes and high accuracy requirements | Scenarios with large-scale datasets and high performance requirements |
|
||||
|
||||
### References
|
||||
|
||||
* For more information about SQL functions, see [Use SQL functions](250.vector-function.md).
|
||||
* For more information about vector indexes and examples, see [Create vector indexes](200.vector-index/200.dense-vector-index.md).
|
||||
* To perform large-scale performance tests, we recommend that you use the [VectorDBBenchmark tool](700.vector-search-benchmark-test.md) to generate a test dataset to better compare the performance differences between exact search and approximate search.
|
||||
@@ -0,0 +1,127 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-benchmark-test
|
||||
---
|
||||
|
||||
# Benchmark testing with VectorDBBench
|
||||
|
||||
VectorDBBench is a benchmarking tool designed to provide benchmark test results for mainstream vector databases and cloud services. This topic explains how to use VectorDBBench to test the performance of seekdb vector database. Designed for ease of use, VectorDBBench allows you to easily replicate test results or test new systems.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* Deploy seekdb.
|
||||
* Install Python 3.11 or later. The following example uses Conda for installation:
|
||||
```bash
|
||||
# Download and install Conda
|
||||
mkdir -p ~/miniconda3
|
||||
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
|
||||
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
|
||||
rm ~/miniconda3/miniconda.sh
|
||||
|
||||
# Reopen your terminal and initialize Conda
|
||||
source ~/miniconda3/bin/activate
|
||||
conda init --all
|
||||
|
||||
# Create and initialize the Python environment required by VectorDBBench
|
||||
conda create -n vdb python=3.11
|
||||
conda activate vdb
|
||||
```
|
||||
* Connect to the database and optimize memory and query parameters for HNSW vector index searches:
|
||||
|
||||
```sql
|
||||
-- Set ob_vector_memory_limit_percentage to 30%.
|
||||
ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30;
|
||||
-- Set ob_query_timeout to 24 hours.
|
||||
SET GLOBAL ob_query_timeout = 86400000000;
|
||||
-- Set max_allowed_packet to 1 GB.
|
||||
SET GLOBAL max_allowed_packet=1073741824;
|
||||
-- Set ddl_thread_score and parallel_servers_target to configure parallelism when creating indexes
|
||||
ALTER SYSTEM SET ddl_thread_score = 8; -- Parallelism for DDL operations
|
||||
SET GLOBAL parallel_servers_target = 624; -- Number of parallel queries the database server can handle simultaneously
|
||||
```
|
||||
Here, `ob_vector_memory_limit_percentage = 30` is only an example value. Adjust it based on the database memory and workload.
|
||||
|
||||
## Recommended configuration
|
||||
|
||||
The recommended resource specifications for the database are as follows:
|
||||
|
||||
| Parameter | Value |
|
||||
|-------|----|
|
||||
| Memory | 64 GB |
|
||||
| CPU | 16 cores |
|
||||
|
||||
## Testing methods
|
||||
|
||||
### Clone the VectorDBBench code
|
||||
|
||||
:::tip
|
||||
We recommend that you deploy VectorDBBench and seekdb on separate servers to avoid CPU resource contention and improve the reliability of test results.
|
||||
:::
|
||||
|
||||
Clone the VectorDBBench test tool code to your local server.
|
||||
|
||||
```bash
|
||||
git clone https://github.com/zilliztech/VectorDBBench.git
|
||||
```
|
||||
|
||||
### Install dependencies
|
||||
|
||||
Go to the VectorDBBench directory and install the dependencies.
|
||||
|
||||
```bash
|
||||
cd VectorDBBench
|
||||
pip install .
|
||||
```
|
||||
|
||||
### Run the test
|
||||
|
||||
Run VectorDBBench. Two examples are provided here: HNSW index and IVF index.
|
||||
|
||||
#### HNSW index example
|
||||
|
||||
```bash
|
||||
# Replace $host, $port, and $user with the actual seekdb connection information.
|
||||
vectordbbench oceanbasehnsw --host $host --port $port --user $user --database test --m 16 --ef-construction 200 --ef-search 40 --k 10 --case-type Performance768D1M --index-type HNSW
|
||||
```
|
||||
|
||||
For more information about the parameters, run the following command:
|
||||
|
||||
```bash
|
||||
vectordbbench oceanbasehnsw --help
|
||||
```
|
||||
|
||||
Commonly used options are described as follows:
|
||||
|
||||
* `--num-concurrency`: Used to adjust the concurrency level. VectorDBBench executes vector queries with the specified concurrency and selects the highest QPS (Queries Per Second) as the final result.
|
||||
* `--skip-drop-old`/`--skip-load`: Skips the deletion of old data and the data loading step. After adding these two options to the command line, the command only performs vector query operations and does not delete old data or reload data.
|
||||
* `--k`: Specifies the number of top-k nearest neighbor results to return in a vector query.
|
||||
* `--ef-search`: HNSW query parameter that indicates the size of the candidate set during query.
|
||||
* `--index-type`: Specifies the index type. Currently supports `HNSW`, `HNSW_SQ`, and `HNSW_BQ`.
|
||||
|
||||
#### IVF index example
|
||||
|
||||
```bash
|
||||
vectordbbench oceanbaseivf --host $host --port $port --user $user --database test --nlist 1000 --sample_per_nlist 256 --ivf_nprobes 100 --case-type Performance768D1M --index-type IVF_FLAT
|
||||
```
|
||||
|
||||
Commonly used options are described as follows:
|
||||
|
||||
* `--sample_per_nlist`: The amount of data sampled per cluster center. Default value is `256`.
|
||||
* `--ivf_nprobes`: Used to set how many nearest cluster centers to search in this query when performing vector index queries. Default value is `8`. The larger the value, the higher the recall rate, but the search time also increases.
|
||||
* `--index-type`: Specifies the index type. Currently supports `IVF_FLAT`.
|
||||
|
||||
For more information about the parameters, run the following command:
|
||||
|
||||
```bash
|
||||
vectordbbench oceanbaseivf --help
|
||||
```
|
||||
|
||||
## FAQs
|
||||
|
||||
### Is it normal for the first test execution to be slow?
|
||||
|
||||
The first test execution requires downloading the required dataset from AWS S3 storage, which may take relatively longer. This is normal.
|
||||
|
||||
### Can I customize and modify the test code?
|
||||
|
||||
Yes, you can. If you customize and modify the test code, you need to run `pip install .` again before running the test.
|
||||
@@ -0,0 +1,61 @@
|
||||
---
|
||||
|
||||
slug: /vector-data-type
|
||||
---
|
||||
|
||||
# Overview of vector data types
|
||||
|
||||
seekdb provides vector data types to support AI vector search applications. By using vector data types, you can store and query an array of floating-point numbers, such as `[0.1, 0.3, -0.9, ...]`. Before using vector data, you need to be aware of the following:
|
||||
|
||||
* Both dense and sparse vector data are supported, and all data elements must be single-precision floating-point numbers.
|
||||
|
||||
* Element values in vector data cannot be NaN (not a number) or Inf (infinity); otherwise, a runtime error will be thrown.
|
||||
|
||||
* You must specify the vector dimension when creating a vector column, for example, `VECTOR(3)`.
|
||||
|
||||
* Creating dense/sparse vector indexes is supported. For details, see [vector index](../200.vector-index/200.dense-vector-index.md).
|
||||
|
||||
* Vector data in seekdb is stored in array form.
|
||||
|
||||
* Both dense and sparse vectors support [hybrid search](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001970893).
|
||||
|
||||
## Syntax
|
||||
|
||||
A dense vector value can contain any number of floating-point numbers up to 16,000. The syntax is as follows:
|
||||
|
||||
```sql
|
||||
-- Dense vector
|
||||
'[<float>, <float>, ...]'
|
||||
```
|
||||
|
||||
A sparse vector is based on the MAP data type and contains unordered key-value pairs. The syntax is as follows:
|
||||
|
||||
```sql
|
||||
-- Sparse vector
|
||||
'{<uint:float>, <uint:float>...}'
|
||||
```
|
||||
|
||||
Examples of creating vector columns and indexes are as follows:
|
||||
|
||||
```sql
|
||||
-- Create a dense vector column and index
|
||||
CREATE TABLE t1(
|
||||
c1 INT,
|
||||
c2 VECTOR(3),
|
||||
PRIMARY KEY(c1),
|
||||
VECTOR INDEX idx1(c2) WITH (distance=L2, type=hnsw)
|
||||
);
|
||||
```
|
||||
|
||||
```sql
|
||||
-- Create a sparse vector column
|
||||
CREATE TABLE t2 (
|
||||
c1 INT,
|
||||
c2 SPARSEVECTOR
|
||||
);
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Create vector indexes](../200.vector-index/200.dense-vector-index.md)
|
||||
* [Use SQL functions](../250.vector-function.md)
|
||||
@@ -0,0 +1,391 @@
|
||||
---
|
||||
|
||||
slug: /vector-sdk-refer
|
||||
---
|
||||
|
||||
# Compatibility
|
||||
|
||||
This topic describes the data model mappings, SDK interface compatibility, and concept mappings between seekdb's vector search feature and Milvus.
|
||||
|
||||
## Concept mappings
|
||||
|
||||
To help users familiar with Milvus quickly get started with seekdb's vector storage capabilities, we analyze the similarities and differences between the two systems and provide a mapping of related concepts.
|
||||
|
||||
### Data models
|
||||
|
||||
| **Data model layer** | **Milvus** | **seekdb** | **Description** |
|
||||
|------------|---------|-----------|-----------|
|
||||
| First layer | Shards | Partition | Milvus specifies partition rules by setting some columns as `partition_key` in the schema definition.<br/>seekdb supports range/range columns, list/list columns, hash, key, and subpartitioning strategies. |
|
||||
| Second layer | Partitions | ≈Tablet | Milvus enhances read performance by chunking the same shard (shards are usually partitioned by primary key) based on other columns.<br />seekdb implements this by sorting keys within a partition. |
|
||||
| Third layer | Segments | MemTable+SSTable | Both have a minor compaction mechanism. |
|
||||
|
||||
### SDKs
|
||||
|
||||
This section introduces the conceptual differences between seekdb's vector storage SDK (pyobvector) and Milvus's SDK (pymilvus).
|
||||
|
||||
pyobvector supports two usage modes:
|
||||
|
||||
1. pymilvus MilvusClient lightweight compatible mode: This mode is compatible with common interfaces of Milvus clients. Users familiar with Milvus can easily use this mode without concept mapping.
|
||||
|
||||
2. SQLAlchemy extension mode: This mode can be used as a vector feature extension of python SQLAlchemy, retaining the operation mode of a relational database. Concept mapping is required.
|
||||
|
||||
For more information about pyobvector's APIs, see [pyobvector Python SDK API reference](900.vector-search-supported-clients-and-languages/200.vector-pyobvector.md).
|
||||
|
||||
The following table describes the concept mappings between pyobvector's SQLAlchemy extension mode and pymilvus:
|
||||
|
||||
| **pymilvus** | **pyobvector** | **Description** |
|
||||
|---------|------------|---------------|
|
||||
| Database | Database | Database |
|
||||
| Collection | Table | Table |
|
||||
| Field | Column | Column |
|
||||
| Primary Key | Primary Key | Primary key |
|
||||
| Vector Field | Vector Column | Vector column |
|
||||
| Index | Index | Index |
|
||||
| Partition | Partition | Partition |
|
||||
| DataType | DataType | Data type |
|
||||
| Metric Type | Distance Function | Distance function |
|
||||
| Search | Query | Query |
|
||||
| Insert | Insert | Insert |
|
||||
| Delete | Delete | Delete |
|
||||
| Update | Update | Update |
|
||||
| Batch | Batch | Batch operations |
|
||||
| Transaction | Transaction | Transaction |
|
||||
| NONE | Not supported| NULL value |
|
||||
| BOOL | Boolean | Corresponds to the MySQL TINYINT type |
|
||||
| INT8 | Boolean | Corresponds to the MySQL TINYINT type |
|
||||
| INT16 | SmallInteger | Corresponds to the MySQL SMALLINT type |
|
||||
| INT32 | Integer | Corresponds to the MySQL INT type |
|
||||
| INT64 | BigInteger | Corresponds to the MySQL BIGINT type |
|
||||
| FLOAT | Float | Corresponds to the MySQL FLOAT type |
|
||||
| DOUBLE | Double | Corresponds to the MySQL DOUBLE type |
|
||||
| STRING | LONGTEXT | Corresponds to the MySQL LONGTEXT type |
|
||||
| VARCHAR | STRING | Corresponds to the MySQL VARCHAR type |
|
||||
| JSON | JSON | For differences and similarities in JSON operations, see [pyobvector Python SDK API reference](900.vector-search-supported-clients-and-languages/200.vector-pyobvector.md). |
|
||||
| FLOAT_VECTOR | VECTOR | Vector type |
|
||||
| BINARY_VECTOR | Not supported | |
|
||||
| FLOAT16_VECTOR | Not supported | |
|
||||
| BFLOAT16_VECTOR | Not supported | |
|
||||
| SPARSE_FLOAT_VECTOR | Not supported | |
|
||||
| dynamic_field | Not needed | The hidden `$meta` metadata column in Milvus.<br/>In seekdb, you can explicitly create a JSON-type column. |
|
||||
|
||||
## Compatibility with Milvus
|
||||
|
||||
### Milvus SDK
|
||||
|
||||
Except `load_collection()`, `release_collection()`, and `close()`, which are supported through SQLAlchemy, all operations listed in the following tables are supported.
|
||||
|
||||
**Collection operations**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| create_collection() | Creates a vector table based on the given schema. |
|
||||
| get_collection_stats() | Queries table statistics, such as the number of rows. |
|
||||
| describe_collection() | Provides detailed metadata of a vector table. |
|
||||
| has_collection() | Checks whether a table exists. |
|
||||
| list_collections() | Lists existing tables. |
|
||||
| drop_collection() | Drops a table. |
|
||||
|
||||
**Field and schema definition**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| create_schema() | Creates a schema in memory and adds column definitions. |
|
||||
| add_field() | The call sequence is: create_schema->add_field->...->add_field<br/>You can also manually build a FieldSchema list and then use the CollectionSchema constructor to create a schema. |
|
||||
|
||||
**Vector indexes**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| list_indexes() | Lists all indexes. |
|
||||
| create_index() | Supports creating multiple vector indexes in a single call. First, use prepare_index_params to initialize an index parameter list object, call add_index multiple times to set multiple index parameters, and finally call create_index to create the indexes. |
|
||||
| drop_index() | Drops a vector index. |
|
||||
| describe_index() | Gets the metadata (schema) of an index. |
|
||||
|
||||
**Vector indexes**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| search() | ANN query interface:<ul><li>collection_name: the table name</li><li>data: the query vectors</li><li>filter: filtering operation, equivalent to `WHERE`</li><li>limit: top K</li><li>output_fields: projected columns, equivalent to `SELECT`</li><li>partition_names: partition names (not supported in Milvus Lite)</li><li>anns_field: the index column name</li><li>search_params: vector distance function name and index algorithm-related parameters</li></ul> |
|
||||
| query() | Point query with filter, namely `SELECT ... WHERE ids IN (..., ...) AND <filters>`. |
|
||||
| get() | Point query without filter, namely `SELECT ... WHERE ids IN (..., ...)`. |
|
||||
| delete() | Deletes a group of vectors, `DELETE FROM ... WHERE ids IN (..., ...)`. |
|
||||
| insert() | Inserts a group of vectors. |
|
||||
| upsert() | Insert with update on primary key conflict. |
|
||||
|
||||
**Collection metadata synchronization**
|
||||
|
||||
| **Interface** | **Description** |
|
||||
|---|---|
|
||||
| load_collection() | Loads the table structure from the database to the Python application memory, enabling the application to operate the database table in an object-oriented manner. This is a standard feature of an object-relational mapping (ORM) framework. |
|
||||
| release_collection() | Releases the loaded table structure from the Python application memory and releases related resources. This is a standard feature of an ORM framework for memory management. |
|
||||
| close() | Closes the database connection and releases related resources. This is a standard feature of an ORM framework. |
|
||||
|
||||
### pymilvus
|
||||
|
||||
#### Data model
|
||||
|
||||
The data model of Milvus comprises three levels: Shards->Partitions->Segments. Compatibility with seekdb is described as follows:
|
||||
|
||||
* Shards correspond to seekdb's Partition concept.
|
||||
|
||||
* Partitions currently have no corresponding concept in seekdb.
|
||||
|
||||
* Milvus allows you to partition a shard into blocks by other columns to improve read performance (shards are usually partitioned by primary key). seekdb implements this by sorting by primary key within a partition.
|
||||
|
||||
* Segments are similar to [MemTable](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001973721) + [SSTable](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001973722).
|
||||
|
||||
#### Milvus Lite API compatibility
|
||||
|
||||
##### collection operations
|
||||
|
||||
1. Milvus create_collection():
|
||||
|
||||
```python
|
||||
create_collection(
|
||||
collection_name: str,
|
||||
dimension: int,
|
||||
primary_field_name: str = "id",
|
||||
id_type: str = DataType,
|
||||
vector_field_name: str = "vector",
|
||||
metric_type: str = "COSINE",
|
||||
auto_id: bool = False,
|
||||
timeout: Optional[float] = None,
|
||||
schema: Optional[CollectionSchema] = None, # Used for custom setup
|
||||
index_params: Optional[IndexParams] = None, # Used for custom setup
|
||||
**kwargs,
|
||||
) -> None
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* collection_name: compatible, corresponds to table_name.
|
||||
|
||||
* dimension: compatible, vector(dim).
|
||||
|
||||
* primary_field_name: compatible, the primary key column name.
|
||||
|
||||
* id_type: compatible, the primary key column type.
|
||||
|
||||
* vector_field_name: compatible, the vector column name.
|
||||
|
||||
* auto_id: compatible, auto increment.
|
||||
|
||||
* timeout: compatible, seekdb supports it through hint.
|
||||
|
||||
* schema: compatible.
|
||||
|
||||
* index_params: compatible.
|
||||
|
||||
2. Milvus get_collection_stats():
|
||||
|
||||
```python
|
||||
get_collection_stats(
|
||||
collection_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> Dict
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* API is compatible.
|
||||
|
||||
* Return value is compatible: `{ 'row_count': ... }`.
|
||||
|
||||
3. Milvus has_collection():
|
||||
|
||||
```python
|
||||
has_collection(
|
||||
collection_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> Bool
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus has_collection().
|
||||
|
||||
4. Milvus drop_collection():
|
||||
|
||||
```python
|
||||
drop_collection(collection_name: str) -> None
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus drop_collection().
|
||||
|
||||
5. Milvus rename_collection():
|
||||
|
||||
```python
|
||||
rename_collection(
|
||||
old_name: str,
|
||||
new_name: str,
|
||||
timeout: Optional[float] = None
|
||||
) -> None
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus rename_collection().
|
||||
|
||||
##### Schema-related
|
||||
|
||||
1. Milvus create_schema():
|
||||
|
||||
```python
|
||||
create_schema(
|
||||
auto_id: bool,
|
||||
enable_dynamic_field: bool,
|
||||
primary_field: str,
|
||||
partition_key_field: str,
|
||||
) -> CollectionSchema
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* auto_id: whether the primary key column is auto-increment, compatible.
|
||||
|
||||
* primary_field & partition_key_field: compatible.
|
||||
|
||||
2. Milvus add_field():
|
||||
|
||||
```python
|
||||
add_field(
|
||||
field_name: str,
|
||||
datatype: DataType,
|
||||
is_primary: bool,
|
||||
max_length: int,
|
||||
element_type: str,
|
||||
max_capacity: int,
|
||||
dim: int,
|
||||
is_partition_key: bool,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus add_field().
|
||||
|
||||
##### Insert/Search-related
|
||||
|
||||
1. Milvus search():
|
||||
|
||||
```python
|
||||
search(
|
||||
collection_name: str,
|
||||
data: Union[List[list], list],
|
||||
filter: str = "",
|
||||
limit: int = 10,
|
||||
output_fields: Optional[List[str]] = None,
|
||||
search_params: Optional[dict] = None,
|
||||
timeout: Optional[float] = None,
|
||||
partition_names: Optional[List[str]] = None,
|
||||
**kwargs,
|
||||
) -> List[dict]
|
||||
```
|
||||
|
||||
seekdb compatibility is described as follows:
|
||||
|
||||
* filter: string expression. For usage examples, see: [Milvus Filtering Explained](https://milvus.io/docs/boolean.md). It is generally similar to SQL's `WHERE` expression.
|
||||
|
||||
* search_params:
|
||||
|
||||
* metric_type: compatible.
|
||||
|
||||
* radius & range filter: related to RNN, currently not supported.
|
||||
|
||||
* group_by_field: groups ANN results, currently not supported.
|
||||
|
||||
* max_empty_result_buckets: used for IVF series indexes, currently not supported.
|
||||
|
||||
* ignore_growing: skips incremental data and directly reads baseline index, currently not supported.
|
||||
|
||||
* partition_names: partition read, supported.
|
||||
|
||||
* kwargs:
|
||||
|
||||
* offset: the number of records to skip in search results, currently not supported.
|
||||
|
||||
* round_decimal: rounds results to specified decimal places, currently not supported.
|
||||
|
||||
2. Milvus get():
|
||||
|
||||
```python
|
||||
get(
|
||||
collection_name: str,
|
||||
ids: Union[list, str, int],
|
||||
output_fields: Optional[List[str]] = None,
|
||||
timeout: Optional[float] = None,
|
||||
partition_names: Optional[List[str]] = None,
|
||||
**kwargs,
|
||||
) -> List[dict]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus get().
|
||||
|
||||
3. Milvus delete()
|
||||
|
||||
```python
|
||||
delete(
|
||||
collection_name: str,
|
||||
ids: Optional[Union[list, str, int]] = None,
|
||||
timeout: Optional[float] = None,
|
||||
filter: Optional[str] = "",
|
||||
partition_name: Optional[str] = "",
|
||||
**kwargs,
|
||||
) -> dict
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus delete().
|
||||
|
||||
4. Milvus insert()
|
||||
|
||||
```python
|
||||
insert(
|
||||
collection_name: str,
|
||||
data: Union[Dict, List[Dict]],
|
||||
timeout: Optional[float] = None,
|
||||
partition_name: Optional[str] = "",
|
||||
) -> List[Union[str, int]]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus insert().
|
||||
|
||||
5. Milvus upsert()
|
||||
|
||||
```python
|
||||
upsert(
|
||||
collection_name: str,
|
||||
data: Union[Dict, List[Dict]],
|
||||
timeout: Optional[float] = None,
|
||||
partition_name: Optional[str] = "",
|
||||
) -> List[Union[str, int]]
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus upsert().
|
||||
|
||||
##### Index-related
|
||||
|
||||
1. Milvus create_index()
|
||||
|
||||
```python
|
||||
create_index(
|
||||
collection_name: str,
|
||||
index_params: IndexParams,
|
||||
timeout: Optional[float] = None,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus create_index().
|
||||
|
||||
2. Milvus drop_index()
|
||||
|
||||
```python
|
||||
drop_index(
|
||||
collection_name: str,
|
||||
index_name: str,
|
||||
timeout: Optional[float] = None,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
seekdb is compatible with Milvus drop_index().
|
||||
|
||||
## Compatibility with MySQL protocol
|
||||
|
||||
* In terms of request initiation: All APIs are implemented through general query SQL, and there are no compatibility issues.
|
||||
|
||||
* In terms of response result set processing: Only processing of new vector data elements needs to be considered. Currently, string and bytes element parsing are supported. Even if the transmission mode of vector data elements changes in the future, compatibility can be achieved by updating the SDK.
|
||||
@@ -0,0 +1,12 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-supported-clients-and-languages-overview
|
||||
---
|
||||
|
||||
# Supported clients and languages for vector search
|
||||
|
||||
| Client/Language | Version |
|
||||
|---|---|
|
||||
| MySQL client | All versions |
|
||||
| Python SDK | 3.9+ |
|
||||
| Java SDK | 1.8 |
|
||||
@@ -0,0 +1,318 @@
|
||||
---
|
||||
|
||||
slug: /vector-pyobvector
|
||||
---
|
||||
|
||||
# pyobvector Python SDK API reference
|
||||
|
||||
pyobvector is the Python SDK for seekdb's vector storage feature. It provides two operating modes:
|
||||
|
||||
* pymilvus-compatible mode: Operates the database using the MilvusLikeClient object, offering commonly used APIs compatible with the lightweight MilvusClient.
|
||||
|
||||
* SQLAlchemy extension mode: Operates the database using the ObVecClient object, serving as an extension of Python's SDK for relational databases.
|
||||
|
||||
This topic describes the APIs in the two modes and provides examples.
|
||||
|
||||
## MilvusLikeClient
|
||||
|
||||
### Constructor
|
||||
|
||||
```python
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
uri: str = "127.0.0.1:2881",
|
||||
user: str = "root@test",
|
||||
password: str = "",
|
||||
db_name: str = "test",
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
### collection-related APIs
|
||||
|
||||
| API | Description | Example |
|
||||
|------|------|------|
|
||||
| `def create_schema(self, **kwargs) -> CollectionSchema:` | <ul>Creates a `CollectionSchema` object.<li>Parameters are optional, allowing the initialization of an empty schema definition.</li><li>Optional parameters include:</li><ul><li>`fields`: A list of `FieldSchema` objects (see the `add_field` interface below for details).</li><li>`partitions`: Partitioning rules (see the section on defining partition rules using `ObPartition`).</li><li>`description`: Compatible with Milvus, but currently has no practical effect in seekdb.</li></ul></ul> | |
|
||||
| `def create_collection(<br/>self,<br/>collection_name: str,<br/>dimension: Optional[int] = None,<br/>primary_field_name: str = "id",<br/>id_type: Union[DataType, str] = DataType.INT64,<br/>vector_field_name: str = "vector",<br/>metric_type: str = "l2",<br/>auto_id: bool = False,<br/>timeout: Optional[float] = None,<br/>schema: Optional[CollectionSchema] = None, # Used for custom setup<br/>index_params: Optional[IndexParams] = None, # Used for custom setup<br/>max_length: int = 16384,<br/>**kwargs,<br/>)` | Creates a table: <ul><li>collection_name: the table name</li><li>dimension: the vector data dimension</li><li>primary_field_name: the primary field name</li><li>id_type: the primary field data type (only supports VARCHAR and INT types)</li><li>vector_field_name: the vector field name</li><li>metric_type: not used in seekdb, but maintained for API compatibility (because the main table definition does not need to specify a vector distance function)</li><li>auto_id: specifies whether the primary field value increases automatically</li><li>timeout: not used in seekdb, but maintained for API compatibility</li><li>schema: the custom collection schema. When `schema` is not None, the parameters from dimension to metric_type will be ignored</li><li>index_params: the custom vector index parameters</li><li>max_length: the maximum varchar length when the primary field data type is VARCHAR and `schema` is not None</li></ul> | `client.create_collection(<br/>collection_name=test_collection_name,<br/>schema=schema,<br/>index_params=idx_params,<br/>)` |
|
||||
| `def get_collection_stats(<br/>self, collection_name: str, timeout: Optional[float] = None # pylint: disable=unused-argument<br/>) -> Dict:` | Queries the record count of a table.<ul><li>collection_name: the table name</li><li>timeout: not used in seekdb, but maintained for API compatibility</li></ul> | |
|
||||
| `def has_collection(self, collection_name: str, timeout: Optional[float] = None) -> bool` | Verifies whether a table exists.<ul><li>collection_name: the table name</li><li>timeout: not used in seekdb, but maintained for API compatibility</li></ul> | |
|
||||
| `def drop_collection(self, collection_name: str) -> None` | Drops a table.<ul><li>collection_name: the table name</li></ul> | |
|
||||
| `def load_table(self, collection_name: str,)` | Reads the metadata of a table to the SQLAlchemy metadata cache.<ul><li>collection_name: the table name</li></ul> | |
|
||||
|
||||
### CollectionSchema & FieldSchema
|
||||
|
||||
MilvusLikeClient describes the schema of a table by using a CollectionSchema. A CollectionSchema contains multiple FieldSchemas, and a FieldSchema describes the column schema of a table.
|
||||
|
||||
#### Create a CollectionSchema by using the create_schema method of the MilvusLikeClient
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
fields: Optional[List[FieldSchema]] = None,
|
||||
partitions: Optional[ObPartition] = None,
|
||||
description: str = "", # ignored in oceanbase
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* fields: an optional parameter that specifies a list of FieldSchema objects.
|
||||
|
||||
* partitions: partition rules (for more information, see the ObPartition section).
|
||||
|
||||
* description: compatible with Milvus, but currently has no practical effect in seekdb.
|
||||
|
||||
#### Create a FieldSchema and register it to a CollectionSchema
|
||||
|
||||
```python
|
||||
def add_field(self, field_name: str, datatype: DataType, **kwargs)
|
||||
```
|
||||
|
||||
* field_name: the column name.
|
||||
|
||||
* datatype: the column data type. For supported data types, see [Compatibility reference](../800.vector-sdk-refer.md).
|
||||
|
||||
* kwargs: additional parameters for configuring column properties, as shown below:
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
name: str,
|
||||
dtype: DataType,
|
||||
description: str = "",
|
||||
is_primary: bool = False,
|
||||
auto_id: bool = False,
|
||||
nullable: bool = False,
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
The parameters are described as follows:
|
||||
|
||||
* is_primary: specifies whether the column is a primary key.
|
||||
|
||||
* auto_id: specifies whether the column value increases automatically.
|
||||
|
||||
* nullable: specifies whether the column can be null.
|
||||
|
||||
#### Example
|
||||
|
||||
```python
|
||||
schema = self.client.create_schema()
|
||||
schema.add_field(field_name="id", datatype=DataType.INT64, is_primary=True)
|
||||
schema.add_field(field_name="title", datatype=DataType.VARCHAR, max_length=512)
|
||||
schema.add_field(
|
||||
field_name="title_vector", datatype=DataType.FLOAT_VECTOR, dim=768
|
||||
)
|
||||
schema.add_field(field_name="link", datatype=DataType.VARCHAR, max_length=512)
|
||||
schema.add_field(field_name="reading_time", datatype=DataType.INT64)
|
||||
schema.add_field(
|
||||
field_name="publication", datatype=DataType.VARCHAR, max_length=512
|
||||
)
|
||||
schema.add_field(field_name="claps", datatype=DataType.INT64)
|
||||
schema.add_field(field_name="responses", datatype=DataType.INT64)
|
||||
|
||||
self.client.create_collection(
|
||||
collection_name="medium_articles_2020", schema=schema
|
||||
)
|
||||
```
|
||||
|
||||
### Index-related APIs
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def create_index(<br/>self,<br/>collection_name: str,<br/>index_params: IndexParams,<br/>timeout: Optional[float] = None,<br/>**kwargs,<br/>)` | Creates a vector index table based on the constructed IndexParams (for more information about how to use IndexParams, see the prepare_index_params and add_index APIs).<ul><li>collection_name: the table name</li><li>index_params: the index parameters</li><li>timeout: not used in seekdb, but maintained for API compatibility</li><li>kwargs: other parameters, currently not used, maintained for compatibility</li></ul> | |
|
||||
| `def drop_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>timeout: Optional[float] = None,<br/>**kwargs,<br/>)` | Drops an index table.<ul><li>collection_name: the table name</li><li>index_name: the index name</li></ul> | |
|
||||
| `def refresh_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>trigger_threshold: int = 10000,<br/>)` | Refreshes a vector index table to improve read performance. It can be understood as a process of moving incremental data.<ul><li>collection_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the refresh action. A refresh is triggered when the data volume of the index table exceeds the threshold.</li></ul> | An API introduced
|
||||
| `def rebuild_index(<br/>self,<br/>collection_name: str,<br/>index_name: str,<br/>trigger_threshold: float = 0.2,<br/>)` | Rebuilds a vector index table to improve read performance. It can be understood as a process of merging incremental data into baseline index data.<ul><li>collection_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the rebuild action. The value range is 0 to 1. A rebuild is triggered when the proportion of incremental data to full data reaches the threshold.</li></ul> | An API introduced by seekdb.<br/>Not compatible with Milvus. |
|
||||
| `def search(<br/>self,<br/>collection_name: str,<br/>data: list,<br/>anns_field: str,<br/>with_dist: bool = False,<br/>filter=None,limit: int = 10,output_fields: Optional[List[str]] = None,<br/>search_params: Optional[dict] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Executes a vector approximate nearest neighbor search.<ul><li>collection_name: the table name</li><li>data: the vector data to be searched</li><li>anns_field: the name of the vector column to be searched</li><li>with_dist: specifies whether to return results with vector distances</li><li>filter: uses vector approximate nearest neighbor search with filter conditions</li><li>limit: top K</li><li>output_fields: the output columns (also known as projection columns)</li><li>search_params: supports only the `metric_type` value of `l2`/`neg_ip` (`for example: search_params = {"metric_type": "neg_ip"}`)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul><ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values.</ul> | `res = self.client.search(<br/>collection_name=test_collection_name,<br/>data=[0, 0, 1],<br/>anns_field="embedding",<br/>limit=5,<br/>output_fields=["id"],<br/>search_params={"metric_type": "neg_ip"}<br/>)<br/>self.assertEqual(<br/> set([r['id'] for r in res]), set([12, 111, 11, 112, 10]))` |
|
||||
| `def query(<br/>self,<br/>collection_name: str,<br/>flter=None,<br/>output_fields: Optional[List[str]] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Reads data records using the specified filter condition.<ul><li>collection_name: the table name</li><li>flter: uses vector approximate nearest neighbor search with filter conditions</li><li>output_fields: the output columns (also known as projection columns)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul><ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values.</ul> | `table = self.client.load_table(collection_name=test_collection_name)<br/>where_clause = [table.c["id"] < 100]<br/>res = self.client.query(<br/> collection_name=test_collection_name,<br/> output_fields=["id"],<br/> flter=where_clause,<br/>)` |
|
||||
| `def get(<br/>self,<br/>collection_name: str,<br/>ids: Union[list, str, int],<br/>output_fields: Optional[List[str]] = None,<br/>timeout: Optional[float] = None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>) -> List[dict]` | Retrieves records based on the specified primary keys `ids`:<ul><li>collection_name: the table name</li><li>ids: a single ID or a list of IDs. Note: The ids parameter of MilvusLikeClient get interface is different from ObVecClient get. For details, see <a href="#DML%20operations">ObVecClient get</a></li><li>output_fields: the output columns (also known as projection columns)</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_names: limits the query to some partitions</li></ul>Return value:<br/>A list of records, where each record is a dictionary<br/>representing a mapping from column_name to column values. | `res = self.client.get(<br/> collection_name=test_collection_name,<br/> output_fields=["id", "meta"],<br/> ids=[80, 12, 112],<br/>)` |
|
||||
| `def delete(<br/>self,<br/>collection_name: str,<br/>ids: Optional[Union[list, str, int]] = None,<br/>timeout: Optional[float] = None, # pylint: disable=unused-argument<br/>flter=None,<br/>partition_name: Optional[str] = "",<br/>**kwargs, # pylint: disable=unused-argument<br/>)` | Deletes data in a collection.<ul><li>collection_name: the table name</li><li>ids: a single ID or a list of IDs</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>flter: uses vector approximate nearest neighbor search with filter conditions</li><li>partition_name: limits the deletion operation to a partition</li></ul> | `self.client.delete(<br/> collection_name=test_collection_name, ids=[12, 112], partition_name="p0"<br/>)` |
|
||||
| `def insert(<br/> self, <br/> collection_name: str, <br/> data: Union[Dict, List[Dict]], <br/> timeout: Optional[float] = None, <br/> partition_name: Optional[str] = ""<br/>)` | Inserts data into a table.<ul><li>collection_name: the table name</li><li>data: the data to be inserted, described in Key-Value form</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_name: limits the insertion operation to a partition</li></ul> | `data = [<br/> {"id": 12, "embedding": [1, 2, 3], "meta": {"doc": "document 1"}},<br/> {<br/> "id": 90,<br/> "embedding": [0.13, 0.123, 1.213],<br/> "meta": {"doc": "document 1"},<br/> },<br/> {"id": 112, "embedding": [1, 2, 3], "meta": None},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": None},<br/>]<br/>self.client.insert(collection_name=test_collection_name, data=data)` |
|
||||
| `def upsert(<br/>self,<br/>collection_name: str,<br/>data: Union[Dict, List[Dict]],<br/>timeout: Optional[float] = None, # pylint: disable=unused-argument<br/>partition_name: Optional[str] = "",<br/>) -> List[Union[str, int]]` | Updates data in a table. If a primary key already exists, updates the corresponding record; otherwise, inserts a new record.<ul><li>collection_name: the table name</li><li>data: the data to be inserted or updated, in the same format as the insert interface</li><li>timeout: not used in seekdb, maintained for compatibility only</li><li>partition_name: limits the operation to a specified partition</li></ul> | `data = [<br/> {"id": 112, "embedding": [1, 2, 3], "meta": {'doc':'hhh1'}},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": {'doc':'hhh2'}},<br/>]<br/>self.client.upsert(collection_name=test_collection_name, data=data)` |
|
||||
| `def perform_raw_text_sql(self, text_sql: str):<br/> return super().perform_raw_text_sql(text_sql)` | Executes an SQL statement directly.<ul><li>text_sql: the SQL statement to be executed</li></ul>Return value:<br/>Returns an iterator that provides result sets from SQLAlchemy. | |
|
||||
|
||||
## ObVecClient
|
||||
|
||||
### Constructor
|
||||
|
||||
```python
|
||||
def __init__(
|
||||
self,
|
||||
uri: str = "127.0.0.1:2881",
|
||||
user: str = "root@test",
|
||||
password: str = "",
|
||||
db_name: str = "test",
|
||||
**kwargs,
|
||||
)
|
||||
```
|
||||
|
||||
### Table mode-related operations
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def check_table_exists(self, table_name: str)` | Checks whether a table exists.<ul><li>table_name: the table name</li></ul> | |
|
||||
| `def create_table(<br/>self,<br/>table_name: str,<br/>columns: List[Column],<br/>indexes: Optional[List[Index]] = None,<br/>partitions: Optional[ObPartition] = None,<br/>)` | Creates a table.<ul><li>table_name: the table name</li><li>columns: the column schema of the table, defined using SQLAlchemy</li><li>indexes: a set of index schemas, defined using SQLAlchemy</li><li>partitions: optional partition rules (see the section on using ObPartition to define partition rules)</li></ul> | |
|
||||
| `@classmethod<br/>def prepare_index_params(cls)` | Creates an IndexParams object to record the schema definition of a vector index table.`class IndexParams:<br/> """Vector index parameters for MilvusLikeClient"<br/> def __init__(self):<br/> self._indexes = {}`<br/>The definition of IndexParams is very simple, with only one dictionary member internally<br/>that stores a mapping from a tuple of (column name, index name) to an IndexParam structure.<br/>The constructor of the IndexParam class is:`def __init__(<br/> self,<br/> index_name: str,<br/> field_name: str,<br/> index_type: Union[VecIndexType, str],<br/> **kwargs<br/>)`<ul><li>index_name: the vector index table name</li><li>field_name: the vector column name</li><li>index_type: an enumerated class for vector index algorithm types. Currently, only HNSW is supported.</li></ul>After obtaining an IndexParams by calling `prepare_index_params`, you can register an IndexParam using the `add_index` interface:`def add_index(<br/> self,<br/> field_name: str,<br/> index_type: VecIndexType,<br/> index_name: str,<br/> **kwargs<br/>)`The parameter meanings are the same as those in the IndexParam constructor. | Here is a usage example for creating a vector index: `idx_params = self.client.prepare_index_params()<br/>idx_params.add_index(<br/> field_name="title_vector",<br/> index_type="HNSW",<br/> index_name="vidx_title_vector",<br/> metric_type="L2",<br/> params={"M": 16, "efConstruction": 256},<br/>)<br/>self.client.create_collection(<br/> collection_name=test_collection_name,<br/> schema=schema,<br/> <br/>index_params=idx_params,<br/>)`Note that the `prepare_index_params` function is recommended for use in MilvusLikeClient, not in ObVecClient. In ObVecClient mode, you should use the `create_index` interface to define a vector index table. (For details, see the create_index interface.) |
|
||||
| `def create_table_with_index_params(<br/>self,<br/>table_name: str,<br/>columns: List[Column],<br/>indexes: Optional[List[Index]] = None,<br/>vidxs: Optional[IndexParams] = None,<br/>partitions: Optional[ObPartition] = None,<br/>) | Creates a table and a vector index at the same time using optional index_params.<ul><li>table_name: the table name</li><li>columns: the column schema of the table, defined using SQLAlchemy</li><li>indexes: a set of index schemas, defined using SQLAlchemy</li><li>vidxs: the vector index schema, specified using IndexParams</li><li>partitions: optional partition rules (see the section on using ObPartition to define partition rules)</li></ul> | Recommended for use in MilvusLikeClient, not recommended for use in ObVecClient |
|
||||
| `def create_index(<br/>self,<br/>table_name: str,<br/>is_vec_index: bool,<br/>index_name: str,<br/>column_names: List[str],<br/>vidx_params: Optional[str] = None,<br/>**kw,<br/>)` | Supports creating both normal indexes and vector indexes.<ul><li>table_name: the table name</li><li>is_vec_index: specifies whether to create a normal index or a vector index</li><li>index_name: the index name</li><li>column_names: the columns on which to create the index</li><li>vidx_params: the vector index parameters, for example: `"distance=l2, type=hnsw, lib=vsag"`</li></ul>Currently, seekdb supports only `type=hnsw` and `lib=vsag`. Please retain these settings. The distance can be set to `l2` or `inner_product`. | `self.client.create_index(<br/> test_collection_name,<br/> is_vec_index=True,<br/> index_name="vidx",<br/> column_names=["embedding"],<br/> vidx_params="distance=l2, type=hnsw, lib=vsag",<br/>) |
|
||||
| `def create_vidx_with_vec_index_param(<br/>self,<br/>table_name: str,<br/>vidx_param: IndexParam,<br/>)` | Creates a vector index using vector index parameters.<ul><li>table_name: the table name</li><li>vidx_param: the vector index parameters constructed using IndexParam</li></ul> | |
|
||||
| `def drop_table_if_exist(self, table_name: str)` | Drops a table.<ul><li>table_name: the table name</li></ul> | |
|
||||
| `def drop_index(self, table_name: str, index_name: str)` | Drops an index.<ul><li>table_name: the table name</li><li>index_name: the index name</li></ul> | |
|
||||
| `def refresh_index(<br/>self,<br/>table_name: str,<br/>index_name: str,<br/>trigger_threshold: int = 10000,<br/>)` | Refreshes a vector index table to improve read performance. It can be understood as a process of moving incremental data.<ul><li>table_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the refresh action. A refresh is triggered when the data volume of the index table exceeds the threshold.</li></ul> | |
|
||||
| `def rebuild_index(<br/>self,<br/>table_name: str,<br/>index_name: str,<br/>trigger_threshold: float = 0.2,<br/>)` | Rebuilds a vector index table to improve read performance. It can be understood as a process of merging incremental data into baseline index data.<ul><li>table_name: the table name</li><li>index_name: the index name</li><li>trigger_threshold: the trigger threshold of the rebuild action. The value range is 0 to 1. A rebuild is triggered when the proportion of incremental data to full data reaches the threshold.</li></ul> | |
|
||||
|
||||
### DML operations
|
||||
|
||||
| API | Description | Example/Remarks |
|
||||
|-----|-----|-----|
|
||||
| `def insert(<br/>self,<br/>table_name: str,<br/>data: Union[Dict, List[Dict]],<br/>partition_name: Optional[str] = "",<br/>)` | Inserts data into a table.<ul><li>table_name: the table name</li><li>data: the data to be inserted, described in Key-Value form</li><li>partition_name: limits the insertion operation to a partition</li></ul> | `vector_value1 = [0.748479, 0.276979, 0.555195]<br/>vector_value2 = [0, 0, 0]<br/>data1 = [{"id": i, "embedding": vector_value1} for i in range(10)]<br/>data1.extend([{"id": i, "embedding": vector_value2} for i in range(10, 13)])<br/>data1.extend([{"id": i, "embedding": vector_value2} for i in range(111, 113)])<br/>self.client.insert(test_collection_name, data=data1)` |
|
||||
| `def upsert(<br/>self,<br/>table_name: str,<br/>data: Union[Dict, List[Dict]],<br/>partition_name: Optional[str] = "",<br/>)` | Inserts or updates data in a table. If a primary key already exists, updates the corresponding record; otherwise, inserts a new record.<ul><li>table_name: the table name</li><li>data: the data to be inserted or updated, in Key-Value format</li><li>partition_name: limits the operation to a specified partition</li></ul> | |
|
||||
| `def update(<br/>self,<br/>table_name: str,<br/>values_clause,<br/>where_clause=None,<br/>partition_name: Optional[str] = "",<br/>)` | Updates data in a table. If a primary key is repeated, it will be replaced.<ul><li>table_name: the table name</li><li>values_clause: the values of the columns to be updated</li><li>where_clause: the condition for updating</li><li>partition_name: limits the update operation to some partitions</li></ul> | `data = [<br/> {"id": 112, "embedding": [1, 2, 3], "meta": {'doc':'hhh1'}},<br/> {"id": 190, "embedding": [0.13, 0.123, 1.213], "meta": {'doc':'hhh2'}},<br/>]<br/>client.insert(collection_name=test_collection_name, data=data)<br/>client.update(<br/> table_name=test_collection_name,<br/> values_clause=[{'meta':{'doc':'HHH'}}],<br/> where_clause=[text("id=112")]<br/>)` |
|
||||
| `def delete(<br/>self,<br/>table_name: str,<br/>ids: Optional[Union[list, str, int]] = None,<br/>where_clause=None,<br/>partition_name: Optional[str] = "",<br/>)` | Deletes data from a table.<ul><li>table_name: the table name</li><li>ids: a single ID or a list of IDs</li><li>where_clause: the condition for deletion</li><li>partition_name: limits the deletion operation to some partitions</li></ul> | `self.client.delete(test_collection_name, ids=["bcd", "def"])` |
|
||||
| `def get(<br/>self,<br/>table_name: str,<br/>ids: Optional[Union[list, str, int]],<br/>where_clause = None,<br/>output_column_name: Optional[List[str]] = None,<br/>partition_names: Optional[List[str]] = None,<br/>)` | Retrieves records based on the specified primary keys `ids`.<ul><li>table_name: the table name</li><li>ids: a single ID or a list of IDs. Optional parameter, can be `ids=None` if not provided. The ids parameter of ObVecClient get interface is different from MilvusLikeClient get. For details, see <a href="#Index-related%20APIs">MilvusLikeClient get</a></li><li>where_clause: the condition for retrieval</li><li>output_column_name: a list of output column or projection column names</li><li>partition_names: limits the retrieval operation to some partitions</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | `res = self.client.get(<br/> test_collection_name,<br/> ids=["abc", "bcd", "cde", "def"],<br/> where_clause=[text("meta->'$.page' > 1")],<br/> output_column_name=['id']<br/>) |
|
||||
| `def set_ob_hnsw_ef_search(self, ob_hnsw_ef_search: int)` | Set the efSearch parameter of the HNSW index. This is a session-level variable. The larger the value of ef_search, the higher the recall rate but the poorer the query performance. <ul><li>ob_hnsw_ef_search: the efSearch parameter of the HNSW index</li></ul> | |
|
||||
| `def get_ob_hnsw_ef_search(self) -> int` | Get the efSearch parameter of the HNSW index. | |
|
||||
| `def ann_search(<br/>self,<br/>table_name: str,<br/>vec_data: list,<br/>vec_column_name: str,<br/>distance_func,<br/>with_dist: bool = False,<br/>topk: int = 10,<br/>output_column_names: Optional[List[str]] = None,<br/>extra_output_cols: Optional[List] = None,<br/>where_clause=None,<br/>partition_names: Optional[List[str]] = None,<br/>**kwargs,<br/>)` | Executes a vector approximate nearest neighbor search.<ul><li>table_name: the table name</li><li>vec_data: the vector data to be searched</li><li>vec_column_name: the name of the vector column to be searched</li><li>distance_func: the distance function. Provides an extension of SQLAlchemy func, with optional values: `func.l2_distance`/`func.cosine_distance`/`func.inner_product`/`func.negative_inner_product`, representing the l2 distance function, cosine distance function, inner product distance function, and negative inner product distance function, respectively</li><li>with_dist: specifies whether to return results with vector distances</li><li>topk: the number of nearest vectors to retrieve</li><li>output_column_names: a list of output column or projection column names</li><li>extra_output_cols: additional output columns that allow more complex output expressions</li><li>where_clause: the filter condition</li><li>partition_names: limits the query to some partitions</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | `res = self.client.ann_search(<br/> test_collection_name,<br/> vec_data=[0, 0, 0],<br/> vec_column_name="embedding",<br/> distance_func=func.l2_distance,<br/> with_dist=True,<br/> topk=5,<br/> output_column_names=["id"],<br/>) |
|
||||
| `def precise_search(<br/>self,<br/>table_name: str,<br/>vec_data: list,<br/>vec_column_name: str,<br/>distance_func,<br/>topk: int = 10,<br/>output_column_names: Optional[List[str]] = None,<br/>where_clause=None,<br/>**kwargs,<br/>) | Executes a precise neighbor search algorithm.<ul><li>table_name: the table name</li><li>vec_data: the query vector</li><li>vec_column_name: the vector column name</li><li>distance_func: the vector distance function. Provides an extension of SQLAlchemy func, with optional values: func.l2_distance/func.cosine_distance/func.inner_product/func.negative_inner_product, representing the l2 distance function, cosine distance function, inner product distance function, and negative inner product distance function, respectively</li><li>topk: the number of nearest vectors to retrieve</li><li>output_column_names: a list of output column or projection column names</li><li>where_clause: the filter condition</li></ul>Return value:<br/>Unlike MilvusLikeClient, the return value of ObVecClient is a tuple list, with each tuple representing a row of records. | |
|
||||
| `def perform_raw_text_sql(self, text_sql: str)` | Executes an SQL statement directly.<ul><li>text_sql: the SQL statement to be executed</li></ul>Return value:<br/>Returns an iterator that provides result sets from SQLAlchemy. | |
|
||||
|
||||
## Define partitioning rules by using ObPartition
|
||||
|
||||
pyobvector supports the following types for range/range columns, list/list columns, hash, key, and subpartitioning:
|
||||
|
||||
* ObRangePartition: specifies to perform range partitioning. Set `is_range_columns` to `True` when you construct this object to create range column partitioning.
|
||||
|
||||
* ObListPartition: specifies to perform list partitioning. Set `is_list_columns` to `True` when you construct this object to create list column partitioning.
|
||||
|
||||
* ObHashPartition: specifies to perform hash partitioning.
|
||||
|
||||
* ObKeyPartition: specifies to perform key partitioning.
|
||||
|
||||
* ObSubRangePartition: specifies to perform sub-range partitioning. Set `is_range_columns` to `True` when you construct this object to create sub-range column partitioning.
|
||||
|
||||
* ObSubListPartition: specifies to perform sub-list partitioning. Set `is_list_columns` to `True` when you construct this object to create sub-list column partitioning.
|
||||
|
||||
* ObSubHashPartition: specifies to perform sub-hash partitioning.
|
||||
|
||||
* ObSubKeyPartition: specifies to perform sub-key partitioning.
|
||||
|
||||
### Example of range partitioning
|
||||
|
||||
```python
|
||||
range_part = ObRangePartition(
|
||||
False,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("p0", 100),
|
||||
RangeListPartInfo("p1", "maxvalue"),
|
||||
],
|
||||
range_expr="id",
|
||||
)
|
||||
```
|
||||
|
||||
### Example of list partitioning
|
||||
|
||||
```python
|
||||
list_part = ObListPartition(
|
||||
False,
|
||||
list_part_infos=[
|
||||
RangeListPartInfo("p0", [1, 2, 3]),
|
||||
RangeListPartInfo("p1", [5, 6]),
|
||||
RangeListPartInfo("p2", "DEFAULT"),
|
||||
],
|
||||
list_expr="col1",
|
||||
)
|
||||
```
|
||||
|
||||
### Example of hash partitioning
|
||||
|
||||
```python
|
||||
hash_part = ObHashPartition("col1", part_count=60)
|
||||
```
|
||||
|
||||
### Example of multi-level partitioning
|
||||
|
||||
```python
|
||||
# Perform range partitioning
|
||||
range_columns_part = ObRangePartition(
|
||||
True,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("p0", 100),
|
||||
RangeListPartInfo("p1", 200),
|
||||
RangeListPartInfo("p2", 300),
|
||||
],
|
||||
col_name_list=["col1"],
|
||||
)
|
||||
# Perform sub-range partitioning
|
||||
range_sub_part = ObSubRangePartition(
|
||||
False,
|
||||
range_part_infos=[
|
||||
RangeListPartInfo("mp0", 1000),
|
||||
RangeListPartInfo("mp1", 2000),
|
||||
RangeListPartInfo("mp2", 3000),
|
||||
],
|
||||
range_expr="col3",
|
||||
)
|
||||
range_columns_part.add_subpartition(range_sub_part)
|
||||
```
|
||||
|
||||
## Pure SQLAlchemy API mode
|
||||
|
||||
If you prefer to use a purely SQLAlchemy API for seekdb's vector retrieval functionality, you can obtain a synchronized database engine through the following methods:
|
||||
|
||||
* Method 1: Use ObVecClient to create a database engine
|
||||
|
||||
```python
|
||||
from pyobvector import ObVecClient
|
||||
|
||||
client = ObVecClient(uri="127.0.0.1:2881", user="test@test")
|
||||
engine = client.engine
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
* Method 2: Call the `create_engine` interface of ObVecClient to create a database engine
|
||||
|
||||
```python
|
||||
import pyobvector
|
||||
from sqlalchemy.dialects import registry
|
||||
from sqlalchemy import create_engine
|
||||
|
||||
uri: str = "127.0.0.1:2881"
|
||||
user: str = "root@test"
|
||||
password: str = ""
|
||||
db_name: str = "test"
|
||||
registry.register("mysql.oceanbase", "pyobvector.schema.dialect", "OceanBaseDialect")
|
||||
connection_str = (
|
||||
# mysql+oceanbase indicates using the MySQL standard with seekdb's synchronous driver.
|
||||
f"mysql+oceanbase://{user}:{password}@{uri}/{db_name}?charset=utf8mb4"
|
||||
)
|
||||
engine = create_engine(connection_str, **kwargs)
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
If you want to use asynchronous APIs of SQLAlchemy, you can use seekdb's asynchronous driver:
|
||||
|
||||
```python
|
||||
import pyobvector
|
||||
from sqlalchemy.dialects import registry
|
||||
from sqlalchemy.ext.asyncio import create_async_engine
|
||||
|
||||
uri: str = "127.0.0.1:2881"
|
||||
user: str = "root@test"
|
||||
password: str = ""
|
||||
db_name: str = "test"
|
||||
registry.register("mysql.aoceanbase", "pyobvector", "AsyncOceanBaseDialect")
|
||||
connection_str = (
|
||||
# mysql+aoceanbase indicates using the MySQL standard with seekdb's asynchronous driver.
|
||||
f"mysql+aoceanbase://{user}:{password}@{uri}/{db_name}?charset=utf8mb4"
|
||||
)
|
||||
engine = create_async_engine(connection_str)
|
||||
# Proceed to create a session as usual with SQLAlchemy and use its API.
|
||||
```
|
||||
|
||||
## More examples
|
||||
|
||||
For more examples, visit the [pyobvector repository](https://github.com/oceanbase/pyobvector).
|
||||
@@ -0,0 +1,470 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-java-sdk
|
||||
---
|
||||
|
||||
# Java SDK API reference
|
||||
|
||||
obvec_jdbc is a Java SDK specifically designed for seekdb vector storage scenarios and JSON Table virtual table scenarios. This topic explains how to use obvec_jdbc.
|
||||
|
||||
## Installation
|
||||
|
||||
You can install obvec_jdbc using either of the following methods.
|
||||
|
||||
### Maven dependency
|
||||
|
||||
Add the obvec_jdbc dependency to the `pom.xml` file of your project.
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.oceanbase</groupId>
|
||||
<artifactId>obvec_jdbc</artifactId>
|
||||
<version>1.0.4</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
### Source code installation
|
||||
|
||||
1. Install obvec_jdbc.
|
||||
|
||||
```bash
|
||||
# Clone the obvec_jdbc repository.
|
||||
git clone https://github.com/oceanbase/obvec_jdbc.git
|
||||
# Go to the obvec_jdbc directory.
|
||||
cd obvec_jdbc
|
||||
# Install obvec_jdbc.
|
||||
mvn install
|
||||
```
|
||||
|
||||
2. Add the dependency.
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>com.oceanbase</groupId>
|
||||
<artifactId>obvec_jdbc</artifactId>
|
||||
<version>1.0.4</version>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
## API definition and usage
|
||||
|
||||
obvec_jdbc provides the `ObVecClient` object for working with seekdb's vector search features and JSON Table virtual table functionalities.
|
||||
|
||||
### Use vector search
|
||||
|
||||
#### Create a client
|
||||
|
||||
You can use the following interface definition to construct an ObVecClient object:
|
||||
|
||||
```java
|
||||
# uri: the connection string, which contains the address, port, and name of the database to which you want to connect.
|
||||
# user: the username.
|
||||
# password: the password.
|
||||
public ObVecClient(String uri, String user, String password);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.ObVecClient;
|
||||
|
||||
String uri = "jdbc:oceanbase://127.0.0.1:2881/test";
|
||||
String user = "root@test";
|
||||
String password = "";
|
||||
String tb_name = "JAVA_TEST";
|
||||
|
||||
ObVecClient ob = new ObVecClient(uri, user, password);
|
||||
```
|
||||
|
||||
#### ObFieldSchema class
|
||||
|
||||
This class is used to define the column schema of a table. The constructor is as follows:
|
||||
|
||||
```java
|
||||
# name: the column name.
|
||||
# dataType: the data type.
|
||||
public ObFieldSchema(String name, DataType dataType);
|
||||
```
|
||||
|
||||
The following table describes the data types supported by the class.
|
||||
|
||||
| Data type | Description |
|
||||
|---|---|
|
||||
| BOOL | Equivalent to TINYINT |
|
||||
| INT8 | Equivalent to TINYINT |
|
||||
| INT16 | Equivalent to SMALLINT |
|
||||
| INT32 | Equivalent to INT |
|
||||
| INT64 | Equivalent to BIGINT |
|
||||
| FLOAT | Equivalent to FLOAT |
|
||||
| DOUBLE | Equivalent to DOUBLE |
|
||||
| STRING | Equivalent to LONGTEXT |
|
||||
| VARCHAR | Equivalent to VARCHAR |
|
||||
| JSON | Equivalent to JSON |
|
||||
| FLOAT_VECTOR | Equivalent to VECTOR |
|
||||
|
||||
:::tip
|
||||
For more complex types, constraints, and other functionalities, you can use seekdb JDBC's interface directly instead of using obvec_jdbc.
|
||||
:::
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| String getName() | Obtains the column name. |
|
||||
| ObFieldSchema Name(String name) | Sets the column name and returns the object itself to support chain operations. |
|
||||
| ObFieldSchema DataType(DataType dataType) | Sets the data type. |
|
||||
| boolean getIsPrimary() | Specifies whether the column is the primary key. |
|
||||
| ObFieldSchema IsPrimary(boolean isPrimary) | Specifies whether the column is the primary key. |
|
||||
| ObFieldSchema IsAutoInc(boolean isAutoInc) | Specifies whether the column is auto-increment. <main id="notice" type='notice'><h4>Notice</h4><p>IsAutoInc takes effect only if IsPrimary is true. </p></main> |
|
||||
| ObFieldSchema IsNullable(boolean isNullable) | Specifies whether the column can contain NULL values. <main id="notice" type='notice'><h4>Notice</h4><p>IsNullable is set to false by default, which is different from the behavior in MySQL. </p></main> |
|
||||
| ObFieldSchema MaxLength(int maxLength) | Sets the maximum length for the VARCHAR data type. |
|
||||
| ObFieldSchema Dim(int dim) | Sets the dimension for the VECTOR data type. |
|
||||
|
||||
#### IndexParams/IndexParam
|
||||
|
||||
IndexParam is used to set a single index parameter. IndexParams is used to set a group of vector index parameters, which is used when multiple vector indexes are created on a table.
|
||||
|
||||
:::tip
|
||||
obvec_jdbc supports only the creation of vector indexes. To create other indexes, use seekdb JDBC.
|
||||
:::
|
||||
|
||||
The constructor of IndexParam is as follows:
|
||||
|
||||
```java
|
||||
# vidx_name: the index name.
|
||||
# vector_field_name: the name of the vector column.
|
||||
public IndexParam(String vidx_name, String vector_field_name);
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| IndexParam M(int m) | Sets the maximum number of neighbors for each vector in the HNSW algorithm. |
|
||||
| IndexParam EfConstruction(int ef_construction) | Sets the maximum number of candidate vectors for search during the construction of the HNSW algorithm. |
|
||||
| IndexParam EfSearch(int ef_search) | Sets the maximum number of candidate vectors for search in the HNSW algorithm. |
|
||||
| IndexParam Lib(String lib) | Sets the type of the vector library. |
|
||||
| IndexParam MetricType(String metric_type) | Sets the type of the vector distance function. |
|
||||
|
||||
The constructor of IndexParams is as follows:
|
||||
|
||||
```
|
||||
public IndexParams();
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| void addIndex(IndexParam index_param) | Adds an index definition. |
|
||||
|
||||
#### ObCollectionSchema class
|
||||
|
||||
When creating a table, you need to rely on the configuration of the ObCollectionSchema object. Below are its constructors and interfaces.
|
||||
|
||||
The constructor of ObCollectionSchema is as follows:
|
||||
|
||||
```java
|
||||
public ObCollectionSchema();
|
||||
```
|
||||
|
||||
The interface is defined as follows:
|
||||
|
||||
| API | Description |
|
||||
|---|---|
|
||||
| void addField(ObFieldSchema field) | Adds a column definition. |
|
||||
| void setIndexParams(IndexParams index_params) | Sets the vector index parameters of the table. |
|
||||
|
||||
#### Drop a table
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
public void dropCollection(String table_name);
|
||||
```
|
||||
|
||||
#### Check whether a table exists
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
public boolean hasCollection(String table_name);
|
||||
```
|
||||
|
||||
#### Create a table
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the table to be created.
|
||||
# collection: an ObCollectionSchema object that specifies the schema of the table.
|
||||
public void createCollection(String table_name, ObCollectionSchema collection);
|
||||
```
|
||||
|
||||
You can use ObFieldSchema, ObCollectionSchema, and IndexParams to create a table. Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.DataType;
|
||||
import com.oceanbase.obvec_jdbc.ObCollectionSchema;
|
||||
import com.oceanbase.obvec_jdbc.ObFieldSchema;
|
||||
import com.oceanbase.obvec_jdbc.IndexParam;
|
||||
import com.oceanbase.obvec_jdbc.IndexParams;
|
||||
|
||||
# Define the schema of the table.
|
||||
ObCollectionSchema collectionSchema = new ObCollectionSchema();
|
||||
ObFieldSchema c1_field = new ObFieldSchema("c1", DataType.INT32);
|
||||
c1_field.IsPrimary(true).IsAutoInc(true);
|
||||
ObFieldSchema c2_field = new ObFieldSchema("c2", DataType.FLOAT_VECTOR);
|
||||
c2_field.Dim(3).IsNullable(false);
|
||||
ObFieldSchema c3_field = new ObFieldSchema("c3", DataType.JSON);
|
||||
c3_field.IsNullable(true);
|
||||
collectionSchema.addField(c1_field);
|
||||
collectionSchema.addField(c2_field);
|
||||
collectionSchema.addField(c3_field);
|
||||
|
||||
# Define the index.
|
||||
IndexParams index_params = new IndexParams();
|
||||
IndexParam index_param = new IndexParam("vidx1", "c2");
|
||||
index_params.addIndex(index_param);
|
||||
collectionSchema.setIndexParams(index_params);
|
||||
|
||||
ob.createCollection(tb_name, collectionSchema);
|
||||
```
|
||||
|
||||
#### Create a vector index after table creation
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the table.
|
||||
# index_param: an IndexParam object that specifies the vector index parameters of the table.
|
||||
public void createIndex(String table_name, IndexParam index_param)
|
||||
```
|
||||
|
||||
#### Insert data
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# column_names: an array of column names in the target table.
|
||||
# rows: the data rows. ArrayList<Sqlizable[]>, each row is an Sqlizable array. Sqlizable is a wrapper class that converts Java data types to SQL data types.
|
||||
public void insert(String table_name, String[] column_names, ArrayList<Sqlizable[]> rows);
|
||||
```
|
||||
|
||||
The supported data types for rows include:
|
||||
|
||||
* SqlInteger: wraps integer data.
|
||||
* SqlFloat: wraps floating-point data.
|
||||
* SqlDouble: wraps double-precision data.
|
||||
* SqlText: wraps string data.
|
||||
* SqlVector: wraps vector data.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.SqlInteger;
|
||||
import com.oceanbase.obvec_jdbc.SqlText;
|
||||
import com.oceanbase.obvec_jdbc.SqlVector;
|
||||
import com.oceanbase.obvec_jdbc.Sqlizable;
|
||||
|
||||
ArrayList<Sqlizable[]> insert_rows = new ArrayList<>();
|
||||
Sqlizable[] ir1 = { new SqlVector(new float[] {1.0f, 2.0f, 3.0f}), new SqlText("{\"doc\": \"oceanbase doc 1\"}") };
|
||||
insert_rows.add(ir1);
|
||||
Sqlizable[] ir2 = { new SqlVector(new float[] {1.1f, 2.2f, 3.3f}), new SqlText("{\"doc\": \"oceanbase doc 2\"}") };
|
||||
insert_rows.add(ir2);
|
||||
Sqlizable[] ir3 = { new SqlVector(new float[] {0f, 0f, 0f}), new SqlText("{\"doc\": \"oceanbase doc 3\"}") };
|
||||
insert_rows.add(ir3);
|
||||
ob.insert(tb_name, new String[] {"c2", "c3"}, insert_rows);
|
||||
```
|
||||
|
||||
#### Delete data
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# primary_key_name: the name of the primary key column.
|
||||
# primary_keys: an array of primary key column values for the target rows.
|
||||
public void delete(String table_name, String primary_key_name, ArrayList<Sqlizable> primary_keys);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
ArrayList<Sqlizable> ids = new ArrayList<>();
|
||||
ids.add(new SqlInteger(2));
|
||||
ids.add(new SqlInteger(1));
|
||||
ob.delete(tb_name, "c1", ids);
|
||||
```
|
||||
|
||||
#### ANN queries
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# table_name: the name of the target table.
|
||||
# vec_col_name: the name of the vector column.
|
||||
# metric_type: the type of the vector distance function. l2: corresponds to the L2 distance function. cosine: corresponds to the cosine distance function. ip: corresponds to the negative inner product distance function.
|
||||
# qv: the vector value to be queried.
|
||||
# topk: the number of the most similar results to be returned.
|
||||
# output_fields: the projected columns, that is, the array of the fields to be returned.
|
||||
# output_datatypes: the data types of the projected columns, that is, the data types of the fields to be returned, for direct conversion to Java data types.
|
||||
# where_expr: the WHERE condition expression.
|
||||
public ArrayList<HashMap<String, Sqlizable>> query(
|
||||
String table_name,
|
||||
String vec_col_name,
|
||||
String metric_type,
|
||||
float[] qv,
|
||||
int topk,
|
||||
String[] output_fields,
|
||||
DataType[] output_datatypes,
|
||||
String where_expr);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
ArrayList<HashMap<String, Sqlizable>> res = ob.query(tb_name, "c2", "l2",
|
||||
new float[] {0f, 0f, 0f}, 10,
|
||||
new String[] {"c1", "c3", "c2"},
|
||||
new DataType[] {
|
||||
DataType.INT32,
|
||||
DataType.JSON,
|
||||
DataType.FLOAT_VECTOR,
|
||||
"c1 > 0"});
|
||||
if (res != null) {
|
||||
for (int i = 0; i < res.size(); i++) {
|
||||
for (HashMap.Entry<String, Sqlizable> entry : res.get(i).entrySet()) {
|
||||
System.out.printf("%s : %s, ", entry.getKey(), entry.getValue().toString());
|
||||
}
|
||||
System.out.print("\n");
|
||||
}
|
||||
} else {
|
||||
System.out.println("res is null");
|
||||
}
|
||||
```
|
||||
|
||||
### Use the JSON table feature
|
||||
|
||||
The JSON table feature of obvec_jdbc relies on seekdb's ability to handle JSON data types (including `JSON_VALUE`/`JSON_TABLE`/`JSON_REPLACE`, etc.) to implement a virtual table mechanism. Multiple users (distinguished by user ID) can perform DDL or DML operations on virtual tables over the same physical table while ensuring data isolation between users. Admin users can perform DDL operations, while regular users can perform DML operations.
|
||||
|
||||
This design combines the structured management capabilities of relational databases with the flexibility of JSON, showcasing seekdb's multi-model integration capabilities. Users can enjoy the power and ease of use of SQL while also handling semi-structured data, meeting the diverse data model requirements of modern applications. Although operations are still performed on "tables," data is stored in a more flexible JSON format at the underlying level, better supporting complex and varied application scenarios.
|
||||
|
||||
#### How it works
|
||||
|
||||
<!-- The following figure illustrates the principle of JSON Table.
|
||||
|
||||
|
||||
|
||||
Detailed explanation:-->
|
||||
|
||||
1. User operations: Users still interact with the system using familiar standard SQL statements (such as `CREATE TABLE` to create table structures, `INSERT` to insert data, and `SELECT` to query data). They do not need to worry about how data is stored at the underlying level, just like operating ordinary relational database tables. The tables created by users using SQL statements are logical tables, which correspond to two physical tables (`meta_json_t` and `data_json_t`) within seekdb.
|
||||
|
||||
2. JSON Table SDK: Within the application, there is a JSON Table SDK (Software Development Kit). This SDK is the key that connects users' SQL operations and seekdb's actual storage. When SQL statements are executed, the SDK intercepts these requests and intelligently converts them into read and write operations on seekdb's internal tables `meta_json_t` and `data_json_t`.
|
||||
|
||||
3. seekdb internal storage:
|
||||
|
||||
* `meta_json_t` (stores table schema): stores the metadata of the logical tables created by users, which is the schema information of the table (for example, which columns are created and what data type each column is). When `CREATE TABLE` is executed, the SDK records this schema information in `meta_json_t`.
|
||||
* `data_json_t` (stores row data as JSON type): stores the actual inserted data. Unlike traditional relational databases that directly store row data, the JSON Table feature encapsulates each row of inserted data into a JSON object and stores it in a column of the `data_json_t` table. This allows for efficient storage even with flexible data structures.
|
||||
|
||||
4. Data query: When query operations such as `SELECT` are executed, the SDK reads JSON-format data from `data_json_t` and combines it with the schema information from `meta_json_t` to re-parse and present the JSON data in a familiar tabular format, returning it to your application.
|
||||
|
||||
The `meta_json_t` table stores the metadata of the JSON table, which is the logical table schema defined by the user using the `CREATE TABLE` statement. It records the column information of each logical table, with the following schema:
|
||||
|
||||
| Field | Description | Example |
|
||||
|--------|------|------|
|
||||
| `user_id` | The user ID, used to distinguish the logical tables of different users. | `0`, `1`, `2` |
|
||||
| `jtable_name` | The name of the logical table. | `test_count` |
|
||||
| `jcol_id` | The column ID of the logical table. | `1`, `2`, `3` |
|
||||
| `jcol_name` | The column name of the logical table. | `c1`, `c2`, `c3` |
|
||||
| `jcol_type` | The data type of the column. | `INT`, `VARCHAR(124)`, `DECIMAL(10,2)` |
|
||||
| `jcol_nullable` | Indicates whether the column allows null values. | `0`, `1` |
|
||||
| `jcol_has_default` | Indicates whether the column has a default value. | `0`, `1` |
|
||||
| `jcol_default` | The default value of the column. | `{'default': null}` |
|
||||
|
||||
When a user executes the `CREATE TABLE` statement, the JSON table SDK parses and inserts the column definition information into the `meta_json_t` table.
|
||||
|
||||
The `data_json_t` table stores the actual data of the JSON table, which is the data inserted by the user using the `INSERT` statement. It records the row data of each logical table, with the following schema:
|
||||
|
||||
| Field | Description | Example |
|
||||
|--------|------|------|
|
||||
| `user_id` | The user ID, used to distinguish the logical tables of different users. | `0`, `1`, `2` |
|
||||
| `admin_id` | The administrator user ID. | `0` |
|
||||
| `jtable_name` | The name of the logical table, used to associate the metadata in `meta_json_t`. | `test_count` |
|
||||
| `jdata_id` | The data ID, a unique identifier for the JSON data, corresponding to each row in the logical table. | `1`, `2`, `3` |
|
||||
| `jdata` | A column of the JSON type, used to store the actual row data of the logical table. | `{"c1": 1, "c2": "test", "c3": 1.23}` |
|
||||
|
||||
#### Examples
|
||||
|
||||
1. Create a client
|
||||
|
||||
The constructor is as follows:
|
||||
|
||||
```java
|
||||
# uri: the connection string, which contains the address, port, and name of the database to which you want to connect.
|
||||
# user: the username.
|
||||
# password: the password.
|
||||
# user_id: the user ID.
|
||||
# log_level: the log level.
|
||||
public ObVecJsonClient(String uri, String user, String password, String user_id, Level log_level);
|
||||
```
|
||||
|
||||
Here is an example:
|
||||
|
||||
```java
|
||||
import com.oceanbase.obvec_jdbc.ObVecJsonClient;
|
||||
|
||||
String uri = "jdbc:oceanbase://127.0.0.1:2881/test";
|
||||
String user = "root@test";
|
||||
String password = "";
|
||||
ObVecJsonClient client = new ObVecJsonClient(uri, user, password, 0, Level.INFO);
|
||||
```
|
||||
|
||||
2. Execute DDL statements
|
||||
|
||||
You can directly call the `parseJsonTableSQL2NormalSQL` interface and pass in the specific SQL statements.
|
||||
|
||||
* Create a table
|
||||
|
||||
```java
|
||||
String sql = "CREATE TABLE `t2` (c1 INT NOT NULL DEFAULT 10, c2 VARCHAR(30) DEFAULT 'ca', c3 VARCHAR NOT NULL, c4 DECIMAL(10, 2), c5 TIMESTAMP DEFAULT CURRENT_TIMESTAMP);";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE CHANGE COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 CHANGE COLUMN c2 changed_col INT";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE ADD COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 ADD COLUMN email VARCHAR(100) default 'example@example.com'";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE MODIFY COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 MODIFY COLUMN changed_col TIMESTAMP NOT NULL DEFAULT current_timestamp";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE DROP COLUMN
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 DROP c1";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
|
||||
* ALTER TABLE RENAME
|
||||
|
||||
```java
|
||||
sql = "ALTER TABLE t2 RENAME TO alter_test";
|
||||
client.parseJsonTableSQL2NormalSQL(sql);
|
||||
```
|
||||
@@ -0,0 +1,20 @@
|
||||
---
|
||||
|
||||
slug: /vector-search-faq
|
||||
---
|
||||
|
||||
# Vector search FAQs
|
||||
|
||||
This topic describes some common issues that may occur when using vector search, as well as their causes and solutions.
|
||||
|
||||
## Must all rows in a vector column have the same data dimensionality?
|
||||
|
||||
Yes. A data dimensionality must be specified when a vector column is defined, and the dimensionality must be verified when vector data is written into the column.
|
||||
|
||||
## What is the maximum number of rows of vector data that can be written?
|
||||
|
||||
Unlimited. It depends on the database memory resources.
|
||||
|
||||
## How do I create an index on a vector with more than 4096 dimensions?
|
||||
|
||||
You need to compress the data to within 4096 dimensions before creating an index.
|
||||
@@ -0,0 +1,520 @@
|
||||
---
|
||||
|
||||
slug: /using-seekdb-in-python-mode
|
||||
---
|
||||
|
||||
# Experience embedded seekdb
|
||||
|
||||
seekdb provides an embedded product form that can be integrated into user applications as a library, offering developers a more powerful and flexible data management solution. This enables data management everywhere (microcontrollers, IoT devices, edge computing, mobile applications, data centers, etc.), allowing users to quickly get started with seekdb's All-in-one (TP, AP, AI Native) capabilities.
|
||||
|
||||
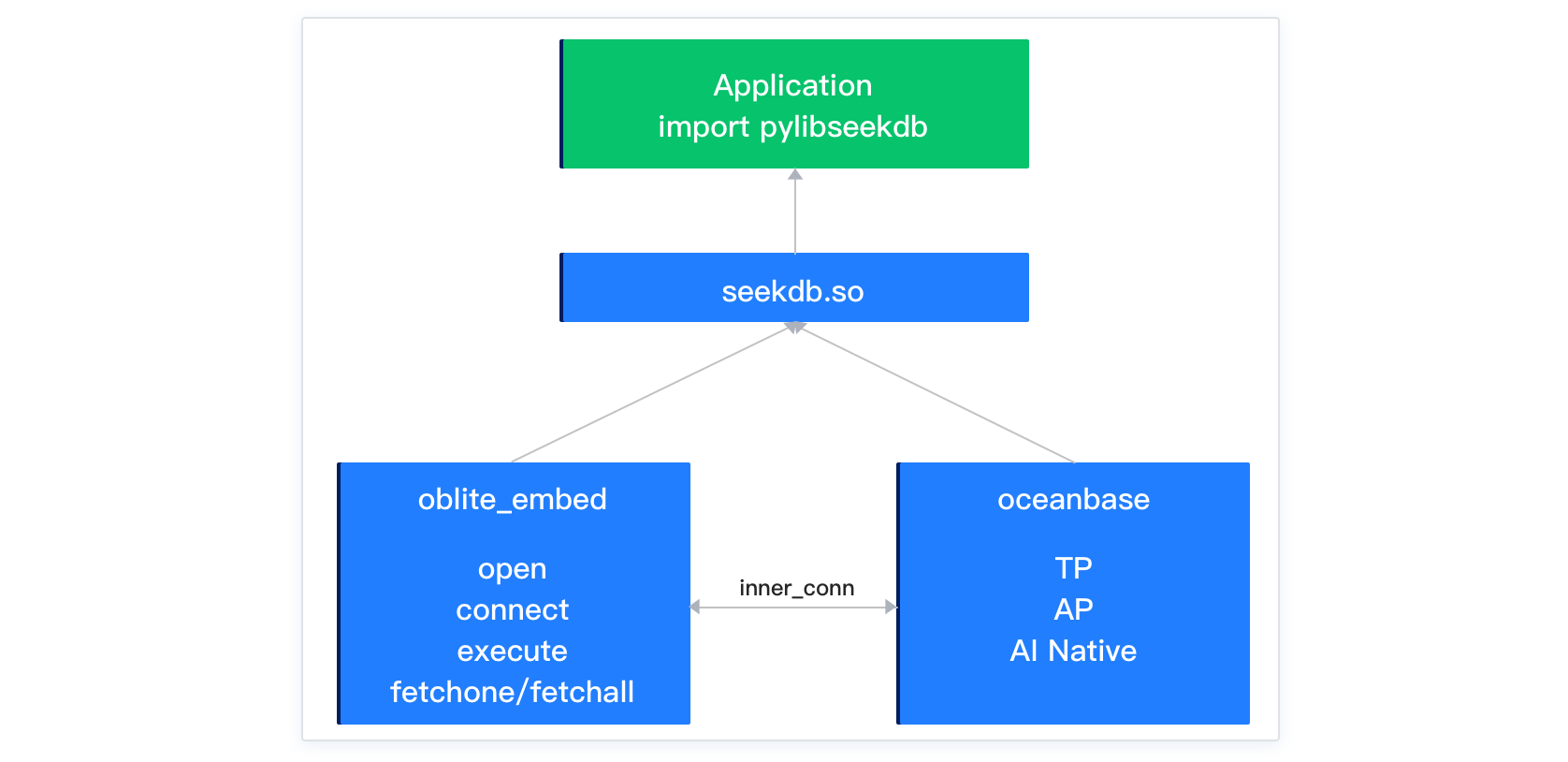
|
||||
|
||||
## Installation and configuration
|
||||
|
||||
### Environment requirements
|
||||
|
||||
* Supported operating systems: Linux (glibc >= 2.28)
|
||||
|
||||
* Supported Python versions: CPython 3.8 ~ 3.14
|
||||
|
||||
* Supported system architectures: x86_64, aarch64
|
||||
|
||||
You can run the following command to check whether your environment meets the requirements.
|
||||
|
||||
```python
|
||||
python -c 'import sys;import platform; print(f"Python: {platform.python_implementation()} {platform.python_version()}, System: {platform.system()} {platform.machine()}, {platform.libc_ver()[0]}: {platform.libc_ver()[1]}");'
|
||||
```
|
||||
|
||||
The output should be like this:
|
||||
|
||||
```python
|
||||
Python: CPython 3.8.17, System: Linux x86_64, glibc: 2.32
|
||||
```
|
||||
|
||||
### Installation
|
||||
|
||||
Use pip to install. It automatically detects the default Python version and platform.
|
||||
|
||||
```python
|
||||
pip install pylibseekdb
|
||||
# Or specify a mirror source for faster installation
|
||||
pip install pylibseekdb -i https://pypi.tuna.tsinghua.edu.cn/simple
|
||||
```
|
||||
|
||||
If your pip version is low, upgrade pip first before installation:
|
||||
|
||||
```bash
|
||||
pip install --upgrade pip
|
||||
```
|
||||
|
||||
## Experience seekdb
|
||||
|
||||
After completing the installation of seekdb, you can start experiencing seekdb.
|
||||
|
||||
#### Considerations
|
||||
|
||||
* Multi-statement queries are not supported. By default, only the first statement is executed. For example:
|
||||
|
||||
```python
|
||||
cur.execute("insert into t1 values(100);insert into t1 values(200)")
|
||||
```
|
||||
|
||||
* The tmpfs file system cannot be used as the database directory.
|
||||
* Only streaming query mode is supported. For example:
|
||||
|
||||
```python
|
||||
cur = con.cursor()
|
||||
cur.execute("select * from t1")
|
||||
cur.fetchall()
|
||||
```
|
||||
|
||||
* The execute method does not support parameterization.
|
||||
|
||||
#### Experience basic seekdb operations
|
||||
|
||||
The following examples demonstrate some basic operations of seekdb. You can create databases, connect to databases, create tables, write and query data, and more.
|
||||
|
||||
:::info
|
||||
For detailed information about seekdb SQL syntax, see <a href="https://en.oceanbase.com/docs/common-oceanbase-database-10000000001972315">SQL syntax</a>.
|
||||
:::
|
||||
|
||||
seekdb provides the `test` database by default. The following example demonstrates how to open and connect to the `test` database using default parameters, and how to create tables, write data, commit transactions, query data, and safely close the database.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
# Open the database directory seekdb by default
|
||||
pylibseekdb.open()
|
||||
# Connect to the test database by default
|
||||
conn = pylibseekdb.connect()
|
||||
# Create a cursor for data operations
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Execute table creation statement
|
||||
cursor.execute("create table t1(c1 int primary key, c2 int)")
|
||||
# Execute data insertion
|
||||
cursor.execute("insert into t1 values(1, 100)")
|
||||
cursor.execute("insert into t1 values(2, 200)")
|
||||
# Manually commit the transaction
|
||||
conn.commit()
|
||||
|
||||
# Execute query
|
||||
cursor.execute("select * from t1")
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
You can also manually specify the database directory and create and use a new database.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
# Specify the database directory
|
||||
pylibseekdb.open("mydb")
|
||||
# Do not connect to any database
|
||||
conn = pylibseekdb.connect("")
|
||||
# Create a cursor for data operations
|
||||
cursor = conn.cursor()
|
||||
# Manually create a database
|
||||
cursor.execute("create database db1")
|
||||
# Use the newly created database
|
||||
cursor.execute("use db1")
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
The following example demonstrates how to enable autocommit mode for transactions.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
# Specify the database directory
|
||||
pylibseekdb.open("seekdb")
|
||||
# Connect to the test database
|
||||
conn = pylibseekdb.connect(database="test", autocommit=True)
|
||||
# Create a cursor for data operations
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Execute table creation statement
|
||||
cursor.execute("create table t2(c1 int primary key, c2 int)")
|
||||
# Execute data insertion, transaction is automatically committed
|
||||
cursor.execute("insert into t2 values(1, 100)")
|
||||
# Execute data insertion, transaction is automatically committed
|
||||
cursor.execute("insert into t2 values(2, 200)")
|
||||
|
||||
# Query data using a new connection
|
||||
conn2 = pylibseekdb.connect("test")
|
||||
cursor2=conn2.cursor()
|
||||
cursor2.execute("select * from t2")
|
||||
# View data row by row
|
||||
print(cursor2.fetchone())
|
||||
print(cursor2.fetchone())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
cursor2.close()
|
||||
conn2.close()
|
||||
```
|
||||
|
||||
### Experience AI Native
|
||||
|
||||
#### Experience vector search
|
||||
|
||||
seekdb supports up to 16,000 dimensions of float-type dense vectors, sparse vectors, and various types of vector distance calculations such as Manhattan distance, Euclidean distance, inner product, and cosine distance. It supports creating vector indexes based on HNSW/IVF, and supports incremental updates and deletions without affecting recall.
|
||||
|
||||
:::info
|
||||
|
||||
For more detailed information about seekdb vector search, see <a href="https://en.oceanbase.com/docs/common-oceanbase-database-10000000001976351">Vector search</a>.
|
||||
:::
|
||||
|
||||
The following example demonstrates how to use vector search in seekdb.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
pylibseekdb.open("seekdb")
|
||||
conn = pylibseekdb.connect("test")
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Create a table with a vector index
|
||||
cursor.execute("create table test_vector(c1 int primary key, c2 vector(2), vector index idx1(c2) with (distance=l2, type=hnsw, lib=vsag))")
|
||||
|
||||
# Insert data
|
||||
cursor.execute("insert into test_vector values(1, [1, 1])")
|
||||
cursor.execute("insert into test_vector values(2, [1, 2])")
|
||||
cursor.execute("insert into test_vector values(3, [1, 3])")
|
||||
conn.commit()
|
||||
|
||||
# Execute vector search
|
||||
cursor.execute("SELECT c1,c2 FROM test_vector ORDER BY l2_distance(c2, '[1, 2.5]') APPROXIMATE LIMIT 2;")
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
#### Experience full-text search
|
||||
|
||||
seekdb provides full-text indexing capabilities. By building full-text indexes, you can comprehensively index entire documents or large text content, significantly improving query performance when dealing with large-scale text data and complex search requirements, enabling users to obtain the required information more efficiently.
|
||||
|
||||
The following example demonstrates how to use seekdb's full-text search feature.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
pylibseekdb.open("seekdb")
|
||||
conn = pylibseekdb.connect("test")
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Create a table with a full-text index
|
||||
sql='''create table articles (title VARCHAR(200) primary key, body Text,
|
||||
FULLTEXT fts_idx(title, body));
|
||||
'''
|
||||
cursor.execute(sql)
|
||||
|
||||
# Insert data
|
||||
sql='''insert into articles(title, body) values
|
||||
('OceanBase Tutorial', 'This is a tutorial about OceanBase Fulltext.'),
|
||||
('Fulltext Index', 'Fulltext index can be very useful.'),
|
||||
('OceanBase Test Case', 'Writing test cases helps ensure quality.')
|
||||
'''
|
||||
cursor.execute(sql)
|
||||
conn.commit()
|
||||
|
||||
# Execute full-text search
|
||||
sql='''select
|
||||
title,
|
||||
match (title, body) against ("OceanBase") as score
|
||||
from
|
||||
articles
|
||||
where
|
||||
match (title, body) against ("OceanBase")
|
||||
order by
|
||||
score desc
|
||||
'''
|
||||
cursor.execute(sql)
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
#### Experience hybrid search
|
||||
|
||||
Hybrid Search combines vector-based semantic search and full-text index-based keyword search, providing more accurate and comprehensive search results through comprehensive ranking. Vector search excels at semantic approximate matching but is weak at matching exact keywords, numbers, and proper nouns, while full-text search effectively compensates for this deficiency. Therefore, hybrid search has become one of the key features of vector databases and is widely used in various products.
|
||||
|
||||
Based on multi-model integration, seekdb provides hybrid search capabilities for multi-modal data on the basis of SQL+AI, enabling fusion queries of multiple types of data in a single database system.
|
||||
|
||||
The following example demonstrates how to use seekdb's hybrid search feature.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
pylibseekdb.open("seekdb")
|
||||
conn = pylibseekdb.connect("test")
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Create a table with vector indexes and full-text indexes
|
||||
cursor.execute("create table doc_table(c1 int, vector vector(3), query varchar(255), content varchar(255), vector index idx1(vector) with (distance=l2, type=hnsw, lib=vsag), fulltext idx2(query), fulltext idx3(content))")
|
||||
|
||||
# Insert data
|
||||
sql = '''insert into doc_table values(1, '[1,2,3]', "hello world", "oceanbase Elasticsearch database"),
|
||||
(2, '[1,2,1]', "hello world, what is your name", "oceanbase mysql database"),
|
||||
(3, '[1,1,1]', "hello world, how are you", "oceanbase oracle database"),
|
||||
(4, '[1,3,1]', "real world, where are you from", "postgres oracle database"),
|
||||
(5, '[1,3,2]', "real world, how old are you", "redis oracle database"),
|
||||
(6, '[2,1,1]', "hello world, where are you from", "starrocks oceanbase database");'''
|
||||
cursor.execute(sql)
|
||||
conn.commit()
|
||||
|
||||
|
||||
sql = '''set @parm = '{
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"match": {"query": "hi hello"}},
|
||||
{"match": { "content": "oceanbase mysql" }}
|
||||
]
|
||||
}
|
||||
},
|
||||
"knn" : {
|
||||
"field": "vector",
|
||||
"k": 5,
|
||||
"num_candidates": 10,
|
||||
"query_vector": [1,2,3],
|
||||
"boost": 0.7
|
||||
},
|
||||
"_source" : ["query", "content", "_keyword_score", "_semantic_score"]
|
||||
}';'''
|
||||
cursor.execute(sql)
|
||||
|
||||
# Execute hybrid search
|
||||
sql = '''select dbms_hybrid_search.search('doc_table', @parm);'''
|
||||
cursor.execute(sql)
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
### Experience analytical capabilities (OLAP)
|
||||
|
||||
seekdb combines transaction processing (TP) with analytical processing (AP). Based on the LSM-Tree architecture, it achieves unified row and column storage, and introduces a new vectorized engine and cost evaluation model based on column storage, significantly improving the efficiency of processing wide tables and enhancing query performance in AP scenarios. It also supports real-time import, secondary indexes, high-concurrency primary key queries, and other common real-time OLAP requirements.
|
||||
|
||||
#### Experience data import
|
||||
|
||||
seekdb supports various flexible data import methods, allowing you to import data from multiple data sources into the database. Different import methods are suitable for different scenarios. You can choose appropriate import tools for data import based on data source types and business scenarios. As scenarios become more complex and diverse, multiple import methods can be used together. When importing data, in addition to considering data sources, data file formats should also be considered along with the support of import tools. When business scenarios have clearly defined data sources and data file formats, you need to start from the data source and consider the design of the import solution in combination with import tools. When businesses have import tools they are familiar with, you need to consider the tool's support and the possibility of import in combination with business scenarios.
|
||||
|
||||
The following example uses the `load data` method to demonstrate how to quickly import CSV data into seekdb.
|
||||
|
||||
1. Create an external data source
|
||||
|
||||
```bash
|
||||
cat /data/1/example.csv
|
||||
1,10
|
||||
2,20
|
||||
3,30
|
||||
```
|
||||
|
||||
2. Import external data using the embedded method.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
pylibseekdb.open("seekdb")
|
||||
conn = pylibseekdb.connect("test")
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Create a table
|
||||
cursor.execute("create table test_olap(c1 int, c2 int)")
|
||||
# Execute fast import
|
||||
cursor.execute("load data /*+ direct(true, 0) */ infile '/data/1/example.csv' into table test_olap fields terminated by ','")
|
||||
# Query data
|
||||
cursor.execute("select count(*) from test_olap")
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
#### Experience columnar storage
|
||||
|
||||
In scenarios involving complex analysis of large-scale data or ad-hoc queries on massive data, columnar storage is one of the key capabilities of AP databases. The seekdb storage engine has been further enhanced on the basis of supporting row storage, achieving support for column storage and unified storage. With one codebase, one architecture, and one instance, columnar data and row data coexist.
|
||||
|
||||
The following example demonstrates how to create a columnar table in seekdb.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
pylibseekdb.open("seekdb")
|
||||
conn = pylibseekdb.connect("test")
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Create a columnar table
|
||||
sql='''create table each_column_group (col1 varchar(30) not null, col2 varchar(30) not null, col3 varchar(30) not null, col4 varchar(30) not null, col5 int)
|
||||
with column group (each column);
|
||||
'''
|
||||
cursor.execute(sql)
|
||||
|
||||
# Insert data
|
||||
sql='''insert into each_column_group values('a', 'b', 'c', 'd', 1)
|
||||
'''
|
||||
cursor.execute(sql)
|
||||
conn.commit()
|
||||
|
||||
# Execute query
|
||||
cursor.execute("select col1,col2 from each_column_group")
|
||||
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
#### Experience materialized views
|
||||
|
||||
Materialized views are a key feature supporting AP business. They improve query performance and simplify complex query logic by precomputing and storing query results of views, reducing real-time computation. They are commonly used in fast report generation and data analysis scenarios. seekdb supports non-real-time and real-time materialized views, supports specifying primary keys or creating indexes for materialized views, and introduces nested materialized views, which can significantly improve query performance.
|
||||
|
||||
The following example demonstrates how to use materialized views in seekdb.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
import time
|
||||
|
||||
pylibseekdb.open("seekdb")
|
||||
conn = pylibseekdb.connect("test")
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Create base tables
|
||||
cursor.execute("create table base_t1(a int primary key, b int)")
|
||||
cursor.execute("create table base_t2(c int primary key, d int)")
|
||||
|
||||
# Create materialized view logs
|
||||
cursor.execute("create materialized view log on base_t1 with(b)")
|
||||
cursor.execute("create materialized view log on base_t2 with(d)")
|
||||
|
||||
# Create a materialized view named mv based on tables base_t1 and base_t2, specify the refresh strategy as incremental refresh, and set the initial refresh time in the refresh plan to the current date, then refresh the materialized view every 1 second thereafter.
|
||||
cursor.execute("create materialized view mv REFRESH fast START WITH sysdate() NEXT sysdate() + INTERVAL 1 second as select a,b,c,d from base_t1 join base_t2 on base_t1.a=base_t2.c")
|
||||
|
||||
# Insert data into base tables
|
||||
cursor.execute("insert into base_t1 values(1, 10)")
|
||||
cursor.execute("insert into base_t2 values(1, 100)")
|
||||
conn.commit()
|
||||
|
||||
# Wait for the materialized view background refresh to complete
|
||||
time.sleep(10)
|
||||
|
||||
# Query data
|
||||
cursor.execute("select * from mv")
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
#### Experience external tables
|
||||
|
||||
Typically, table data in a database is stored in the database's storage space, while external table data is stored in external storage services. When creating an external table, you need to define the data file path and data file format. After creation, users can read data from files in external storage services through external tables.
|
||||
|
||||
The following example demonstrates how to access external CSV files through seekdb's external table feature.
|
||||
|
||||
1. Create an external data source.
|
||||
|
||||
```bash
|
||||
cat /data/1/example.csv
|
||||
1,10
|
||||
2,20
|
||||
3,30
|
||||
```
|
||||
|
||||
2. Access external table data using the embedded method.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
pylibseekdb.open("seekdb")
|
||||
conn = pylibseekdb.connect("test")
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Create an external table
|
||||
sql='''CREATE EXTERNAL TABLE test_external_table(c1 int, c2 int) LOCATION='/data/1' FORMAT=(TYPE='CSV' FIELD_DELIMITER=',') PATTERN='example.csv';
|
||||
'''
|
||||
cursor.execute(sql)
|
||||
|
||||
# Query data
|
||||
cursor.execute("select * from test_external_table")
|
||||
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
### Experience transaction capabilities (OLTP)
|
||||
|
||||
The following example demonstrates seekdb's transaction capabilities.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
|
||||
pylibseekdb.open("seekdb")
|
||||
conn = pylibseekdb.connect("test")
|
||||
cursor = conn.cursor()
|
||||
|
||||
# Create a table
|
||||
cursor.execute("create table test_oltp(c1 int primary key, c2 int)")
|
||||
|
||||
# Insert data
|
||||
cursor.execute("insert into test_oltp values(1, 10)")
|
||||
cursor.execute("insert into test_oltp values(2, 20)")
|
||||
cursor.execute("insert into test_oltp values(3, 30)")
|
||||
# Commit transaction
|
||||
conn.commit()
|
||||
|
||||
# Query data, ORA_ROWSCN is the data commit version number
|
||||
cursor.execute("select *,ORA_ROWSCN from test_oltp")
|
||||
# Fetch results
|
||||
print(cursor.fetchall())
|
||||
|
||||
# Close connections
|
||||
cursor.close()
|
||||
conn.close()
|
||||
```
|
||||
|
||||
## Smooth transition to the distributed version
|
||||
|
||||
After users quickly validate product prototypes through the embedded version, if they want to switch to seekdb Server mode or use OceanBase's distributed version cluster processing capabilities, they only need to modify the import package and related configuration, while the main application logic remains unchanged.
|
||||
|
||||
```python
|
||||
import pylibseekdb
|
||||
pylibseekdb.open()
|
||||
conn = pylibseekdb.connect()
|
||||
```
|
||||
|
||||
Simply replace the three lines above with the two lines below. Use the pymysql package to replace pylibseekdb, remove the pylibseekdb open phase, and use pymysql's connect method to connect to the database server.
|
||||
|
||||
```python
|
||||
import pymysql
|
||||
conn = pymysql.connect(host='127.0.0.1', port=11002, user='root@sys', database='test')
|
||||
```
|
||||
@@ -0,0 +1,871 @@
|
||||
---
|
||||
|
||||
slug: /vector-index-hybrid-search
|
||||
---
|
||||
|
||||
# Hybrid search with vector indexes
|
||||
|
||||
This topic describes hybrid search with full-text indexes and vector indexes in seekdb.
|
||||
|
||||
Hybrid search combines vector-based semantic search and full-text index-based keyword search, providing more accurate and comprehensive search results through integrated ranking. Vector search excels at semantic approximate matching but has weaker capabilities for matching exact keywords, numbers, and proper nouns. Full-text search effectively compensates for this limitation. Therefore, hybrid search has become a key feature of vector databases and is widely used in various products. seekdb achieves efficient hybrid queries by integrating its full-text and vector indexing capabilities.
|
||||
|
||||
## Usage
|
||||
|
||||
The hybrid search feature is provided through the new system package `DBMS_HYBRID_SEARCH`, which contains 2 sub-functions:
|
||||
|
||||
| Method name | Description |
|
||||
| ------------ | -------- |
|
||||
| `DBMS_HYBRID_SEARCH.SEARCH` | Returns search results in JSON format. Results are sorted by relevance. |
|
||||
| `DBMS_HYBRID_SEARCH.GET_SQL` | Returns the actual executed SQL statement as a string. |
|
||||
|
||||
<!--For detailed syntax and parameter descriptions, see [DBMS_HYBRID_SEARCH](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000004020384).-->
|
||||
|
||||
## Use cases and examples
|
||||
|
||||
### Create example tables and insert data
|
||||
|
||||
To demonstrate the hybrid search feature, this section creates and inserts data into several example tables that will be used in different search scenarios below.
|
||||
|
||||
* **`products` table**: A basic product information table used to demonstrate regular scalar search. It contains product ID, name, description, brand, category, tags, price, stock quantity, release date, on-sale status, and a vector field `vec`.
|
||||
:::collapse
|
||||
|
||||
```sql
|
||||
CREATE TABLE products (
|
||||
`product_id` varchar(50) DEFAULT NULL,
|
||||
`product_name` varchar(255) DEFAULT NULL,
|
||||
`description` text DEFAULT NULL,
|
||||
`brand` varchar(100) DEFAULT NULL,
|
||||
`category` varchar(100) DEFAULT NULL,
|
||||
`tags` varchar(255) DEFAULT NULL,
|
||||
`price` decimal(10,2) DEFAULT NULL,
|
||||
`stock_quantity` int(11) DEFAULT NULL,
|
||||
`release_date` datetime DEFAULT NULL,
|
||||
`is_on_sale` tinyint(1) DEFAULT NULL,
|
||||
`vec` VECTOR(4) DEFAULT NULL
|
||||
);
|
||||
```
|
||||
|
||||
Insert data.
|
||||
|
||||
```sql
|
||||
INSERT INTO products VALUES
|
||||
('prod-001', 'Gamer-Pro Mechanical Keyboard', 'A responsive mechanical keyboard with customizable RGB lighting for the ultimate gaming experience.',
|
||||
'GamerZone', 'Gaming', 'best-seller,gaming-gear,rgb', 149.00, 100, '2023-07-20 00:00:00.000000', 1, '[0.5,0.1,0.6,0.9]'),
|
||||
|
||||
('prod-002', 'Gamer-Pro Headset', 'High-fidelity gaming headset with a noise-cancelling microphone.',
|
||||
'GamerZone', 'Gaming', 'best-seller,gaming-gear,audio', 149.00, 100, '2023-07-20 00:00:00.000000', 1, '[0.1,0.9,0.2,0]'),
|
||||
|
||||
('prod-003', 'Eco-Friendly Yoga Mat', 'A non-slip yoga mat made from sustainable and eco-friendly materials.',
|
||||
'NatureFirst', 'Sports', 'eco-friendly,health', 49.99, 200, '2023-04-22 00:00:00.000000', 0, '[0.1,0.9,0.3,0]');
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
|
||||
* **`products_fulltext` table**: Based on the `products` table, full-text indexes are created on the `product_name`, `description`, and `tags` columns to demonstrate full-text search.
|
||||
:::collapse
|
||||
|
||||
```sql
|
||||
CREATE TABLE products_fulltext (
|
||||
product_id VARCHAR(50),
|
||||
product_name VARCHAR(255),
|
||||
description TEXT,
|
||||
brand VARCHAR(100),
|
||||
category VARCHAR(100),
|
||||
tags VARCHAR(255),
|
||||
price DECIMAL(10, 2),
|
||||
stock_quantity INT,
|
||||
release_date DATETIME,
|
||||
is_on_sale TINYINT(1),
|
||||
vec vector(4),
|
||||
-- Create full-text indexes on columns that need full-text search
|
||||
FULLTEXT INDEX idx_product_name(product_name),
|
||||
FULLTEXT INDEX idx_description(description),
|
||||
FULLTEXT INDEX idx_tags(tags)
|
||||
);
|
||||
```
|
||||
|
||||
Insert data.
|
||||
|
||||
```sql
|
||||
INSERT INTO products_fulltext VALUES
|
||||
('prod-001', 'Gamer-Pro Mechanical Keyboard', 'A responsive mechanical keyboard with customizable RGB lighting for the ultimate gaming experience.',
|
||||
'GamerZone', 'Gaming', 'best-seller,gaming-gear,rgb', 149.00, 100, '2023-07-20 00:00:00.000000', 1, '[0.5,0.1,0.6,0.9]'),
|
||||
|
||||
('prod-002', 'Gamer-Pro Headset', 'High-fidelity gaming headset with a noise-cancelling microphone.',
|
||||
'GamerZone', 'Gaming', 'best-seller,gaming-gear,audio', 149.00, 100, '2023-07-20 00:00:00.000000', 1, '[0.1,0.9,0.2,0]'),
|
||||
|
||||
('prod-003', 'Eco-Friendly Yoga Mat', 'A non-slip yoga mat made from sustainable and eco-friendly materials.',
|
||||
'NatureFirst', 'Sports', 'eco-friendly,health', 49.99, 200, '2023-04-22 00:00:00.000000', 0, '[0.1,0.9,0.3,0]');
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
|
||||
* **`doc_table` table**: A document table containing scalar columns, vector columns, and full-text indexed columns, used to demonstrate full-text search with scalar filtering conditions and hybrid search.
|
||||
:::collapse
|
||||
|
||||
```sql
|
||||
CREATE TABLE doc_table(
|
||||
c1 INT,
|
||||
vector VECTOR(3),
|
||||
query VARCHAR(255),
|
||||
content VARCHAR(255),
|
||||
VECTOR INDEX idx1(vector) WITH (distance=l2, type=hnsw, lib=vsag),
|
||||
FULLTEXT INDEX idx2(query),
|
||||
FULLTEXT INDEX idx3(content)
|
||||
);
|
||||
```
|
||||
|
||||
Insert data.
|
||||
|
||||
```sql
|
||||
INSERT INTO doc_table VALUES
|
||||
(1, '[1,2,3]', "hello world", "oceanbase Elasticsearch database"),
|
||||
|
||||
(2, '[1,2,1]', "hello world, what is your name", "oceanbase mysql database"),
|
||||
|
||||
(3, '[1,1,1]', "hello world, how are you", "oceanbase oracle database"),
|
||||
|
||||
(4, '[1,3,1]', "real world, where are you from", "postgres oracle database"),
|
||||
|
||||
(5, '[1,3,2]', "real world, how old are you", "redis oracle database"),
|
||||
|
||||
(6, '[2,1,1]', "hello world, where are you from", "starrocks oceanbase database");
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
* **`products_vector` table**: Similar to the `products` table structure, but with a vector index explicitly created on the `vec` column to demonstrate pure vector search.
|
||||
:::collapse
|
||||
|
||||
```sql
|
||||
CREATE TABLE products_vector (
|
||||
`product_id` varchar(50) DEFAULT NULL,
|
||||
`product_name` varchar(255) DEFAULT NULL,
|
||||
`description` text DEFAULT NULL,
|
||||
`brand` varchar(100) DEFAULT NULL,
|
||||
`category` varchar(100) DEFAULT NULL,
|
||||
`tags` varchar(255) DEFAULT NULL,
|
||||
`price` decimal(10,2) DEFAULT NULL,
|
||||
`stock_quantity` int(11) DEFAULT NULL,
|
||||
`release_date` datetime DEFAULT NULL,
|
||||
`is_on_sale` tinyint(1) DEFAULT NULL,
|
||||
`vec` VECTOR(4) DEFAULT NULL,
|
||||
-- Create a vector index on the column that needs vector search
|
||||
VECTOR INDEX idx1(vec) WITH (distance=l2, type=hnsw, lib=vsag)
|
||||
);
|
||||
```
|
||||
|
||||
Insert data.
|
||||
|
||||
```sql
|
||||
INSERT INTO products_vector VALUES
|
||||
('prod-001', 'Gamer-Pro Mechanical Keyboard', 'A responsive mechanical keyboard with customizable RGB lighting for the ultimate gaming experience.',
|
||||
'GamerZone', 'Gaming', 'best-seller,gaming-gear,rgb', 149.00, 100, '2023-07-20 00:00:00.000000', 1, '[0.5,0.1,0.6,0.9]'),
|
||||
|
||||
('prod-002', 'Gamer-Pro Headset', 'High-fidelity gaming headset with a noise-cancelling microphone.',
|
||||
'GamerZone', 'Gaming', 'best-seller,gaming-gear,audio', 149.00, 100, '2023-07-20 00:00:00.000000', 1, '[0.1,0.9,0.2,0]'),
|
||||
|
||||
('prod-003', 'Eco-Friendly Yoga Mat', 'A non-slip yoga mat made from sustainable and eco-friendly materials.',
|
||||
'NatureFirst', 'Sports', 'eco-friendly,health', 49.99, 200, '2023-04-22 00:00:00.000000', 0, '[0.1,0.9,0.3,0]');
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
* **`products_multi_vector` table**: A table containing multiple vector fields, used to demonstrate multi-vector search.
|
||||
:::collapse
|
||||
|
||||
```sql
|
||||
CREATE TABLE products_multi_vector (
|
||||
product_id VARCHAR(50),
|
||||
product_name VARCHAR(255),
|
||||
description TEXT,
|
||||
vec1 VECTOR(4),
|
||||
vec2 VECTOR(4),
|
||||
vec3 VECTOR(4),
|
||||
VECTOR INDEX idx1(vec1) WITH (distance=l2, type=hnsw, lib=vsag),
|
||||
VECTOR INDEX idx2(vec2) WITH (distance=l2, type=hnsw, lib=vsag),
|
||||
VECTOR INDEX idx3(vec3) WITH (distance=l2, type=hnsw, lib=vsag)
|
||||
);
|
||||
```
|
||||
|
||||
Insert data.
|
||||
|
||||
```sql
|
||||
INSERT INTO products_multi_vector VALUES
|
||||
('prod-001', 'Gamer-Pro Mechanical Keyboard', 'A responsive mechanical keyboard', '[0.5,0.1,0.6,0.9]', '[0.2,0.3,0.4,0.5]', '[0.1,0.2,0.3,0.4]'),
|
||||
('prod-002', 'Gamer-Pro Headset', 'High-fidelity gaming headset', '[0.1,0.9,0.2,0]', '[0.3,0.4,0.5,0.6]', '[0.2,0.3,0.4,0.5]'),
|
||||
('prod-003', 'Eco-Friendly Yoga Mat', 'A non-slip yoga mat', '[0.1,0.9,0.3,0]', '[0.4,0.5,0.6,0.7]', '[0.3,0.4,0.5,0.6]');
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Regular scalar search
|
||||
|
||||
Some use cases for regular scalar search are as follows:
|
||||
|
||||
* E-commerce platform product filtering: Users want to view all products from a specific brand. For example, users want to view all products from the `GamerZone` brand.
|
||||
* Content management systems: Administrators need to filter articles or documents by specific categories. For example, finding all articles by a specific author.
|
||||
* User management systems: Finding users with specific statuses or roles. For example, finding all VIP users.
|
||||
|
||||
Example:
|
||||
|
||||
1. Set search parameters.
|
||||
|
||||
```sql
|
||||
SET @parm = '{
|
||||
"query": {
|
||||
"bool": {
|
||||
"must": [
|
||||
{"term": {"brand": "GamerZone"}}
|
||||
]
|
||||
}
|
||||
}
|
||||
}';
|
||||
```
|
||||
|
||||
2. Search for all records where `brand` is `"GamerZone"`.
|
||||
|
||||
```sql
|
||||
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products', @parm));
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
:::collapse{title="Return result"}
|
||||
|
||||
```shell
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products', @parm)) |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [
|
||||
{
|
||||
"vec": "[0.5,0.1,0.6,0.9]",
|
||||
"tags": "best-seller,gaming-gear,rgb",
|
||||
"brand": "GamerZone",
|
||||
"price": 149.00,
|
||||
"_score": 1,
|
||||
"category": "Gaming",
|
||||
"is_on_sale": 1,
|
||||
"product_id": "prod-004",
|
||||
"description": "A responsive mechanical keyboard with customizable RGB lighting for the ultimate gaming experience.",
|
||||
"product_name": "Gamer-Pro Mechanical Keyboard",
|
||||
"release_date": "2023-07-20 00:00:00.000000",
|
||||
"stock_quantity": 100
|
||||
},
|
||||
{
|
||||
"vec": "[0.1,0.9,0.2,0]",
|
||||
"tags": "best-seller,gaming-gear,audio",
|
||||
"brand": "GamerZone",
|
||||
"price": 149.00,
|
||||
"_score": 1,
|
||||
"category": "Gaming",
|
||||
"is_on_sale": 1,
|
||||
"product_id": "prod-009",
|
||||
"description": "High-fidelity gaming headset with a noise-cancelling microphone.",
|
||||
"product_name": "Gamer-Pro Headset",
|
||||
"release_date": "2023-07-20 00:00:00.000000",
|
||||
"stock_quantity": 100
|
||||
}
|
||||
] |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Range search for regular scalars
|
||||
|
||||
Some use cases for regular scalar range search are as follows:
|
||||
|
||||
* Price range filtering: E-commerce platforms filter products by price range. For example, finding products with prices in the `[30~80]` range.
|
||||
* Time range queries: Finding orders or logs within a specific time period. For example, finding orders from the last 30 days.
|
||||
* Numeric range filtering: Filtering by rating, stock quantity, and other numeric ranges. For example, finding products with ratings between `[4~5]`.
|
||||
|
||||
Example:
|
||||
|
||||
1. Set search parameters.
|
||||
|
||||
```sql
|
||||
SET @parm = '{
|
||||
"query": {
|
||||
"range" : {
|
||||
"price" : {
|
||||
"gte" : 30,
|
||||
"lte" : 80
|
||||
}
|
||||
}
|
||||
}
|
||||
}';
|
||||
```
|
||||
|
||||
2. Search for all records where `price` is in the `[30~80]` range.
|
||||
|
||||
```sql
|
||||
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products', @parm));
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
:::collapse{title="Return result"}
|
||||
|
||||
```shell
|
||||
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products', @parm)) |
|
||||
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [
|
||||
{
|
||||
"vec": "[0.1,0.9,0.3,0]",
|
||||
"tags": "eco-friendly,health",
|
||||
"brand": "NatureFirst",
|
||||
"price": 49.99,
|
||||
"_score": true,
|
||||
"category": "Sports",
|
||||
"is_on_sale": 0,
|
||||
"product_id": "prod-003",
|
||||
"description": "A non-slip yoga mat made from sustainable and eco-friendly materials.",
|
||||
"product_name": "Eco-Friendly Yoga Mat",
|
||||
"release_date": "2023-04-22 00:00:00.000000",
|
||||
"stock_quantity": 200
|
||||
}
|
||||
] |
|
||||
+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Full-text search
|
||||
|
||||
Some use cases for full-text search are as follows:
|
||||
|
||||
* Document search: Searching for content containing specific keywords in a large number of documents. For example, searching for documents containing `"how to use"` in FAQs.
|
||||
* Product search: Fuzzy search based on product names and descriptions. For example, searching for products containing `"database"`.
|
||||
* Knowledge base retrieval: Searching for related questions in FAQs and help documents. For example, searching for answers to related questions in a customer service system's knowledge base.
|
||||
|
||||
Example:
|
||||
|
||||
1. Set search parameters.
|
||||
|
||||
```sql
|
||||
SET @query_str_with_mini = '{
|
||||
"query": {
|
||||
"query_string": {
|
||||
"type": "best_fields",
|
||||
"fields": ["product_name^3", "description^2.5", "tags^1.5"],
|
||||
"query": "Gamer-Pro^2 keyboard^1.5 audio^1.2",
|
||||
"boost": 1.5
|
||||
}
|
||||
}
|
||||
}';
|
||||
```
|
||||
|
||||
2. Search for records where the `product_name`, `description`, and `tags` fields contain the keywords `"Gamer-Pro"`, `"keyboard"`, and `"audio"`, and sort them according to the set field and keyword weights.
|
||||
|
||||
```sql
|
||||
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products_fulltext', @query_str_with_mini));
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
:::collapse{title="Return result"}
|
||||
|
||||
```shell
|
||||
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products_fulltext', @query_str_with_mini)) |
|
||||
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [
|
||||
{
|
||||
"vec": "[0.5,0.1,0.6,0.9]",
|
||||
"tags": "best-seller,gaming-gear,rgb",
|
||||
"brand": "GamerZone",
|
||||
"price": 149.00,
|
||||
"_score": 4.569735248749978,
|
||||
"category": "Gaming",
|
||||
"is_on_sale": 1,
|
||||
"product_id": "prod-001",
|
||||
"description": "A responsive mechanical keyboard with customizable RGB lighting for the ultimate gaming experience.",
|
||||
"product_name": "Gamer-Pro Mechanical Keyboard",
|
||||
"release_date": "2023-07-20 00:00:00.000000",
|
||||
"stock_quantity": 100
|
||||
},
|
||||
{
|
||||
"vec": "[0.1,0.9,0.2,0]",
|
||||
"tags": "best-seller,gaming-gear,audio",
|
||||
"brand": "GamerZone",
|
||||
"price": 149.00,
|
||||
"_score": 1.7338881172399914,
|
||||
"category": "Gaming",
|
||||
"is_on_sale": 1,
|
||||
"product_id": "prod-002",
|
||||
"description": "High-fidelity gaming headset with a noise-cancelling microphone.",
|
||||
"product_name": "Gamer-Pro Headset",
|
||||
"release_date": "2023-07-20 00:00:00.000000",
|
||||
"stock_quantity": 100
|
||||
}
|
||||
] |
|
||||
+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Full-text search with scalar filtering conditions
|
||||
|
||||
Some use cases for full-text search with scalar filtering conditions are as follows:
|
||||
|
||||
* Precise search: Performing text search under specific conditions. For example, searching for specific keywords in articles with published status.
|
||||
* Permission control: Searching within data ranges that users have permission to access. For example, an order system searching for product information in orders within a specific time period.
|
||||
* Category search: Performing keyword search within specific categories. For example, a user system searching for specific user information among active users.
|
||||
|
||||
Example:
|
||||
|
||||
1. Set search parameters.
|
||||
|
||||
```sql
|
||||
-- Filter condition: specify scalar filter condition c1 >= 2
|
||||
SET @query_str = '{
|
||||
"query": {
|
||||
"bool" : {
|
||||
"must" : [
|
||||
{"query_string": {
|
||||
"fields": ["query", "content"],
|
||||
"query": "hello what oceanbase mysql"}
|
||||
}
|
||||
],
|
||||
"filter" : [
|
||||
{"range": {"c1": {"gte" : 2}}}
|
||||
]
|
||||
}
|
||||
}
|
||||
}';
|
||||
```
|
||||
|
||||
2. Search for all records where `c1` is greater than or equal to 2.
|
||||
|
||||
```sql
|
||||
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @query_str));
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
:::collapse{title="Return result"}
|
||||
|
||||
```shell
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| json_pretty(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @query_str)) |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [
|
||||
{
|
||||
"c1": 2,
|
||||
"query": "hello world, what is your name",
|
||||
"_score": 2.170969786679347,
|
||||
"vector": "[1,2,1]",
|
||||
"content": "oceanbase mysql database"
|
||||
},
|
||||
{
|
||||
"c1": 3,
|
||||
"query": "hello world, how are you",
|
||||
"_score": 0.3503184713375797,
|
||||
"vector": "[1,1,1]",
|
||||
"content": "oceanbase oracle database"
|
||||
},
|
||||
{
|
||||
"c1": 6,
|
||||
"query": "hello world, where are you from",
|
||||
"_score": 0.3503184713375797,
|
||||
"vector": "[2,1,1]",
|
||||
"content": "starrocks oceanbase database"
|
||||
}
|
||||
] |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Vector search
|
||||
|
||||
Some use cases for vector search are as follows:
|
||||
|
||||
* Semantic search: Finding related content based on semantic similarity. For example, finding semantically related questions and answers in a knowledge base.
|
||||
* Recommendation systems: Recommending similar products based on user preferences. For example, recommending similar products on e-commerce platforms.
|
||||
* Image search: Finding similar images through image features. For example, finding similar images in an image library.
|
||||
* Intelligent Q&A: Finding semantically related questions and answers in a knowledge base. For example, finding semantically related questions and answers in a customer service system's knowledge base.
|
||||
|
||||
Example:
|
||||
|
||||
1. Set search parameters.
|
||||
|
||||
```sql
|
||||
-- field specifies the vector field, k specifies the number of results to return (the k nearest results), query_vector specifies the query vector
|
||||
SET @parm = '{
|
||||
"knn" : {
|
||||
"field": "vec",
|
||||
"k": 3,
|
||||
"query_vector": [0.5,0.1,0.6,0.9]
|
||||
}
|
||||
}';
|
||||
```
|
||||
|
||||
2. Search for all records where `vec` is similar to `[0.5,0.1,0.6,0.9]`.
|
||||
|
||||
```sql
|
||||
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products_vector', @parm));
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
:::collapse{title="Return result"}
|
||||
|
||||
```shell
|
||||
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products_vector', @parm)) |
|
||||
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [
|
||||
{
|
||||
"vec": "[0.5,0.1,0.6,0.9]",
|
||||
"tags": "best-seller,gaming-gear,rgb",
|
||||
"brand": "GamerZone",
|
||||
"price": 149.00,
|
||||
"_score": 1.0,
|
||||
"category": "Gaming",
|
||||
"is_on_sale": 1,
|
||||
"product_id": "prod-001",
|
||||
"description": "A responsive mechanical keyboard with customizable RGB lighting for the ultimate gaming experience.",
|
||||
"product_name": "Gamer-Pro Mechanical Keyboard",
|
||||
"release_date": "2023-07-20 00:00:00.000000",
|
||||
"stock_quantity": 100
|
||||
},
|
||||
{
|
||||
"vec": "[0.1,0.9,0.3,0]",
|
||||
"tags": "eco-friendly,health",
|
||||
"brand": "NatureFirst",
|
||||
"price": 49.99,
|
||||
"_score": 0.43405784,
|
||||
"category": "Sports",
|
||||
"is_on_sale": 0,
|
||||
"product_id": "prod-003",
|
||||
"description": "A non-slip yoga mat made from sustainable and eco-friendly materials.",
|
||||
"product_name": "Eco-Friendly Yoga Mat",
|
||||
"release_date": "2023-04-22 00:00:00.000000",
|
||||
"stock_quantity": 200
|
||||
},
|
||||
{
|
||||
"vec": "[0.1,0.9,0.2,0]",
|
||||
"tags": "best-seller,gaming-gear,audio",
|
||||
"brand": "GamerZone",
|
||||
"price": 149.00,
|
||||
"_score": 0.42910841,
|
||||
"category": "Gaming",
|
||||
"is_on_sale": 1,
|
||||
"product_id": "prod-002",
|
||||
"description": "High-fidelity gaming headset with a noise-cancelling microphone.",
|
||||
"product_name": "Gamer-Pro Headset",
|
||||
"release_date": "2023-07-20 00:00:00.000000",
|
||||
"stock_quantity": 100
|
||||
}
|
||||
] |
|
||||
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Vector search with scalar filtering conditions
|
||||
|
||||
Some use cases for vector search with scalar filtering conditions are as follows:
|
||||
|
||||
* Precise search: Performing text search under specific conditions. For example, searching for specific keywords in articles with published status.
|
||||
* Permission control: Searching within data ranges that users have permission to access. For example, an order system searching for product information in orders within a specific time period.
|
||||
* Category search: Performing keyword search within specific categories. For example, a user system searching for specific user information among active users.
|
||||
|
||||
Example:
|
||||
|
||||
1. Set search parameters.
|
||||
|
||||
```sql
|
||||
-- Specify scalar filter condition brand = "GamerZone"
|
||||
SET @parm = '{
|
||||
"knn" : {
|
||||
"field": "vec",
|
||||
"k": 3,
|
||||
"query_vector": [0.1,0.5,0.3,0.7],
|
||||
"filter" : [
|
||||
{"term" : {"brand": "GamerZone"} }
|
||||
]
|
||||
}
|
||||
}';
|
||||
```
|
||||
|
||||
2. Search for all records where `vec` is similar to `[0.1,0.5,0.3,0.7]` and `brand` is `"GamerZone"`.
|
||||
|
||||
```sql
|
||||
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products_vector', @parm));
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
:::collapse{title="Return result"}
|
||||
|
||||
```shell
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products_vector', @parm)) |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [
|
||||
{
|
||||
"vec": "[0.5,0.1,0.6,0.9]",
|
||||
"tags": "best-seller,gaming-gear,rgb",
|
||||
"brand": "GamerZone",
|
||||
"price": 149.00,
|
||||
"_score": 0.59850837,
|
||||
"category": "Gaming",
|
||||
"is_on_sale": 1,
|
||||
"product_id": "prod-001",
|
||||
"description": "A responsive mechanical keyboard with customizable RGB lighting for the ultimate gaming experience.",
|
||||
"product_name": "Gamer-Pro Mechanical Keyboard",
|
||||
"release_date": "2023-07-20 00:00:00.000000",
|
||||
"stock_quantity": 100
|
||||
},
|
||||
{
|
||||
"vec": "[0.1,0.9,0.2,0]",
|
||||
"tags": "best-seller,gaming-gear,audio",
|
||||
"brand": "GamerZone",
|
||||
"price": 149.00,
|
||||
"_score": 0.55175342,
|
||||
"category": "Gaming",
|
||||
"is_on_sale": 1,
|
||||
"product_id": "prod-002",
|
||||
"description": "High-fidelity gaming headset with a noise-cancelling microphone.",
|
||||
"product_name": "Gamer-Pro Headset",
|
||||
"release_date": "2023-07-20 00:00:00.000000",
|
||||
"stock_quantity": 100
|
||||
}
|
||||
] |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Multi-vector search
|
||||
|
||||
Multi-vector search refers to searching across multiple vector indexes and returning the most similar records.
|
||||
|
||||
Example:
|
||||
|
||||
1. Set search parameters.
|
||||
```sql
|
||||
-- Specify 3-way vector queries, each query specifies the vector index field, number of results to return, and query vector
|
||||
SET @param_multi_knn = '{
|
||||
"knn" : [{
|
||||
"field": "vec1",
|
||||
"k": 5,
|
||||
"query_vector": [0.5,0.1,0.6,0.9]
|
||||
},
|
||||
{
|
||||
"field": "vec2",
|
||||
"k": 5,
|
||||
"query_vector": [0.2,0.3,0.4,0.5]
|
||||
},
|
||||
{
|
||||
"field": "vec3",
|
||||
"k": 5,
|
||||
"query_vector": [0.1,0.2,0.3,0.4]
|
||||
}
|
||||
],
|
||||
"size" : 5
|
||||
}';
|
||||
```
|
||||
|
||||
2. Execute the query and return the query results.
|
||||
|
||||
```sql
|
||||
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products_multi_vector', @param_multi_knn));
|
||||
```
|
||||
|
||||
:::collapse{title="Return result"}
|
||||
|
||||
```shell
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| json_pretty(DBMS_HYBRID_SEARCH.SEARCH('products_multi_vector', @param_multi_knn)) |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [
|
||||
{
|
||||
"vec1": "[0.5,0.1,0.6,0.9]",
|
||||
"vec2": "[0.2,0.3,0.4,0.5]",
|
||||
"vec3": "[0.1,0.2,0.3,0.4]",
|
||||
"_score": 3.0,
|
||||
"product_id": "prod-001",
|
||||
"description": "A responsive mechanical keyboard",
|
||||
"product_name": "Gamer-Pro Mechanical Keyboard"
|
||||
},
|
||||
{
|
||||
"vec1": "[0.1,0.9,0.2,0]",
|
||||
"vec2": "[0.3,0.4,0.5,0.6]",
|
||||
"vec3": "[0.2,0.3,0.4,0.5]",
|
||||
"_score": 2.0957750699999997,
|
||||
"product_id": "prod-002",
|
||||
"description": "High-fidelity gaming headset",
|
||||
"product_name": "Gamer-Pro Headset"
|
||||
},
|
||||
{
|
||||
"vec1": "[0.1,0.9,0.3,0]",
|
||||
"vec2": "[0.4,0.5,0.6,0.7]",
|
||||
"vec3": "[0.3,0.4,0.5,0.6]",
|
||||
"_score": 1.86262927,
|
||||
"product_id": "prod-003",
|
||||
"description": "A non-slip yoga mat",
|
||||
"product_name": "Eco-Friendly Yoga Mat"
|
||||
}
|
||||
] |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Full-text and vector hybrid search
|
||||
|
||||
Some use cases for full-text and vector hybrid search are as follows:
|
||||
|
||||
* Intelligent search: Comprehensive search combining keywords and semantic understanding. For example, when a user inputs `"I need a gaming keyboard"`, the system matches both the keywords `"gaming"` and `"keyboard"`, and understands the semantics of `"gaming equipment"`.
|
||||
* Document search: Supporting both exact keyword matching and semantic understanding in large document collections. For example, when searching for `"database optimization"`, it matches documents containing these words and also finds semantically related content about `"performance tuning"` and `"query optimization"`.
|
||||
* Product recommendation: E-commerce platforms support both product name search and requirement description search. For example, based on a user's description `"laptop suitable for office work"`, it matches keywords and understands the semantic requirement of `"business office"`.
|
||||
|
||||
Example:
|
||||
|
||||
1. Set search parameters.
|
||||
```sql
|
||||
SET @parm = '{
|
||||
"query": {
|
||||
"bool": {
|
||||
"should": [
|
||||
{"match": {"query": "hi hello"}},
|
||||
{"match": { "content": "oceanbase mysql" }}
|
||||
]
|
||||
}
|
||||
},
|
||||
"knn" : {
|
||||
"field": "vector",
|
||||
"k": 5,
|
||||
"query_vector": [1,2,3]
|
||||
},
|
||||
"_source" : ["query", "content", "_keyword_score", "_semantic_score"]
|
||||
}';
|
||||
```
|
||||
|
||||
2. Execute the query and return the query results.
|
||||
|
||||
```sql
|
||||
SELECT json_pretty(DBMS_HYBRID_SEARCH.SEARCH('doc_table', @parm));
|
||||
```
|
||||
|
||||
The return result is as follows:
|
||||
|
||||
:::collapse{title="Return result"}
|
||||
|
||||
```shell
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| json_pretty(dbms_hybrid_search.search('doc_table', @parm)) |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [
|
||||
{
|
||||
"query": "hello world, what is your name",
|
||||
"_score": 2.835628417884166,
|
||||
"content": "oceanbase mysql database",
|
||||
"_keyword_score": 2.5022950878841663,
|
||||
"_semantic_score": 0.33333333
|
||||
},
|
||||
{
|
||||
"query": "hello world",
|
||||
"_score": 1.7219400929592013,
|
||||
"content": "oceanbase Elasticsearch database",
|
||||
"_keyword_score": 0.7219400929592014,
|
||||
"_semantic_score": 1.0
|
||||
},
|
||||
{
|
||||
"query": "hello world, how are you",
|
||||
"_score": 1.0096539326751595,
|
||||
"content": "oceanbase oracle database",
|
||||
"_keyword_score": 0.7006369426751594,
|
||||
"_semantic_score": 0.30901699
|
||||
},
|
||||
{
|
||||
"query": "real world, how old are you",
|
||||
"_score": 0.41421356,
|
||||
"content": "redis oracle database",
|
||||
"_keyword_score": null,
|
||||
"_semantic_score": 0.41421356
|
||||
},
|
||||
{
|
||||
"query": "real world, where are you from",
|
||||
"_score": 0.30901699,
|
||||
"content": "postgres oracle database",
|
||||
"_keyword_score": null,
|
||||
"_semantic_score": 0.30901699
|
||||
}
|
||||
] |
|
||||
```
|
||||
|
||||
:::
|
||||
|
||||
### Full-text and vector RRF hybrid search
|
||||
|
||||
The result sets of full-text sub-queries and vector sub-queries use weighted fusion by default. You can configure the fusion method to RRF (Reciprocal Rank Fusion) ranking fusion through the `Rank` syntax. Some use cases are as follows:
|
||||
|
||||
* Multi-dimensional ranking: Requiring comprehensive consideration of results from multiple search dimensions. For example, in academic search systems, when searching in a paper database, both keyword matching degree and semantic relevance need to be considered.
|
||||
* Fairness requirements: Ensuring that results from different search methods are reasonably displayed. For example, on e-commerce platforms, both textual information such as product titles and descriptions, and visual information such as product images and videos need to be considered.
|
||||
* Complex queries: Complex search scenarios involving multiple query conditions. For example, in medical systems, both patient symptom descriptions and patient medical history and examination results need to be considered.
|
||||
|
||||
Example:
|
||||
|
||||
Set search parameters.
|
||||
|
||||
```sql
|
||||
SET @rrf_query_param = '{
|
||||
"query": {
|
||||
"query_string": {
|
||||
"fields": ["title", "author", "description"],
|
||||
"query": "fiction American Dream"
|
||||
}
|
||||
},
|
||||
"knn" : {
|
||||
"field": "vector_embedding",
|
||||
"k": 5,
|
||||
"query_vector": [0.1, 0.2, 0.3, 0.4]
|
||||
},
|
||||
"rank" : {
|
||||
"rrf" : {
|
||||
"rank_window_size" : 10,
|
||||
"rank_constant" : 60
|
||||
}
|
||||
}
|
||||
}';
|
||||
```
|
||||
|
||||
The RRF algorithm calculates the final relevance score by fusing the rankings of multiple sub-query result sets. The calculation formula is as follows:
|
||||
|
||||
```sql
|
||||
score = 0.0
|
||||
for q in queries:
|
||||
if d in result(q):
|
||||
score += 1.0 / ( k + rank( result(q), d ) ) # K constant is the configured rank_constant
|
||||
return score
|
||||
```
|
||||
|
||||
### Summary
|
||||
|
||||
The examples in this topic demonstrate the powerful application value of the hybrid search feature:
|
||||
|
||||
* Intelligent search upgrade: Integrating semantic understanding into traditional keyword search to provide more accurate search results that better match user intent.
|
||||
* Optimized user experience: Supporting natural language queries, simplifying operations, and improving information retrieval efficiency.
|
||||
* Empowering diverse businesses: Widely applied in scenarios such as e-commerce, content management, knowledge bases, and intelligent customer service, achieving comprehensive coverage from basic filtering to intelligent recommendations.
|
||||
* Combined technical advantages: Combining exact matching with semantic understanding to significantly improve the accuracy and comprehensiveness of search results.
|
||||
|
||||
The hybrid search feature is an ideal choice for processing massive unstructured data and building intelligent search and recommendation systems.
|
||||
|
||||
<!--## Related documentation
|
||||
|
||||
* [DBMS_HYBRID_SEARCH sub-function overview](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000004020384)-->
|
||||
@@ -0,0 +1,165 @@
|
||||
---
|
||||
|
||||
slug: /ai-function-permission
|
||||
---
|
||||
|
||||
# AI function privileges
|
||||
|
||||
This topic describes the AI function privileges, including `AI MODEL` and `ACCESS AI MODEL`, which are used for managing AI models and calling AI functions, respectively.
|
||||
|
||||
## AI MODEL
|
||||
|
||||
AI MODEL privileges are used for managing AI models. These include three specific privileges: `CREATE AI MODEL`, `ALTER AI MODEL`, and `DROP AI MODEL`.
|
||||
|
||||
### Syntax
|
||||
|
||||
The syntax for granting privileges is as follows:
|
||||
|
||||
```sql
|
||||
-- Grant the privilege to create an AI model.
|
||||
GRANT CREATE AI MODEL ON *.* TO 'username'@'host';
|
||||
|
||||
-- Grant the privilege to change an AI model.
|
||||
GRANT ALTER AI MODEL ON *.* TO 'username'@'host';
|
||||
|
||||
-- Grant the privilege to drop an AI model.
|
||||
GRANT DROP AI MODEL ON *.* TO 'username'@'host';
|
||||
|
||||
GRANT CREATE AI MODEL, ALTER AI MODEL, DROP AI MODEL ON *.* TO 'username'@'host';
|
||||
```
|
||||
|
||||
The syntax for revoking privileges is as follows:
|
||||
|
||||
```sql
|
||||
-- Revoke the privilege to create an AI model.
|
||||
REVOKE CREATE AI MODEL ON *.* FROM 'username'@'host';
|
||||
|
||||
-- Revoke the privilege to change an AI model.
|
||||
REVOKE ALTER AI MODEL ON *.* FROM 'username'@'host';
|
||||
|
||||
-- Revoke the privilege to drop an AI model.
|
||||
REVOKE DROP AI MODEL ON *.* FROM 'username'@'host';
|
||||
|
||||
-- Check the privileges.
|
||||
SHOW GRANTS FOR 'username'@'host';
|
||||
```
|
||||
|
||||
### Examples
|
||||
|
||||
1. Create a user.
|
||||
|
||||
```sql
|
||||
CREATE USER test_ai_user@'%' IDENTIFIED BY '123456';
|
||||
```
|
||||
|
||||
2. Log in as the `test_ai_user` user.
|
||||
|
||||
```sql
|
||||
obclient -h 127.0.0.1 -P 2881 -u test_ai_user@'%' -p *** -A -D test;
|
||||
```
|
||||
|
||||
3. Call the `CREATE_AI_MODEL_ENDPOINT` procedure.
|
||||
|
||||
```sql
|
||||
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
|
||||
-> 'user_ai_model_endpoint_1', '{
|
||||
'> "ai_model_name": "my_model1",
|
||||
'> "url": "https://https://api.deepseek.com",
|
||||
'> "access_key": "sk-xxxxxxxxxxxx",
|
||||
'> "request_model_name": "deepseek-chat",
|
||||
'> "provider": "deepseek"
|
||||
'> }');
|
||||
```
|
||||
|
||||
Since the user does not have the `CREATE AI MODEL` privilege, an error is returned:
|
||||
|
||||
```shell
|
||||
ERROR 42501: Access denied; you need (at least one of) the create ai model endpoint privilege(s) for this operation
|
||||
```
|
||||
|
||||
4. Grant the `CREATE AI MODEL` privilege to the `test_ai_user` user.
|
||||
|
||||
```sql
|
||||
GRANT CREATE AI MODEL ON *.* TO test_ai_user@'%';
|
||||
```
|
||||
|
||||
5. Verify the privilege.
|
||||
|
||||
```sql
|
||||
CALL DBMS_AI_SERVICE.CREATE_AI_MODEL_ENDPOINT (
|
||||
-> 'user_ai_model_endpoint_1', '{
|
||||
'> "ai_model_name": "my_model1",
|
||||
'> "url": "https://https://api.deepseek.com",
|
||||
'> "access_key": "sk-xxxxxxxxxxxx",
|
||||
'> "request_model_name": "deepseek-caht",
|
||||
'> "provider": "deepseek"
|
||||
'> }');
|
||||
```
|
||||
|
||||
This time, the statement executes successfully.
|
||||
|
||||
## ACCESS AI MODEL
|
||||
|
||||
The `ACCESS AI MODEL` privilege is used for calling AI functions, including `AI_COMPLETE`, `AI_EMBED`, `AI_RERANK`, and `AI_PROMPT`.
|
||||
|
||||
### Syntax
|
||||
|
||||
The syntax for granting this privilege is as follows:
|
||||
|
||||
```sql
|
||||
GRANT ACCESS AI MODEL ON *.* TO 'username'@'host';
|
||||
```
|
||||
|
||||
The syntax for revoking this privilege is as follows:
|
||||
|
||||
```sql
|
||||
REVOKE ACCESS AI MODEL ON *.* FROM 'username'@'host';
|
||||
```
|
||||
|
||||
### Examples
|
||||
|
||||
1. Call the `AI_COMPLETE` function.
|
||||
|
||||
```sql
|
||||
SELECT AI_COMPLETE("ob_complete","Your task is to perform sentiment analysis on the provided text and determine whether the sentiment is positive or negative.
|
||||
The text to analyze is as follows:
|
||||
<text>
|
||||
What a beautiful day!
|
||||
</text>
|
||||
Judgment criteria:
|
||||
If the text expresses a positive sentiment, output 1; if it expresses a negative sentiment, output -1. Do not output anything else.\n") AS ans;
|
||||
```
|
||||
|
||||
Since the user does not have the `ACCESS AI MODEL` privilege, an error is returned:
|
||||
|
||||
```shell
|
||||
ERROR 42501: Access denied; you need (at least one of) the access ai model endpoint privilege(s) for this operation
|
||||
```
|
||||
|
||||
2. Grant the `ACCESS AI MODEL` privilege to the `test_ai_user` user.
|
||||
|
||||
```sql
|
||||
GRANT ACCESS AI MODEL ON *.* TO test_ai_user@'%';
|
||||
```
|
||||
|
||||
3. Verify the privilege.
|
||||
|
||||
```sql
|
||||
SELECT AI_COMPLETE("ob_complete","Your task is to perform sentiment analysis on the provided text and determine whether the sentiment is positive or negative.
|
||||
The text to analyze is as follows:
|
||||
<text>
|
||||
What a beautiful day!
|
||||
</text>
|
||||
Judgment criteria:
|
||||
If the text expresses a positive sentiment, output 1; if it expresses a negative sentiment, output -1. Do not output anything else.\n") AS ans;
|
||||
```
|
||||
|
||||
This time, the statement executes successfully.
|
||||
|
||||
```sql
|
||||
+-----+
|
||||
| ans |
|
||||
+-----+
|
||||
| 1 |
|
||||
+-----+
|
||||
```
|
||||
@@ -0,0 +1,332 @@
|
||||
---
|
||||
|
||||
slug: /ai-function
|
||||
---
|
||||
|
||||
# Use cases and examples of AI functions
|
||||
|
||||
This topic describes the features of AI functions in seekdb.
|
||||
|
||||
AI functions integrate AI model capabilities directly into data processing within databases through SQL expressions. This greatly simplifies operations such as data extraction, analysis, summarization, and storage using large AI models, making it an important new feature in the fields of databases and data warehouses. seekdb provides AI model and endpoint management through the `DBMS_AI_SERVICE` package, introduces several built-in AI function expressions, and supports monitoring AI model usage through views.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before using AI functions, make sure you have the necessary privileges. For more information about the privileges, see [AI function privileges](100.ai-function-permission.md).
|
||||
|
||||
## Considerations
|
||||
|
||||
Hybrid search relies on the model management and embedding capabilities of the AI function service. Before deleting an AI model, check whether it is referenced by hybrid search to avoid potential issues.
|
||||
|
||||
## AI model management
|
||||
|
||||
The `DBMS_AI_SERVICE` package provides the ability to manage AI models and endpoints. It supports the following operations:
|
||||
|
||||
| **Operation** | **Description** |
|
||||
| ------ | ------ |
|
||||
| CREATE_AI_MODEL | Creates an AI model object. |
|
||||
| DROP_AI_MODEL | Drops an AI model object. |
|
||||
| CREATE_AI_MODEL_ENDPOINT | Creates an AI model endpoint object. |
|
||||
| ALTER_AI_MODEL_ENDPOINT | Modifies an AI model endpoint object. |
|
||||
| DROP_AI_MODEL_ENDPOINT | Drops an AI model endpoint object. |
|
||||
|
||||
By using this system package, you can directly manage AI models and endpoints within seekdb, without relying on external services.
|
||||
|
||||
## Monitor AI model usage
|
||||
|
||||
seekdb allows you to query and monitor information about AI models and their usage through the following views:
|
||||
|
||||
* CDB/DBA_OB_AI_MODELS: Query information about AI models.
|
||||
* CDB/DBA_OB_AI_MODEL_ENDPOINTS: Monitor the calls of AI models.
|
||||
|
||||
## AI function expressions
|
||||
|
||||
seekdb supports the following AI function expressions, allowing you to call AI models directly within seekdb using SQL statements and greatly simplifying the process:
|
||||
|
||||
| Function | Description |
|
||||
|-----|------|
|
||||
|`AI_COMPLETE`|Calls a specified text generation large language model (LLM) to process prompts and data, and then parses the results.|
|
||||
| `AI_PROMPT` |Constructs and formats prompts. Supports dynamic data insertion.|
|
||||
|`AI_EMBED`|Calls an embedding model to convert text data into vector data.|
|
||||
|`AI_RERANK`|Calls a reranking model to sort text based on prompts by similarity.|
|
||||
|
||||
:::info
|
||||
When using AI function expressions, make sure you have registered the AI models and endpoint information in the database.
|
||||
:::
|
||||
|
||||
### AI_COMPLETE and AI_PROMPT
|
||||
|
||||
The `AI_COMPLETE` function specifies a registered large language model (LLM) for text generation using the `model_key`, processes the user-provided prompt and data, and returns the text generated by the model. Users can customize the prompt and the format of the data from the database through the `prompt` parameter. This approach not only enables flexible processing of textual data, but also allows for batch processing directly within the database, effectively avoiding the overhead of repeatedly transferring data between the database and the language model.
|
||||
|
||||
In many AI application scenarios, prompts are often highly structured and require dynamic injection of specific data. Manually concatenating prompts and input content using functions like `CONCAT` each time is not only costly in terms of development, but also prone to formatting errors. To support prompt reuse and dynamic combination of prompts and data, seekdb provides the `AI_PROMPT` function. `AI_PROMPT` upgrades prompts from "static text" to a "reusable, parameterizable" function template format, which can be used directly in place of the `prompt` parameter within `AI_COMPLETE`. This greatly simplifies the process of constructing prompts, improving both development efficiency and accuracy.
|
||||
|
||||
#### AI_PROMPT function
|
||||
|
||||
The `AI_PROMPT` function is used to construct and format prompts, supporting dynamic data insertion.
|
||||
|
||||
##### Syntax
|
||||
|
||||
The syntax for the `AI_PROMPT` function is as follows:
|
||||
|
||||
```sql
|
||||
AI_PROMPT('template', expr0 [ , expr1, ... ]);
|
||||
```
|
||||
|
||||
Parameters:
|
||||
|
||||
| Parameter | Description | Type | Nullable |
|
||||
|-----------|-------------|------|----------|
|
||||
| template | The prompt template entered by the user. | VARCHAR(max_length) | No |
|
||||
| expr | The data entered by the user. | VARCHAR(max_length) | No |
|
||||
|
||||
Both the `template` and `expr` parameters are required and cannot be null. The `expr` parameter only supports the `VARCHAR` type and does not support the `JSON` type.
|
||||
|
||||
Return value:
|
||||
|
||||
* JSON, the formatted prompt string.
|
||||
|
||||
##### Examples
|
||||
|
||||
The `AI_PROMPT` function organizes the template string and dynamic data into JSON format:
|
||||
* The first parameter (the template string `template`) is placed in the `template` field of the returned JSON.
|
||||
* Subsequent parameters (data values `expr0`, `expr1`, ...) are placed in the `args` array of the returned JSON.
|
||||
* Placeholders in the template such as `{0}`, `{1}`, etc., correspond by index to the data in the `args` array and will be automatically replaced when used in the `AI_COMPLETE` function.
|
||||
|
||||
For example:
|
||||
|
||||
```sql
|
||||
SELECT AI_PROMPT('Recommend {0} of the most popular {1} to me.', 'ten', 'mobile phones');
|
||||
```
|
||||
|
||||
Return result:
|
||||
|
||||
```json
|
||||
{
|
||||
"template": "Recommend {0} of the most popular {1} to me.",
|
||||
"args": ["ten", "mobile phones"]
|
||||
}
|
||||
```
|
||||
|
||||
Based on the previous example, using the `AI_PROMPT` function within the `AI_COMPLETE` function:
|
||||
|
||||
```sql
|
||||
SELECT AI_COMPLETE("ob_complete", AI_PROMPT('Recommend {0} of the most popular {1} to me. just output name in json array format', 'two', 'mobile phones')) AS ans;
|
||||
```
|
||||
|
||||
Return result:
|
||||
|
||||
```json
|
||||
+--------------------------------------------------+
|
||||
| ans |
|
||||
+--------------------------------------------------+
|
||||
| ["iPhone 15 Pro Max","Samsung Galaxy S24 Ultra"] |
|
||||
+--------------------------------------------------+
|
||||
```
|
||||
|
||||
#### AI_COMPLETE function
|
||||
|
||||
#### Syntax
|
||||
|
||||
The syntax for the `AI_COMPLETE` function is as follows:
|
||||
|
||||
```sql
|
||||
AI_COMPLETE(model_key, prompt[, parameters])
|
||||
-- If you use the AI_PROMPT function, replace the prompt parameter with the AI_PROMPT function. See the AI_PROMPT function example.
|
||||
AI_COMPLETE(model_key, AI_PROMPT(prompt_template, data))
|
||||
```
|
||||
|
||||
Parameters:
|
||||
|
||||
| Parameter | Description | Type | Nullable |
|
||||
|------|------|------|----------|
|
||||
| model_key | The model registered in the database. | VARCHAR(128) | No |
|
||||
| prompt | The prompt provided by the user. | VARCHAR/TEXT(LONGTEXT) | No |
|
||||
| parameters | Optional configuration for the API, such as `temperature`, `top_p`, and `max_tokens`. These options vary by vendor and are added directly to the message body. Typically, you can use the default settings without specifying these options. | JSON | Yes |
|
||||
|
||||
Both `model_key` and `prompt` are required. If either is `NULL`, the function will return an error.
|
||||
|
||||
Return value:
|
||||
|
||||
* text: The text generated by the LLM based on the prompt.
|
||||
|
||||
##### Examples
|
||||
|
||||
1. Sentiment analysis example
|
||||
|
||||
```sql
|
||||
SELECT AI_COMPLETE("ob_complete","Your task is to perform sentiment analysis on the provided text and determine whether the sentiment is positive or negative.
|
||||
The text to analyze is as follows:
|
||||
<text>
|
||||
What a beautiful day!
|
||||
</text>
|
||||
Judgment criteria:
|
||||
If the text expresses a positive sentiment, output 1; if it expresses a negative sentiment, output -1. Do not output anything else.\n") AS ans;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```sql
|
||||
+-----+
|
||||
| ans |
|
||||
+-----+
|
||||
| 1 |
|
||||
+-----+
|
||||
```
|
||||
|
||||
2. Translation example
|
||||
|
||||
```sql
|
||||
CREATE TABLE comments (
|
||||
id INT AUTO_INCREMENT PRIMARY KEY,
|
||||
content TEXT
|
||||
);
|
||||
|
||||
INSERT INTO comments (content) VALUES ('hello world!');
|
||||
|
||||
-- Use the concat expression to replace the processed data with column names from the database table, enabling batch processing of database data without copying data to and from the LLM.
|
||||
SELECT AI_COMPLETE("ob_complete",
|
||||
concat("You are a professional translator. Please translate the following English text into Chinese. The text to be translated is:<text>",
|
||||
content,
|
||||
"</text>")) AS ans FROM comments;
|
||||
```
|
||||
Result:
|
||||
|
||||
```sql
|
||||
+-------------+
|
||||
| ans |
|
||||
+-------------+
|
||||
| 你好,世界! |
|
||||
+-------------+
|
||||
```
|
||||
|
||||
3. Classification example
|
||||
|
||||
```sql
|
||||
SELECT AI_COMPLETE("ob_complete","You are a classification expert. You will receive various issue texts and need to categorize them into the appropriate department. The department list is [\"Hardware\",\"Software\",\"Other\"]. The text to analyze is as follows:
|
||||
<text>
|
||||
The screen quality is terrible.
|
||||
</text>") AS res;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```sql
|
||||
+--------+
|
||||
| res |
|
||||
+--------+
|
||||
| Hardware |
|
||||
+--------+
|
||||
```
|
||||
|
||||
### AI_EMBED
|
||||
|
||||
The `AI_EMBED` function uses the `model_key` parameter to specify a registered embedding model, which converts your text data into vector representations. If the model supports multiple dimensions, you can use the `dim` parameter to specify the output dimension.
|
||||
|
||||
#### Use AI_EMBED
|
||||
|
||||
Syntax:
|
||||
|
||||
```sql
|
||||
AI_EMBED(model_key, input, [dim])
|
||||
```
|
||||
|
||||
Parameters:
|
||||
|
||||
| Parameter | Description | Type | Nullable |
|
||||
|------|------|------|----------|
|
||||
| model_key | The embedding model registered in your database. | VARCHAR(128) | No |
|
||||
| input | The text you want to convert into a vector. | VARCHAR | No |
|
||||
| dim | Specifies the output dimension of the vector. Some model providers support configuring this value. | INT64 | Yes |
|
||||
|
||||
Both `model_key` and `input` are required. If either is `NULL`, the function will return an error.
|
||||
|
||||
Return value:
|
||||
|
||||
* A string in vector format, that is, the embedding model’s vector representation of your text.
|
||||
|
||||
#### Examples
|
||||
|
||||
1. Embed single row of data.
|
||||
|
||||
```sql
|
||||
SELECT AI_EMBED("ob_embed","Hello world") AS embedding;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```sql
|
||||
+----------------+
|
||||
| embedding |
|
||||
+----------------+
|
||||
| [0.1, 0.2, 0.3]|
|
||||
+----------------+
|
||||
```
|
||||
|
||||
2. Embed table columns.
|
||||
|
||||
```sql
|
||||
CREATE TABLE comments (
|
||||
id INT AUTO_INCREMENT PRIMARY KEY,
|
||||
content TEXT
|
||||
);
|
||||
|
||||
INSERT INTO comments (content) VALUES ('hello world!');
|
||||
|
||||
SELECT AI_EMBED("ob_embed",content) AS embedding FROM comments;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```sql
|
||||
+----------------+
|
||||
| embedding |
|
||||
+----------------+
|
||||
| [0.1, 0.2, 0.3]|
|
||||
+----------------+
|
||||
```
|
||||
|
||||
### AI_RERANK
|
||||
|
||||
The `AI_RERANK` function uses the `model_key` parameter to specify a registered reranking model. It organizes your query and document list according to the provider's rules, sends them to the specified model, and returns the sorted results. This function is suitable for reranking scenarios in Retrieval-Augmented Generation (RAG).
|
||||
|
||||
#### Use AI_RERANK
|
||||
|
||||
Syntax:
|
||||
|
||||
```sql
|
||||
AI_RERANK(model_key, query, documents[, document_key])
|
||||
```
|
||||
|
||||
Parameters:
|
||||
|
||||
| Parameter | Description | Type | Nullable |
|
||||
|------|------|------|----------|
|
||||
| model_key | The reranking model registered in your database. | VARCHAR(128) | No |
|
||||
| query | The search text you want to use. | VARCHAR(1024) | No |
|
||||
| documents | The list of documents to be ranked. | JSON array, for example, `'["apple", "banana"]'` | No |
|
||||
|
||||
All of the parameters `model_key` and `input` are required. If either is `NULL`, the function will return an error.
|
||||
|
||||
Return value:
|
||||
|
||||
* A JSON array containing the documents and their relevance scores, sorted in descending order by relevance.
|
||||
|
||||
#### Examples
|
||||
|
||||
```sql
|
||||
SELECT AI_RERANK("ob_rerank","Apple",'["apple","banana","fruit","vegetable"]');
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```sql
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| ai_rerank("ob_rerank","Apple",'["apple","banana","fruit","vegetable"]') |
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| [{"index": 0, "document": {"text": "apple"}, "relevance_score": 0.9912109375}, {"index": 1, "document": {"text": "banana"}, "relevance_score": 0.0033512115478515625}, {"index": 2, "document": {"text": "fruit"}, "relevance_score": 0.0003669261932373047}, {"index": 3, "document": {"text": "vegetable"}, "relevance_score": 0.00001996755599975586}] |
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Vector embedding technology](../100.vector-search/150.vector-embedding-technology.md)
|
||||
* [Privilege types in MySQL-compatible mode](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974758)
|
||||
@@ -0,0 +1,248 @@
|
||||
---
|
||||
|
||||
slug: /oceanbase-mcp-server-and-ai-tool-integration-guide
|
||||
---
|
||||
|
||||
# OceanBase MCP Server
|
||||
|
||||
## Background information
|
||||
|
||||
AI tools are evolving rapidly, from graphical solutions like Cursor, Windsurf, and Trae to command-line options such as Claude Code, Gemini CLI, and Qwen Code. Empowered by Agent-based frameworks, these tools are remarkably capable. However, a key limitation remains: AI tools cannot directly access databases, leaving a gap between data and analysis. The MCP protocol bridges this gap. By leveraging the MCP protocol, OceanBase MCP Server enables AI tools to interact directly with databases and retrieve data seamlessly.
|
||||
|
||||
Traditionally, data analysis tasks—such as user analytics, product analysis, order tracking, and user behavior analysis—require developers to build backend systems for data retrieval and frontend interfaces for data visualization. Even with BI tools, some familiarity with SQL is often necessary. While data can be displayed, understanding the underlying logic or making business decisions based on that data still depends on the expertise of data analysts.
|
||||
|
||||
The combination of AI tools, MCP, and large language models (LLMs) is transforming the way data analysis is performed. Analysts no longer need to rely on developers or have SQL knowledge. They can simply describe their requirements to AI tools and instantly receive the results they need—complete with attractive charts and initial data insights.
|
||||
|
||||
## Functional architecture
|
||||
|
||||
### Core toolkit
|
||||
|
||||
OceanBase MCP Server offers standardized interfaces that enable AI tools to interact directly with the database:
|
||||
|
||||
| Tool | Description |
|
||||
|-----------------------------|-------------|
|
||||
| `execute_sql` | Executes any SQL statement (such as `SELECT`, `INSERT`, `UPDATE`, `DELETE`, `DDL`). |
|
||||
| `get_ob_ash_report` | Gets seekdb Active Session History (ASH) reports for performance diagnostics. |
|
||||
| `get_current_time` | Returns the current time of the seekdb instance. |
|
||||
| `oceanbase_text_search` | Performs full-text searches across seekdb database tables. |
|
||||
| `oceanbase_vector_search` | Executes vector similarity searches within seekdb database tables. |
|
||||
| `oceanbase_hybrid_search` | Conducts hybrid searches, combining relational filtering with vector search. |
|
||||
| `ob_memory_query` | Retrieves historical conversation records from the AI memory system using semantic search. (AI Memory System Tool) |
|
||||
| `ob_memory_insert` | Automatically captures and stores important conversation content to build a knowledge base. (AI Memory System Tool) |
|
||||
| `ob_memory_delete` | Deletes outdated or redundant conversation memories. (AI Memory System Tool) |
|
||||
| `ob_memory_update` | Updates or evolves memory content based on new information. (AI Memory System Tool) |
|
||||
|
||||
### Resource endpoints
|
||||
|
||||
AI tools can directly access these resource endpoints via the MCP protocol:
|
||||
|
||||
| Resource path | Description |
|
||||
|--------------------------------|-------------|
|
||||
| `oceanbase://tables` | Lists all tables in the database. |
|
||||
| `oceanbase://sample/{table}` | Retrieves sample data (first 100 rows) from the specified table. `{table}` can be dynamically replaced with the actual table name. |
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed Cursor or another tool that supports the MCP protocol (such as Windsurf or Qwen Code).
|
||||
* You have deployed seekdb.
|
||||
|
||||
* For deployment details, see [Deploy seekdb](../../400.guides/400.deploy/100.prepare-servers.md).
|
||||
|
||||
* You have a Python environment set up (version 3.10 to 3.12).
|
||||
|
||||
* Download the Python installer from the [official Python website](https://www.python.org/downloads/).
|
||||
|
||||
## Procedure
|
||||
|
||||
### Step 1: Obtain database connection information
|
||||
|
||||
Contact the database administrator or deployment team to get the required database connection string. For example:
|
||||
|
||||
```sql
|
||||
obclient -h$host -P$port -u$user_name -p$password -D$database_name
|
||||
```
|
||||
|
||||
**Parameters:**
|
||||
|
||||
* `$host`: The IP address for connecting to seekdb.
|
||||
* `$port`: The port number for connecting to seekdb. Default is `2881`.
|
||||
* `$database_name`: The name of the database to access.
|
||||
* `$user_name`: The account for connecting to the instance. Default is `root`.
|
||||
* `$password`: The account password. Default is empty.
|
||||
|
||||
**Here is an example:**
|
||||
|
||||
```shell
|
||||
obclient -hxxx.xxx.xxx.xxx -P2881 -uroot -p****** -Dtest
|
||||
```
|
||||
|
||||
### Step 2: Install Python dependencies
|
||||
|
||||
#### Environment setup
|
||||
|
||||
1. Install the uv package manager.
|
||||
|
||||
* On macOS or Linux, run:
|
||||
|
||||
```shell
|
||||
curl -LsSf https://astral.sh/uv/install.sh | sh
|
||||
```
|
||||
|
||||
* On Windows, run:
|
||||
|
||||
```shell
|
||||
irm https://astral.sh/uv/install.ps1 | iex
|
||||
```
|
||||
|
||||
* Alternatively, you can install uv using pip:
|
||||
|
||||
```shell
|
||||
pip install uv
|
||||
```
|
||||
|
||||
2. Verify the installation:
|
||||
|
||||
```shell
|
||||
uv --version
|
||||
```
|
||||
|
||||
#### Install OceanBase MCP Server
|
||||
|
||||
1. Choose a directory and create a virtual environment:
|
||||
|
||||
```shell
|
||||
uv venv
|
||||
```
|
||||
|
||||
2. Activate the virtual environment:
|
||||
|
||||
```shell
|
||||
source .venv/bin/activate
|
||||
```
|
||||
|
||||
3. Install OceanBase MCP Server:
|
||||
|
||||
```shell
|
||||
uv pip install oceanbase-mcp
|
||||
```
|
||||
|
||||
### Step 3: Configure the MCP Server environment
|
||||
|
||||
1. Create a `.env` file with your database connection info:
|
||||
|
||||
```shell
|
||||
cat > .env <<EOF
|
||||
OB_HOST=127.0.0.1
|
||||
OB_PORT=2881
|
||||
OB_USER=root
|
||||
OB_PASSWORD=your_password
|
||||
OB_DATABASE=test
|
||||
EOF
|
||||
```
|
||||
|
||||
2. Start the MCP Server:
|
||||
|
||||
```shell
|
||||
uv run oceanbase_mcp_server \
|
||||
--transport sse \ # Supports stdio/streamable-http/sse modes
|
||||
--host 0.0.0.0 \ # Allows external access, use 127.0.0.1 for local access only
|
||||
--port 8000 # Custom port (update later configs if changed)
|
||||
```
|
||||
|
||||
### Step 4: Connect Cursor to the MCP Server
|
||||
|
||||
1. Use Cursor V2.0.64 as an example. Click the **Open Settings** icon in the upper right corner, select **Tools & MCP**, and click **New MCP Server**.
|
||||
|
||||

|
||||
|
||||
2. Edit the `mcp.json` configuration file:
|
||||
|
||||
```shell
|
||||
{
|
||||
"mcpServers": {
|
||||
"ob-sse": {
|
||||
"autoApprove": [],
|
||||
"disabled": false, # Must be set to false to enable the service
|
||||
"timeout": 60,
|
||||
"type": "sse",
|
||||
"url": "http://127.0.0.1:8000/sse" # Make sure this matches the port you set in Step 3
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
3. Verify the connection.
|
||||
|
||||
After saving the configuration, return to the **Tools & MCP** page. Then you will find the newly added MCP server.
|
||||
|
||||
4. Once added, Cursor will automatically use MCP tools when you ask questions in the Chat window.
|
||||
|
||||
|
||||
|
||||
## Quick start examples
|
||||
|
||||
Once you set up seekdb and the MCP Server, you can quickly try out data analysis capabilities. The following examples use the [Online Retail Dataset](https://www.kaggle.com/datasets/ulrikthygepedersen/online-retail-dataset) and Cursor to demonstrate how AI tools can seamlessly work with the OceanBase MCP Server for common analytics tasks.
|
||||
|
||||
### Customer distribution analysis
|
||||
|
||||
1. Instruction input:
|
||||
|
||||
```
|
||||
Please analyze the customer data and show the distribution of customers by country.
|
||||
```
|
||||
|
||||
2. Cursor execution process:
|
||||
|
||||
1. Cursor calls `execute_sql` to run an aggregation query:
|
||||
|
||||
```sql
|
||||
SELECT Country,
|
||||
COUNT(DISTINCT CustomerID) AS customer_count
|
||||
FROM dataanalysis_english.invoice_items
|
||||
WHERE CustomerID IS NOT NULL
|
||||
AND Country IS NOT NULL
|
||||
GROUP BY Country
|
||||
ORDER BY customer_count DESC;
|
||||
```
|
||||
|
||||
2. Cursor automatically generates a structured analysis result.
|
||||
|
||||
|
||||
|
||||
3. Further request:
|
||||
|
||||
```
|
||||
Please convert the above results into a table.
|
||||
```
|
||||
|
||||
4. Output:
|
||||
|
||||
|
||||
|
||||
### Best-selling products analysis
|
||||
|
||||
1. Instruction input:
|
||||
|
||||
```
|
||||
Find the most popular products and show their sales performance.
|
||||
```
|
||||
|
||||
2. Output:
|
||||
|
||||
Cursor summarizes the most popular products with performance insights and displays them in a ranked table or bar chart.
|
||||
|
||||
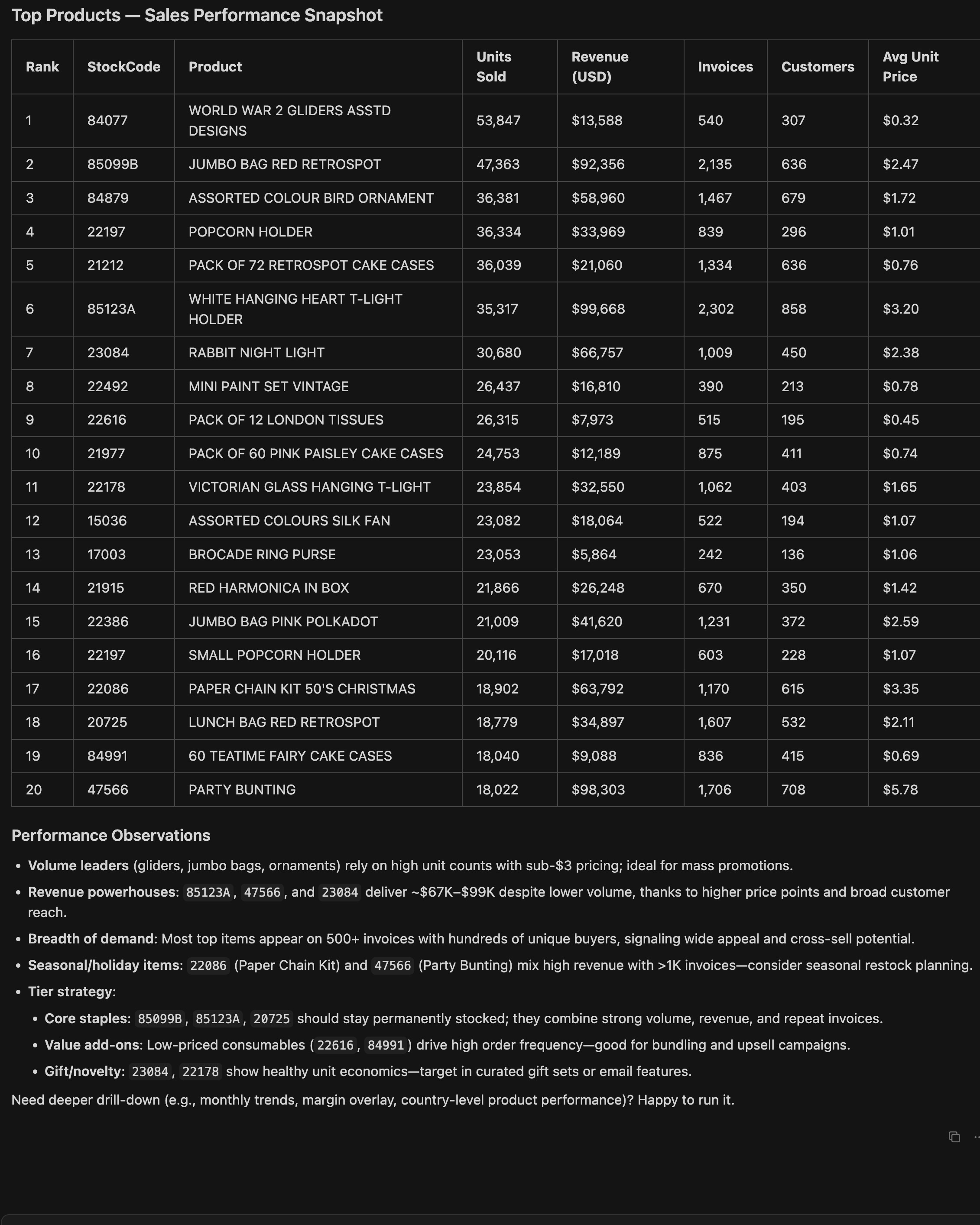
|
||||
|
||||
### Sales trend over time
|
||||
|
||||
1. Instruction input:
|
||||
|
||||
```
|
||||
Analyze monthly sales trends and identify peak periods.
|
||||
```
|
||||
|
||||
2. Output:
|
||||
|
||||
Cursor generates a line chart showing monthly sales trends with peak periods highlighted (for example, November and December for holiday shopping).
|
||||
|
||||
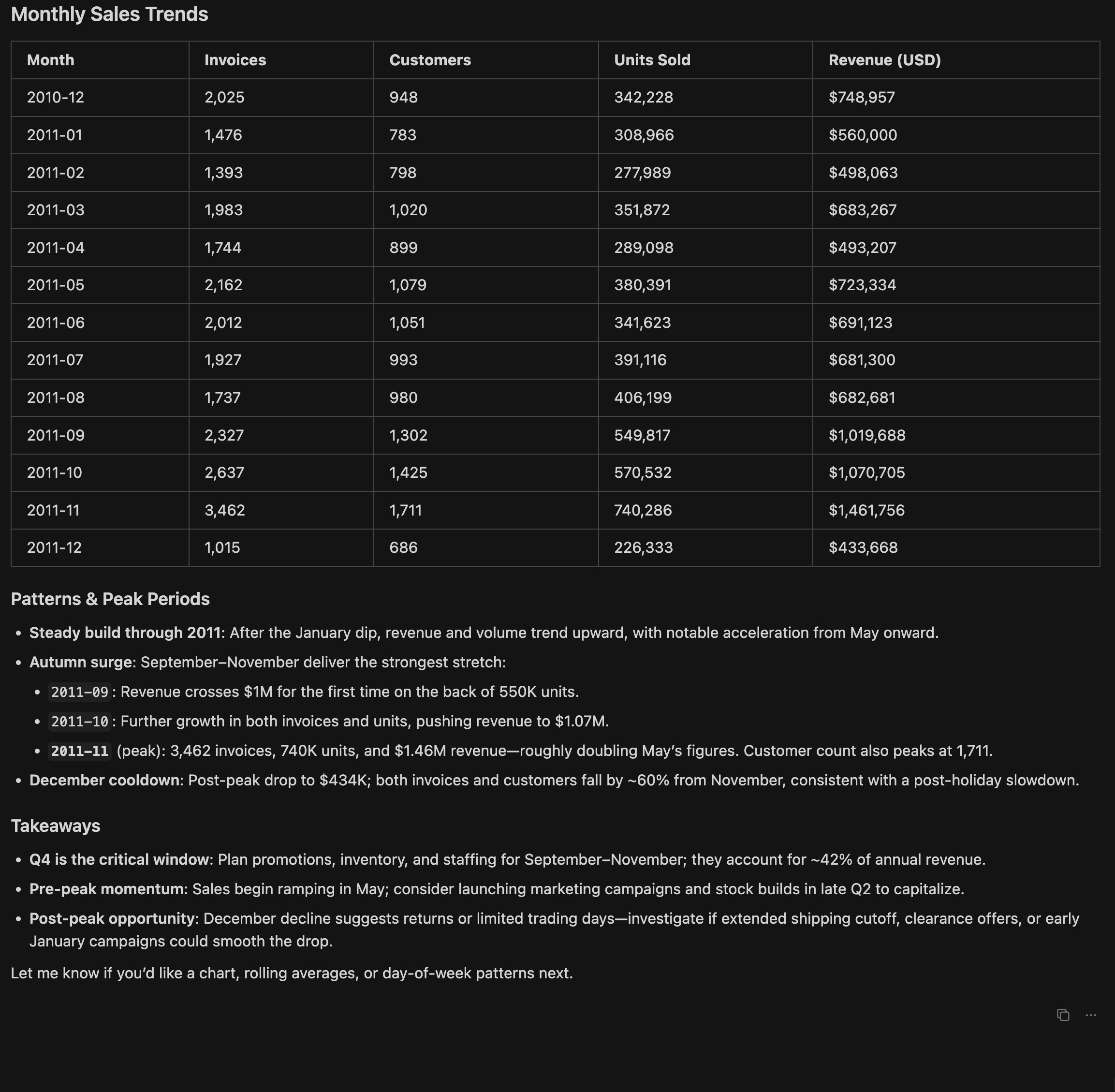
|
||||
@@ -0,0 +1,20 @@
|
||||
---
|
||||
|
||||
slug: /json-formatted-data-types
|
||||
---
|
||||
|
||||
# Overview of JSON data types
|
||||
|
||||
seekdb supports the JavaScript Object Notation (JSON) data type in compliance with the RFC 7159 standard. You can use it to store semi-structured JSON data and access or modify the data within JSON documents.
|
||||
|
||||
The JSON data type offers the following advantages:
|
||||
|
||||
* **Automatic validation**: JSON documents stored in JSON columns are automatically validated. Invalid documents will trigger an error.
|
||||
|
||||
* **Optimized storage format**: JSON documents stored in JSON columns are converted into an optimized format that enables fast reading and access. When the server reads a JSON value stored in binary format, it doesn't need to parse the value from text.
|
||||
|
||||
* **Semi-structured encoding**: This feature further reduces storage costs by splitting a JSON document into multiple sub-columns, with each sub-column encoded individually. This improves compression rates and reduces the storage space required for JSON data. For more information, see [Create a JSON value](200.create-a-json-value.md) and [Semi-structured encoding](600.json-semi-struct.md).
|
||||
|
||||
## References
|
||||
|
||||
* [Overview of JSON functions](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974794)
|
||||
@@ -0,0 +1,257 @@
|
||||
---
|
||||
|
||||
slug: /create-a-json-value
|
||||
---
|
||||
|
||||
# Create a JSON value
|
||||
|
||||
A JSON value must be one of the following: objects (JSON objects), arrays, strings, numbers, boolean values (true/false), or the null value. Note that false, true, and the null value must be in lowercase.
|
||||
|
||||
## JSON text structure
|
||||
|
||||
A JSON text structure includes characters, strings, numbers, and three literal names. Whitespace characters (spaces, horizontal tabs, line feeds, and carriage returns) are allowed before or after any structural character.
|
||||
|
||||
```sql
|
||||
begin-array = [ left square bracket
|
||||
|
||||
begin-object = { left curly bracket
|
||||
|
||||
end-array = ] right square bracket
|
||||
|
||||
end-object = } right curly bracket
|
||||
|
||||
name-separator = : colon
|
||||
|
||||
value-separator = , comma
|
||||
```
|
||||
|
||||
### Objects
|
||||
|
||||
An object is represented by a pair of curly brackets containing zero or more name/value pairs (also called members). Names within an object must be unique. Each name is a string followed by a colon that separates the name from its value. Multiple name/value pairs are separated by commas.
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
{ "NAME": "SAM", "Height": 175, "Weight": 100, "Registered" : false}
|
||||
```
|
||||
|
||||
### Arrays
|
||||
|
||||
An array is represented by square brackets containing zero or more values (also called elements). Array elements are separated by commas, and values in an array do not need to be of the same type.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
["abc", 10, null, true, false]
|
||||
```
|
||||
|
||||
### Numbers
|
||||
|
||||
Numbers use decimal format and contain an integer component that may optionally be prefixed with a minus sign (-). This can be followed by a fractional part and/or an exponent part. Leading zeros are not allowed. The fractional part consists of a decimal point followed by one or more digits. The exponent part begins with an uppercase or lowercase letter E, optionally followed by a plus (+) or minus (-) sign and one or more digits.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
[100, 0, -100, 100.11, -12.11, 10.22e2, -10.22e2]
|
||||
```
|
||||
|
||||
### Strings
|
||||
|
||||
A string begins and ends with quotation marks ("). All Unicode characters can be placed within the quotation marks, except characters that must be escaped (including quotation marks, backslashes, and control characters).
|
||||
|
||||
JSON text must be encoded in UTF-8, UTF-16, or UTF-32. The default encoding is UTF-8.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```sql
|
||||
{"Url": "http://www.example.com/image/481989943"}
|
||||
```
|
||||
|
||||
## Create JSON values
|
||||
|
||||
seekdb supports the following DDL operations on JSON types:
|
||||
|
||||
* Create tables with JSON columns.
|
||||
|
||||
* Add or drop JSON columns.
|
||||
|
||||
* Create indexes on generated columns based on JSON columns.
|
||||
|
||||
* Enable semi-structured encoding when creating tables.
|
||||
|
||||
* Enable semi-structured encoding on existing tables.
|
||||
|
||||
### Limitations
|
||||
|
||||
You can create multiple JSON columns in each table, with the following limitations:
|
||||
|
||||
* JSON columns cannot be used as `PRIMARY KEY`, `FOREIGN KEY`, or `UNIQUE KEY`, but you can add `NOT NULL` or `CHECK` constraints.
|
||||
|
||||
* JSON columns cannot have default values.
|
||||
|
||||
* JSON columns cannot be used as partitioning keys.
|
||||
|
||||
* The length of JSON data cannot exceed the length of `LONGTEXT`, and the maximum depth of each JSON object or array is 99.
|
||||
|
||||
### Examples
|
||||
|
||||
#### Create or modify JSON columns
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE tbl1 (id INT PRIMARY KEY, docs JSON NOT NULL, docs1 JSON);
|
||||
Query OK, 0 rows affected
|
||||
|
||||
obclient> ALTER TABLE tbl1 MODIFY docs JSON CHECK(docs <'{"a" : 100}');
|
||||
Query OK, 0 rows affected
|
||||
|
||||
obclient> CREATE TABLE json_tab(
|
||||
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT COMMENT 'Primary key',
|
||||
json_info JSON COMMENT 'JSON data',
|
||||
json_id INT GENERATED ALWAYS AS (json_info -> '$.id') COMMENT 'Virtual field from JSON data',
|
||||
json_name VARCHAR(5) GENERATED ALWAYS AS (json_info -> '$.NAME'),
|
||||
index json_info_id_idx (json_id)
|
||||
)COMMENT 'Example JSON table';
|
||||
Query OK, 0 rows affected
|
||||
|
||||
obclient> ALTER TABLE json_tab ADD COLUMN json_info1 JSON;
|
||||
Query OK, 0 rows affected
|
||||
|
||||
obclient> ALTER TABLE json_tab ADD INDEX (json_name);
|
||||
Query OK, 0 rows affected
|
||||
|
||||
obclient> ALTER TABLE json_tab drop COLUMN json_info1;
|
||||
Query OK, 0 rows affected
|
||||
```
|
||||
|
||||
#### Create an index on a specific key using a generated column
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE jn ( c JSON, g INT GENERATED ALWAYS AS (c->"$.id"));
|
||||
Query OK, 0 rows affected
|
||||
|
||||
obclient> CREATE INDEX idx1 ON jn(g);
|
||||
Query OK, 0 rows affected
|
||||
Records: 0 Duplicates: 0 Warnings: 0
|
||||
|
||||
obclient> INSERT INTO jn (c) VALUES
|
||||
('{"id": "1", "name": "Fred"}'), ('{"id": "2", "name": "Wilma"}'),
|
||||
('{"id": "3", "name": "Barney"}'), ('{"id": "4", "name": "Betty"}');
|
||||
Query OK, 4 rows affected
|
||||
Records: 4 Duplicates: 0 Warnings: 0
|
||||
|
||||
obclient> SELECT c->>"$.name" AS name FROM jn WHERE g <= 2;
|
||||
+-------+
|
||||
| name |
|
||||
+-------+
|
||||
| Fred |
|
||||
| Wilma |
|
||||
+-------+
|
||||
2 rows in set
|
||||
|
||||
obclient> EXPLAIN SELECT c->>"$.name" AS name FROM jn WHERE g <= 2\G
|
||||
*************************** 1. row ***************************
|
||||
Query Plan: =========================================
|
||||
|ID|OPERATOR |NAME |EST. ROWS|COST|
|
||||
-----------------------------------------
|
||||
|0 |TABLE SCAN|jemp(idx1)|2 |92 |
|
||||
=========================================
|
||||
|
||||
Outputs & filters:
|
||||
-------------------------------------
|
||||
0 - output([JSON_UNQUOTE(JSON_EXTRACT(jemp.c, '$.name'))]), filter(nil),
|
||||
access([jemp.c]), partitions(p0)
|
||||
|
||||
1 row in set
|
||||
```
|
||||
|
||||
#### Use semi-structured encoding
|
||||
|
||||
seekdb supports enabling semi-structured encoding when creating tables, primarily controlled by the table-level parameter `SEMISTRUCT_PROPERTIES`. You must also set `ROW_FORMAT=COMPRESSED` for the table, otherwise an error will occur:
|
||||
|
||||
* When `SEMISTRUCT_PROPERTIES=(encoding_type=encoding)`, the table is considered a semi-structured table, meaning all JSON columns in the table will have semi-structured encoding enabled.
|
||||
* When `SEMISTRUCT_PROPERTIES=(encoding_type=none)`, the table is considered a structured table.
|
||||
* You can also set the frequency threshold using the `freq_threshold` parameter.
|
||||
* Currently, `encoding_type` and `freq_threshold` can only be modified using online DDL statements, not offline DDL statements.
|
||||
|
||||
1. Enable semi-structured encoding.
|
||||
|
||||
:::tip
|
||||
If you enable semi-structured encoding, make sure that the parameter <a href="https://en.oceanbase.com/docs/common-oceanbase-database-10000000001971939">micro_block_merge_verify_level</a> is set to the default value <code>2</code>. Do not disable micro-block major compaction verification.
|
||||
:::
|
||||
|
||||
:::tab
|
||||
tab Example: Enable semi-structured encoding during table creation
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1( j json)
|
||||
ROW_FORMAT=COMPRESSED
|
||||
SEMISTRUCT_PROPERTIES=(encoding_type=encoding, freq_threshold=50);
|
||||
```
|
||||
|
||||
For more information about the syntax, see [CREATE TABLE](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974140).
|
||||
|
||||
tab Example: Enable semi-structured encoding for existing table
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1(j json);
|
||||
ALTER TABLE t1 SET ROW_FORMAT=COMPRESSED SEMISTRUCT_PROPERTIES = (encoding_type=encoding, freq_threshold=50);
|
||||
```
|
||||
|
||||
For more information about the syntax, see [ALTER TABLE](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974126).
|
||||
|
||||
Some modification limitations:
|
||||
|
||||
* If semi-structured encoding is not enabled, modifying the frequent column threshold will not report an error but will have no effect.
|
||||
* The `freq_threshold` parameter cannot be modified during direct load operations or when the table is locked.
|
||||
* Modifying one sub-parameter does not affect the others.
|
||||
:::
|
||||
|
||||
2. Disable semi-structured encoding.
|
||||
|
||||
When `SEMISTRUCT_PROPERTIES` is set to `(encoding_type=none)`, semi-structured encoding is disabled. This operation does not affect existing data and only applies to data written afterward. Here is an example of disabling semi-structured encoding:
|
||||
|
||||
```sql
|
||||
ALTER TABLE t1 SET ROW_FORMAT=COMPRESSED SEMISTRUCT_PROPERTIES = (encoding_type=none);
|
||||
```
|
||||
|
||||
3. Query semi-structured encoding configuration.
|
||||
|
||||
Use the `SHOW CREATE TABLE` statement to query the semi-structured encoding configuration. Here is an example statement:
|
||||
|
||||
```sql
|
||||
SHOW CREATE TABLE t1;
|
||||
```
|
||||
|
||||
The result is as follows:
|
||||
|
||||
```shell
|
||||
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Table | Create Table |
|
||||
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| t1 | CREATE TABLE `t1` (
|
||||
`j` json DEFAULT NULL
|
||||
) ORGANIZATION INDEX DEFAULT CHARSET = utf8mb4 ROW_FORMAT = COMPRESSED COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE ENABLE_MACRO_BLOCK_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 SEMISTRUCT_PROPERTIES=(ENCODING_TYPE=ENCODING, FREQ_THRESHOLD=50) |
|
||||
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
When `SEMISTRUCT_PROPERTIES=(encoding_type=encoding)` is specified, the query displays this parameter, indicating that semi-structured encoding is enabled.
|
||||
|
||||
Using semi-structured encoding can improve the performance of conditional filtering queries with the [JSON_VALUE() function](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001975890). Based on JSON semi-structured encoding technology, seekdb optimizes the performance of `JSON_VALUE` expression conditional filtering query scenarios. Since JSON data is split into sub-columns, the system can filter directly based on the encoded sub-column data without reconstructing the complete JSON structure, significantly improving query efficiency.
|
||||
|
||||
Here is an example query:
|
||||
|
||||
```sql
|
||||
-- Query rows where the value of the name field is 'Devin'
|
||||
SELECT * FROM t WHERE JSON_VALUE(j_doc, '$.name' RETURNING CHAR) = 'Devin';
|
||||
```
|
||||
|
||||
Character set considerations:
|
||||
|
||||
- seekdb uses `utf8_bin` encoding for JSON.
|
||||
|
||||
- To ensure string whitebox filtering works properly, we recommend the following settings:
|
||||
|
||||
```sql
|
||||
SET @@collation_server = 'utf8mb4_bin';
|
||||
SET @@collation_connection='utf8mb4_bin';
|
||||
```
|
||||
@@ -0,0 +1,174 @@
|
||||
---
|
||||
|
||||
slug: /querying-and-modifying-json-values
|
||||
---
|
||||
|
||||
# Query and modify JSON values
|
||||
|
||||
seekdb supports querying and referencing JSON values. Using path expressions, you can extract or modify specific portions of a JSON document.
|
||||
|
||||
## Reference JSON values
|
||||
|
||||
seekdb provides two methods for querying and referencing JSON values:
|
||||
|
||||
* Use the `->` operator to return a key's value with double quotes in JSON data.
|
||||
|
||||
* Use the `->>` operator to return a key's value without double quotes in JSON data.
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
obclient> SELECT c->"$.name" AS name FROM jn WHERE g <= 2;
|
||||
+---------+
|
||||
| name |
|
||||
+---------+
|
||||
| "Fred" |
|
||||
| "Wilma" |
|
||||
+---------+
|
||||
2 rows in set
|
||||
|
||||
obclient> SELECT c->>"$.name" AS name FROM jn WHERE g <= 2;
|
||||
+-------+
|
||||
| name |
|
||||
+-------+
|
||||
| Fred |
|
||||
| Wilma |
|
||||
+-------+
|
||||
2 rows in set
|
||||
|
||||
obclient> SELECT JSON_UNQUOTE(c->'$.name') AS name
|
||||
FROM jn WHERE g <= 2;
|
||||
+-------+
|
||||
| name |
|
||||
+-------+
|
||||
| Fred |
|
||||
| Wilma |
|
||||
+-------+
|
||||
2 rows in set
|
||||
```
|
||||
|
||||
Because JSON documents are hierarchical, JSON functions use path expressions to extract or modify portions of a document and to specify where in the document the operation should occur.
|
||||
|
||||
seekdb uses a path syntax consisting of a leading `$` character followed by a selector to represent the JSON document being accessed. The selector types are as follows:
|
||||
|
||||
* The `.` symbol represents the key name to access. Unquoted names are not valid in path expressions (for example, names containing spaces), so key names must be enclosed in double quotes.
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
obclient> SELECT JSON_EXTRACT('{"id": 14, "name": "Aztalan"}', '$.name');
|
||||
+---------------------------------------------------------+
|
||||
| JSON_EXTRACT('{"id": 14, "name": "Aztalan"}', '$.name') |
|
||||
+---------------------------------------------------------+
|
||||
| "Aztalan" |
|
||||
+---------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
* The `[N]` symbol is placed after the path of the selected array and represents the value at position N in the array, where N is a non-negative integer. Array positions are zero-indexed. If `path` does not select an array value, then `path[0]` evaluates to the same value as `path`.
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
obclient> SELECT JSON_SET('"x"', '$[0]', 'a');
|
||||
+------------------------------+
|
||||
| JSON_SET('"x"', '$[0]', 'a') |
|
||||
+------------------------------+
|
||||
| "a" |
|
||||
+------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
* The `[M to N]` symbol specifies a subset or range of array values, starting from position M and ending at position N.
|
||||
|
||||
Example:
|
||||
|
||||
```sql
|
||||
obclient> SELECT JSON_EXTRACT('[1, 2, 3, 4, 5]', '$[1 to 3]');
|
||||
+----------------------------------------------+
|
||||
| JSON_EXTRACT('[1, 2, 3, 4, 5]', '$[1 to 3]') |
|
||||
+----------------------------------------------+
|
||||
| [2, 3, 4] |
|
||||
+----------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
* Path expressions can also include `*` or `**` wildcard characters:
|
||||
|
||||
* `.[*]` represents the values of all members in a JSON object.
|
||||
|
||||
* `[*]` represents the values of all elements in a JSON array.
|
||||
|
||||
* `prefix**suffix` represents all paths that begin with the specified prefix and end with the specified suffix. The prefix is optional, but the suffix is required. Using `**` or `***` alone to match arbitrary paths is not allowed.
|
||||
|
||||
:::info
|
||||
Paths that do not exist in the document (evaluating to non-existent data) evaluate to <code>NULL</code>.
|
||||
:::
|
||||
|
||||
## Modify JSON values
|
||||
|
||||
seekdb also supports modifying complete JSON values using DML statements, and using the JSON_SET(), JSON_REPLACE(), or JSON_REMOVE() functions in `UPDATE` statements to modify partial JSON values.
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
// Insert complete data.
|
||||
INSERT INTO json_tab(json_info) VALUES ('[1, {"a": "b"}, [2, "qwe"]]');
|
||||
|
||||
// Insert partial data.
|
||||
UPDATE json_tab SET json_info=JSON_ARRAY_APPEND(json_info, '$', 2) WHERE id=1;
|
||||
|
||||
// Update complete data.
|
||||
UPDATE json_tab SET json_info='[1, {"a": "b"}]';
|
||||
|
||||
// Update partial data.
|
||||
UPDATE json_tab SET json_info=JSON_REPLACE(json_info, '$[2]', 'aaa') WHERE id=1;
|
||||
|
||||
// Delete data.
|
||||
DELETE FROM json_tab WHERE id=1;
|
||||
|
||||
// Update partial data using a function.
|
||||
UPDATE json_tab SET json_info=JSON_REMOVE(json_info, '$[2]') WHERE id=1;
|
||||
```
|
||||
|
||||
## JSON path syntax
|
||||
|
||||
A path consists of a scope and one or more path segments. For paths used in JSON functions, the scope is the document being searched or otherwise operated on, represented by the leading `$` character.
|
||||
|
||||
Path segments are separated by periods (.). Array elements are represented by `[N]`, where N is a non-negative integer. Key names must be either double-quoted strings or valid ECMAScript identifiers.
|
||||
|
||||
Path expressions (like JSON text) should be encoded using the ascii, utf8, or utf8mb4 character set. Other character encodings are implicitly converted to utf8mb4.
|
||||
|
||||
The complete syntax is as follows:
|
||||
|
||||
```sql
|
||||
pathExpression: // Path expression
|
||||
scope[(pathLeg)*] // Scope is represented by the leading $ character
|
||||
|
||||
pathLeg:
|
||||
member | arrayLocation | doubleAsterisk
|
||||
|
||||
member:
|
||||
period ( keyName | asterisk )
|
||||
|
||||
arrayLocation:
|
||||
leftBracket ( nonNegativeInteger | asterisk ) rightBracket
|
||||
|
||||
keyName:
|
||||
ESIdentifier | doubleQuotedString
|
||||
|
||||
doubleAsterisk:
|
||||
'**'
|
||||
|
||||
period:
|
||||
'.'
|
||||
|
||||
asterisk:
|
||||
'*'
|
||||
|
||||
leftBracket:
|
||||
'['
|
||||
|
||||
rightBracket:
|
||||
']'
|
||||
```
|
||||
@@ -0,0 +1,54 @@
|
||||
---
|
||||
|
||||
slug: /json-formatted-data-type-conversion
|
||||
---
|
||||
|
||||
# Convert JSON data types
|
||||
|
||||
seekdb supports the CAST function for converting between JSON and other data types.
|
||||
|
||||
The following table describes the conversion rules for JSON data types.
|
||||
|
||||
| Other data types | CAST(other_type AS JSON) | CAST(JSON AS other_type) |
|
||||
|-------------------------------------|---------------------------------------------|----------------------------------------------------------|
|
||||
| JSON | No change. | No change. |
|
||||
| UTF-8 character types (including utf8mb4, utf8, and ascii) | The characters are converted to JSON values and validated. | The data is serialized into utf8mb4 strings. |
|
||||
| Other character sets | First converted to utf8mb4 encoding, then processed as UTF-8 character type. | First serialized into utf8mb4-encoded strings, then converted to the corresponding character set. |
|
||||
| NULL | An empty JSON value is returned. | Not applicable. |
|
||||
| Other types | Only scalar values are converted to JSON values containing that single value. | If the JSON value contains only one scalar value that matches the target type, it is converted to the corresponding type; otherwise, NULL is returned and a warning is issued. |
|
||||
|
||||
:::info
|
||||
<code>other_type</code> specifies a data type other than JSON.
|
||||
:::
|
||||
|
||||
Here are some conversion examples:
|
||||
|
||||
```sql
|
||||
obclient> SELECT CAST("123" AS JSON);
|
||||
+---------------------+
|
||||
| CAST("123" AS JSON) |
|
||||
+---------------------+
|
||||
| 123 |
|
||||
+---------------------+
|
||||
1 row in set
|
||||
|
||||
obclient> SELECT CAST(null AS JSON);
|
||||
+--------------------+
|
||||
| CAST(null AS JSON) |
|
||||
+--------------------+
|
||||
| NULL |
|
||||
+--------------------+
|
||||
1 row in set
|
||||
|
||||
CREATE TABLE tj1 (c1 JSON,c2 VARCHAR(20));
|
||||
INSERT INTO tj1 VALUES ('{"id": 17, "color": "red"}','apple'),('{"id": 18, "color": "yellow"}', 'banana'),('{"id": 16, "color": "orange"}','orange');
|
||||
obclient> SELECT * FROM tj1 ORDER BY CAST(JSON_EXTRACT(c1, '$.id') AS UNSIGNED);
|
||||
+-------------------------------+--------+
|
||||
| c1 | c2 |
|
||||
+-------------------------------+--------+
|
||||
| {"id": 16, "color": "orange"} | orange |
|
||||
| {"id": 17, "color": "red"} | apple |
|
||||
| {"id": 18, "color": "yellow"} | banana |
|
||||
+-------------------------------+--------+
|
||||
3 rows in set
|
||||
```
|
||||
@@ -0,0 +1,328 @@
|
||||
---
|
||||
|
||||
slug: /json-partial-update
|
||||
---
|
||||
|
||||
# Partial JSON data updates
|
||||
|
||||
seekdb supports partial JSON data updates (JSON Partial Update). When only specific fields in a JSON document need to be modified, this feature allows you to update only the changed portions without having to update the entire JSON document.
|
||||
|
||||
## Limitations
|
||||
|
||||
## Enable or disable JSON Partial Update
|
||||
|
||||
The JSON Partial Update feature in seekdb is disabled by default. It is controlled by the system variable `log_row_value_options`. For more information, see [log_row_value_options](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001972193).
|
||||
|
||||
**Here are some examples:**
|
||||
|
||||
* Enable the JSON Partial Update feature.
|
||||
|
||||
* Session level:
|
||||
|
||||
```sql
|
||||
SET log_row_value_options="partial_json";
|
||||
```
|
||||
|
||||
* Global level:
|
||||
|
||||
```sql
|
||||
SET GLOBAL log_row_value_options="partial_json";
|
||||
```
|
||||
|
||||
* Disable the JSON Partial Update feature.
|
||||
|
||||
* Session level:
|
||||
|
||||
```sql
|
||||
SET log_row_value_options="";
|
||||
```
|
||||
|
||||
* Global level:
|
||||
|
||||
```sql
|
||||
SET GLOBAL log_row_value_options="";
|
||||
```
|
||||
|
||||
* Query the value of `log_row_value_options`.
|
||||
|
||||
```sql
|
||||
SHOW VARIABLES LIKE 'log_row_value_options';
|
||||
```
|
||||
|
||||
The result is as follows:
|
||||
|
||||
```sql
|
||||
+-----------------------+-------+
|
||||
| Variable_name | Value |
|
||||
+-----------------------+-------+
|
||||
| log_row_value_options | |
|
||||
+-----------------------+-------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## JSON expressions for partial updates
|
||||
|
||||
In addition to the JSON Partial Update feature switch `log_row_value_options`, you must use specific expressions to update JSON documents to trigger JSON Partial Update.
|
||||
|
||||
The following JSON expressions in seekdb currently support partial updates:
|
||||
|
||||
* json_set or json_replace: updates the value of a JSON field.
|
||||
* json_remove: deletes a JSON field.
|
||||
|
||||
:::tip
|
||||
<ol><li>Ensure that the left operand of the <code>SET</code> assignment clause and the first parameter of the JSON expression are the same and both are JSON columns in the table. For example, in <code>j = json_replace(j, '$.name', 'ab')</code>, the parameter on the left side of the equals sign and the first parameter of the JSON expression <code>json_replace</code> on the right side are both <code>j</code>.</li><li>JSON Partial Update is only triggered when the current JSON column data is stored as <code>outrow</code>. Whether data is stored as <code>outrow</code> or <code>inrow</code> is controlled by the <code>lob_inrow_threshold</code> parameter when creating the table. <code>lob_inrow_threshold</code> is used to configure the <code>INROW</code> threshold. When the LOB data size exceeds this threshold, it is stored as <code>OUTROW</code> in the LOB Meta table. The default value is 4 KB.</li></ol>
|
||||
:::
|
||||
|
||||
**Examples:**
|
||||
|
||||
1. Create a table named `json_test`.
|
||||
|
||||
```sql
|
||||
CREATE TABLE json_test(pk INT PRIMARY KEY, j JSON);
|
||||
```
|
||||
|
||||
2. Insert data.
|
||||
|
||||
```sql
|
||||
INSERT INTO json_test VALUES(1, CONCAT('{"name": "John", "content": "', repeat('x',8), '"}'));
|
||||
```
|
||||
|
||||
The result is as follows:
|
||||
|
||||
```shell
|
||||
Query OK, 1 row affected
|
||||
```
|
||||
|
||||
3. Query the data in the JSON column `j`.
|
||||
|
||||
```sql
|
||||
SELECT j FROM json_test;
|
||||
```
|
||||
|
||||
The result is as follows:
|
||||
|
||||
```shell
|
||||
+-----------------------------------------+
|
||||
| j |
|
||||
+-----------------------------------------+
|
||||
| {"name": "John", "content": "xxxxxxxx"} |
|
||||
+-----------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
4. Use `json_repalce` to update the value of the `name` field in the JSON column.
|
||||
|
||||
```sql
|
||||
UPDATE json_test SET j = json_replace(j, '$.name', 'ab') WHERE pk = 1;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
Query OK, 1 row affected
|
||||
Rows matched: 1 Changed: 1 Warnings: 0
|
||||
```
|
||||
|
||||
5. Query the modified data in JSON column `j`.
|
||||
|
||||
```sql
|
||||
SELECT j FROM json_test;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
+---------------------------------------+
|
||||
| j |
|
||||
+---------------------------------------+
|
||||
| {"name": "ab", "content": "xxxxxxxx"} |
|
||||
+---------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
6. Use `json_set` to update the value of the `name` field in the JSON column.
|
||||
|
||||
```sql
|
||||
UPDATE json_test SET j = json_set(j, '$.name', 'cd') WHERE pk = 1;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
Query OK, 1 row affected
|
||||
Rows matched: 1 Changed: 1 Warnings: 0
|
||||
```
|
||||
|
||||
7. Query the modified data in JSON column `j`.
|
||||
|
||||
```sql
|
||||
SELECT j FROM json_test;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
+---------------------------------------+
|
||||
| j |
|
||||
+---------------------------------------+
|
||||
| {"name": "cd", "content": "xxxxxxxx"} |
|
||||
+---------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
8. Use `json_remove` to delete the `name` field value in the JSON column.
|
||||
|
||||
```sql
|
||||
UPDATE json_test SET j = json_remove(j, '$.name') WHERE pk = 1;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
Query OK, 1 row affected
|
||||
Rows matched: 1 Changed: 1 Warnings: 0
|
||||
```
|
||||
|
||||
9. Query the modified data in JSON column `j`.
|
||||
|
||||
```sql
|
||||
SELECT j FROM json_test;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
+-------------------------+
|
||||
| j |
|
||||
+-------------------------+
|
||||
| {"content": "xxxxxxxx"} |
|
||||
+-------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## Granularity of updates
|
||||
|
||||
JSON data in seekdb is stored based on LOB storage, and LOBs in seekdb are stored in chunks at the underlying level. Therefore, the minimum data amount for each partial update is one LOB chunk. The smaller the LOB chunk, the smaller the amount of data written. A DDL syntax is provided to set the LOB chunk size, which can be specified when creating a column.
|
||||
|
||||
**Example:**
|
||||
|
||||
```sql
|
||||
CREATE TABLE json_test(pk INT PRIMARY KEY, j JSON CHUNK '4k');
|
||||
```
|
||||
|
||||
The chunk size cannot be infinitely small, as too small a size will affect the performance of `SELECT`, `INSERT`, and `DELETE` operations. It is generally recommended to set it based on the average field size of JSON documents. If most fields are very small, you can set it to 1K. To optimize LOB type reads, seekdb stores data smaller than 4K directly as `INROW`, in which case partial update will not be performed. Partial Update is mainly intended to improve the performance of updating large documents; for small documents, full updates actually perform better.
|
||||
|
||||
## Rebuild
|
||||
|
||||
JSON Partial Update does not impose restrictions on the data length before and after updating a JSON column. When the length of the new value is less than or equal to the length of the old value, the data at the original location is directly replaced with the new data. When the length of the new value is greater than the length of the old value, the new data is appended at the end. seekdb sets a threshold: when the length of the appended data exceeds 30% of the original data length, a rebuild is triggered. In this case, Partial Update is not performed; instead, a full overwrite is performed.
|
||||
|
||||
You can use the `JSON_STORAGE_SIZE` expression to get the actual storage length of JSON data, and `JSON_STORAGE_FREE` to get the additional storage overhead.
|
||||
|
||||
**Example:**
|
||||
|
||||
1. Enable JSON Partial Update.
|
||||
|
||||
```sql
|
||||
SET log_row_value_options = "partial_json";
|
||||
```
|
||||
|
||||
2. Create a test table named `json_test`.
|
||||
|
||||
```sql
|
||||
CREATE TABLE json_test(pk INT PRIMARY KEY, j JSON CHUNK '1K');
|
||||
```
|
||||
|
||||
3. Insert a row of data into the `json_test` table.
|
||||
|
||||
```sql
|
||||
INSERT INTO json_test VALUES(10 , json_object('name', 'zero', 'age', 100, 'position', 'software engineer', 'profile', repeat('x', 4096), 'like', json_array('a', 'b', 'c'), 'tags', json_array('sql boy', 'football', 'summer', 1), 'money' , json_object('RMB', 10000, 'Dollers', 20000, 'BTC', 100), 'nickname', 'noone'));
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
Query OK, 1 row affected
|
||||
```
|
||||
|
||||
4. Use `JSON_STORAGE_SIZE` to query the storage size of the JSON column (actual occupied storage space) and `JSON_STORAGE_FREE` to estimate the storage space that can be freed from the JSON column.
|
||||
|
||||
```sql
|
||||
SELECT JSON_STORAGE_SIZE(j), JSON_STORAGE_FREE(j) FROM json_test WHERE pk = 10;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
+----------------------+----------------------+
|
||||
| JSON_STORAGE_SIZE(j) | JSON_STORAGE_FREE(j) |
|
||||
+----------------------+----------------------+
|
||||
| 4335 | 0 |
|
||||
+----------------------+----------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
Since no partial update has been performed, the value of `JSON_STORAGE_FREE` is 0.
|
||||
|
||||
5. Use `json_replace` to update the value of the `position` field in the JSON column, where the length of the new value is less than the length of the old value.
|
||||
|
||||
```sql
|
||||
UPDATE json_test SET j = json_replace(j, '$.position', 'software enginee') WHERE pk = 10;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
Query OK, 1 row affected
|
||||
Rows matched: 1 Changed: 1 Warnings: 0
|
||||
```
|
||||
|
||||
6. Again, use `JSON_STORAGE_SIZE` to query the storage size of the JSON column and `JSON_STORAGE_FREE` to estimate the storage space that can be freed from the JSON column.
|
||||
|
||||
```sql
|
||||
SELECT JSON_STORAGE_SIZE(j), JSON_STORAGE_FREE(j) FROM json_test WHERE pk = 10;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
+----------------------+----------------------+
|
||||
| JSON_STORAGE_SIZE(j) | JSON_STORAGE_FREE(j) |
|
||||
+----------------------+----------------------+
|
||||
| 4335 | 1 |
|
||||
+----------------------+----------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
After the JSON column data is updated, since the new data is one byte less than the old data, the `JSON_STORAGE_FREE` result is 1.
|
||||
|
||||
7. Use `json_replace` to update the value of the `position` field in the JSON column, where the length of the new value is greater than the length of the old value.
|
||||
|
||||
```sql
|
||||
UPDATE json_test SET j = json_replace(j, '$.position', 'software engineer') WHERE pk = 10;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
Query OK, 1 row affected
|
||||
Rows matched: 1 Changed: 1 Warnings: 0
|
||||
```
|
||||
|
||||
8. Use `JSON_STORAGE_SIZE` again to query the JSON column storage size, and `JSON_STORAGE_FREE` to estimate the storage space that can be freed from the JSON column.
|
||||
|
||||
```sql
|
||||
SELECT JSON_STORAGE_SIZE(j), JSON_STORAGE_FREE(j) FROM json_test WHERE pk = 10;
|
||||
```
|
||||
|
||||
Result:
|
||||
|
||||
```shell
|
||||
+----------------------+----------------------+
|
||||
| JSON_STORAGE_SIZE(j) | JSON_STORAGE_FREE(j) |
|
||||
+----------------------+----------------------+
|
||||
| 4355 | 19 |
|
||||
+----------------------+----------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
After appending new data to the JSON column, the length of `JSON_STORAGE_FREE` is 19, indicating that 19 bytes can be freed after a rebuild.
|
||||
@@ -0,0 +1,124 @@
|
||||
---
|
||||
|
||||
slug: /json-semi-struct
|
||||
---
|
||||
|
||||
# Semi-structured encoding
|
||||
|
||||
This topic describes the semi-structured encoding feature supported by seekdb.
|
||||
|
||||
seekdb supports enabling semi-structured encoding when creating tables, primarily controlled by the table-level parameter `SEMISTRUCT_PROPERTIES`. You must also set `ROW_FORMAT=COMPRESSED` for the table, otherwise an error will occur.
|
||||
|
||||
## Considerations
|
||||
|
||||
* When `SEMISTRUCT_PROPERTIES=(encoding_type=encoding)`, the table is considered a semi-structured table, meaning all JSON columns in the table will have semi-structured encoding enabled.
|
||||
* When `SEMISTRUCT_PROPERTIES=(encoding_type=none)`, the table is considered a structured table.
|
||||
* You can also set the frequency threshold using the `freq_threshold` parameter. When semi-structured encoding is enabled, the system analyzes the frequency of each path in the JSON data and stores paths with frequencies exceeding the specified threshold as independent subcolumns, known as frequent columns. For example, if you have a user table where the JSON field stores user information and 90% of users have the `name` and `age` fields, the system will automatically extract `name` and `age` as independent frequent columns. During queries, these columns are accessed directly without parsing the entire JSON, thereby improving query performance.
|
||||
* Currently, `encoding_type` and `freq_threshold` can only be modified using online DDL statements, not offline DDL statements.
|
||||
|
||||
## Data format
|
||||
|
||||
JSON data is split and stored as structured columns in a specific format. The columns split from JSON columns are called subcolumns. Subcolumns can be categorized into different types, including sparse columns and frequent columns.
|
||||
|
||||
* Sparse columns: Subcolumns that exist in some JSON documents but not in others, with an occurrence frequency lower than the threshold specified by the table-level parameter `freq_threshold`.
|
||||
* Frequent columns: Subcolumns that appear in JSON data with a frequency higher than the threshold specified by the table-level parameter `freq_threshold`. These subcolumns are stored as independent columns to improve filtering query performance.
|
||||
|
||||
For example:
|
||||
|
||||
```sql
|
||||
{"id": 1001, "name": "n1", "nickname": "nn1"}
|
||||
{"id": 1002, "name": "n2", "nickname": "nn2"}
|
||||
{"id": 1003, "name": "n3", "nickname": "nn3"}
|
||||
{"id": 1004, "name": "n4", "nickname": "nn4"}
|
||||
{"id": 1005, "name": "n5"}
|
||||
```
|
||||
|
||||
In this example, `id` and `name` are fields that exist in every JSON document with an occurrence frequency of 100%, while `nickname` exists in only four JSON documents with an occurrence frequency of 80%.
|
||||
|
||||
If `freq_threshold` is set to 100%, then `nickname` will be inferred as a sparse column, while `id` and `name` will be inferred as frequent columns. If set to 80%, then `nickname`, `id`, and `name` will all be inferred as frequent columns.
|
||||
|
||||
## Examples
|
||||
|
||||
1. Enable semi-structured encoding.
|
||||
|
||||
:::tip
|
||||
If you enable semi-structured encoding, make sure that the parameter <a href="https://en.oceanbase.com/docs/common-oceanbase-database-10000000001971939">micro_block_merge_verify_level</a> is set to the default value <code>2</code>. Do not disable micro-block major compaction verification.
|
||||
:::
|
||||
|
||||
:::tab
|
||||
tab Example: Enable semi-structured encoding during table creation
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1( j json)
|
||||
ROW_FORMAT=COMPRESSED
|
||||
SEMISTRUCT_PROPERTIES=(encoding_type=encoding, freq_threshold=50);
|
||||
```
|
||||
|
||||
For more information about the syntax, see [CREATE TABLE](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974140).
|
||||
|
||||
tab Example: Enable semi-structured encoding for existing table
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1(j json);
|
||||
ALTER TABLE t1 SET ROW_FORMAT=COMPRESSED SEMISTRUCT_PROPERTIES = (encoding_type=encoding, freq_threshold=50);
|
||||
```
|
||||
|
||||
For more information about the syntax, see [ALTER TABLE](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974126).
|
||||
|
||||
Some modification limitations:
|
||||
|
||||
* If semi-structured encoding is not enabled, modifying the frequent column threshold will not report an error but will have no effect.
|
||||
* The `freq_threshold` parameter cannot be modified during direct load operations or when the table is locked.
|
||||
* Modifying one sub-parameter does not affect the others.
|
||||
:::
|
||||
|
||||
2. Disable semi-structured encoding.
|
||||
|
||||
When `SEMISTRUCT_PROPERTIES` is set to `(encoding_type=none)`, semi-structured encoding is disabled. This operation does not affect existing data and only applies to data written afterward. Here is an example of disabling semi-structured encoding:
|
||||
|
||||
```sql
|
||||
ALTER TABLE t1 SET ROW_FORMAT=COMPRESSED SEMISTRUCT_PROPERTIES = (encoding_type=none);
|
||||
```
|
||||
|
||||
3. Query semi-structured encoding configuration.
|
||||
|
||||
Use the `SHOW CREATE TABLE` statement to query the semi-structured encoding configuration. Here is an example statement:
|
||||
|
||||
```sql
|
||||
SHOW CREATE TABLE t1;
|
||||
```
|
||||
|
||||
The result is as follows:
|
||||
|
||||
```shell
|
||||
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| Table | Create Table |
|
||||
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| t1 | CREATE TABLE `t1` (
|
||||
`j` json DEFAULT NULL
|
||||
) ORGANIZATION INDEX DEFAULT CHARSET = utf8mb4 ROW_FORMAT = COMPRESSED COMPRESSION = 'zstd_1.3.8' REPLICA_NUM = 1 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE ENABLE_MACRO_BLOCK_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 0 SEMISTRUCT_PROPERTIES=(ENCODING_TYPE=ENCODING, FREQ_THRESHOLD=50) |
|
||||
+-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
When `SEMISTRUCT_PROPERTIES=(encoding_type=encoding)` is specified, the query displays this parameter, indicating that semi-structured encoding is enabled.
|
||||
|
||||
Using semi-structured encoding can improve the performance of conditional filtering queries with the [JSON_VALUE() function](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001975890). Based on JSON semi-structured encoding technology, seekdb optimizes the performance of `JSON_VALUE` expression conditional filtering query scenarios. Since JSON data is split into sub-columns, the system can filter directly based on the encoded sub-column data without reconstructing the complete JSON structure, significantly improving query efficiency.
|
||||
|
||||
Here is an example query:
|
||||
|
||||
```sql
|
||||
-- Query rows where the value of the name field is 'Devin'
|
||||
SELECT * FROM t WHERE JSON_VALUE(j_doc, '$.name' RETURNING CHAR) = 'Devin';
|
||||
```
|
||||
|
||||
Character set considerations:
|
||||
|
||||
- seekdb uses `utf8_bin` encoding for JSON.
|
||||
|
||||
- To ensure string whitebox filtering works properly, we recommend the following settings:
|
||||
|
||||
```sql
|
||||
SET @@collation_server = 'utf8mb4_bin';
|
||||
SET @@collation_connection='utf8mb4_bin';
|
||||
```
|
||||
@@ -0,0 +1,26 @@
|
||||
---
|
||||
|
||||
slug: /spatial-data-type-overview
|
||||
---
|
||||
|
||||
# Overview of spatial data types
|
||||
|
||||
The Geographic Information System (GIS) feature of seekdb includes the following spatial data types:
|
||||
|
||||
* `GEOMETRY`
|
||||
|
||||
* `POINT`
|
||||
|
||||
* `LINESTRING`
|
||||
|
||||
* `POLYGON`
|
||||
|
||||
* `MULTIPOINT`
|
||||
|
||||
* `MULTILINESTRING`
|
||||
|
||||
* `MULTIPOLYGON`
|
||||
|
||||
* `GEOMETRYCOLLECTION`
|
||||
|
||||
Among these, `POINT`, `LINESTRING`, and `POLYGON` are the three most fundamental types, used to store individual spatial data. They respectively extend into three collection types: `MULTIPOINT`, `MULTILINESTRING`, and `MULTIPOLYGON`, which are used to store collections of spatial data but can only represent collections of their respective specified base types. `GEOMETRY` is an abstract type that can represent any base type, and `GEOMETRYCOLLECTION` can be a collection of any `GEOMETRY` types.
|
||||
@@ -0,0 +1,39 @@
|
||||
---
|
||||
|
||||
slug: /spacial-reference-system
|
||||
---
|
||||
|
||||
# Spatial reference systems
|
||||
|
||||
A spatial reference system (SRS) for spatial data is a coordinate-based system for defining geographic locations. The current version of seekdb only supports the default SRS provided by the system.
|
||||
|
||||
Spatial reference systems generally include the following types:
|
||||
|
||||
* Projected SRS: A projected SRS is a projection of the Earth onto a plane, essentially a flat map. The coordinate system on this plane is a Cartesian coordinate system that uses units of length (meters, feet, etc.) rather than longitude and latitude.
|
||||
|
||||
* Geographic SRS. A geographic SRS is a non-projected SRS that represents longitude-latitude (or latitude-longitude) coordinates on an ellipsoid, expressed in angular units.
|
||||
|
||||
Additionally, there is an infinitely flat Cartesian plane represented by `SRID 0`, whose axes have no assigned units. Unlike a projected SRS, it is an abstract plane with no geographic reference and does not necessarily represent the Earth. `SRID 0` is the default `SRID` for spatial data.
|
||||
|
||||
SRS content can be obtained through the `INFORMATION_SCHEMA ST_SPATIAL_REFERENCE_SYSTEMS` table, as shown in the following example:
|
||||
|
||||
```sql
|
||||
obclient> SELECT * FROM INFORMATION_SCHEMA.ST_SPATIAL_REFERENCE_SYSTEMS
|
||||
WHERE SRS_ID = 4326\G
|
||||
*************************** 1. row ***************************
|
||||
SRS_NAME: WGS 84
|
||||
SRS_ID: 4326
|
||||
ORGANIZATION: EPSG
|
||||
ORGANIZATION_COORDSYS_ID: 4326
|
||||
DEFINITION: GEOGCS["WGS 84",DATUM["World Geodetic System 1984",SPHEROID["WGS 84",6378137,298.257223563,AUTHORITY["EPSG","7030"]],AUTHORITY["EPSG","6326"]],PRIMEM["Greenwich",0,AUTHORITY["EPSG","8901"]],UNIT["degree",0.017453292519943278,AUTHORITY["EPSG","9122"]],AXIS["Lat",NORTH],AXIS["Lon",EAST],AUTHORITY["EPSG","4326"]]
|
||||
DESCRIPTION: NULL
|
||||
1 row in set
|
||||
```
|
||||
|
||||
The above example describes the SRS used by GPS systems, with the name (SRS_NAME) WGS 84 and ID (SRS_ID) 4326.
|
||||
|
||||
The SRS definition in the `DEFINITION` column is a `WKT` value. WKT is defined based on Extended Backus Naur Form (EBNF). WKT can be used both as a data format (referred to as WKT-Data in this document) and for SRS definitions in GIS.
|
||||
|
||||
The `SRS_ID` value represents the same type of value as the `SRID` of a geometry value, or is passed as an `SRID` parameter to spatial functions. `SRID 0` (unitless Cartesian plane) is a special, valid spatial reference system ID that can be used for any spatial data calculations that depend on `SRID` values.
|
||||
|
||||
For calculations involving multiple geometry values, all values must have the same SRID; otherwise, an error will occur.
|
||||
@@ -0,0 +1,45 @@
|
||||
---
|
||||
|
||||
slug: /create-spatial-columns
|
||||
---
|
||||
|
||||
# Create a spatial column
|
||||
|
||||
seekdb allows you to create a spatial column using the `CREATE TABLE` or `ALTER TABLE` statement.
|
||||
|
||||
To create a table with spatial columns using the `CREATE TABLE` statement, see the following syntax example:
|
||||
|
||||
```sql
|
||||
CREATE TABLE geom (g GEOMETRY);
|
||||
```
|
||||
|
||||
To add or remove spatial columns in an existing table using the `ALTER TABLE` statement, see the following syntax example:
|
||||
|
||||
```sql
|
||||
ALTER TABLE geom ADD pt POINT;
|
||||
ALTER TABLE geom DROP pt;
|
||||
```
|
||||
|
||||
Examples:
|
||||
|
||||
```sql
|
||||
obclient> CREATE TABLE geom (
|
||||
p POINT SRID 0,
|
||||
g GEOMETRY NOT NULL SRID 4326
|
||||
);
|
||||
Query OK, 0 rows affected
|
||||
```
|
||||
|
||||
The following constraints apply when creating spatial columns:
|
||||
|
||||
* You can explicitly specify an SRID when defining a spatial column. If no SRID is defined on the column, the optimizer will not select the spatial index during queries, but index records will still be generated during insert/update operations.
|
||||
|
||||
* A spatial index can be defined on a spatial column only after specifying the` NOT NULL` constraint and an SRID. In other words, only columns with a defined SRID can use spatial indexes.
|
||||
|
||||
* Once an SRID is defined on a spatial column, attempting to insert values with a different SRID will result in an error.
|
||||
|
||||
The following constraints apply to `SRID`:
|
||||
|
||||
* You must explicitly specify `SRID` for a spatial column.
|
||||
|
||||
* All objects in the column must have the same SRID.
|
||||
@@ -0,0 +1,71 @@
|
||||
---
|
||||
|
||||
slug: /create-spatial-indexes
|
||||
---
|
||||
|
||||
# Create a spatial index
|
||||
|
||||
seekdb allows you to create a spatial index using the `SPATIAL` keyword. When creating a table, the spatial index column must be declared as `NOT NULL`. Spatial indexes can be created on stored (STORED) generated columns, but not on virtual (VIRTUAL) generated columns.
|
||||
|
||||
## Constraints
|
||||
|
||||
* The column definition for creating a spatial index must include the `NOT NULL` constraint.
|
||||
* The column with a spatial index must have an SRID defined. Otherwise, the spatial index on this column will not take effect during queries.
|
||||
* If you create a spatial index on a STORED generated column, you must explicitly specify the `STORED` keyword in the DDL when creating the column. If neither the `VIRTUAL` nor `STORED` keyword is specified when creating a generated column, a VIRTUAL generated column is created by default.
|
||||
* After an index is created, comparisons use the coordinate system corresponding to the SRID defined in the column. Spatial indexes store the Minimum Bounding Rectangle (MBR) of geometric objects, and the comparison method for MBRs also depends on the SRID.
|
||||
|
||||
## Preparations
|
||||
|
||||
Before using the GIS feature, you need to configure GIS metadata. After connecting to the server, execute the following command to import the `default_srs_data_mysql.sql` file into the database:
|
||||
|
||||
```shell
|
||||
-- module specifies the module to import.
|
||||
-- infile specifies the relative path of the SQL file to import.
|
||||
ALTER SYSTEM LOAD MODULE DATA module=gis infile = 'etc/default_srs_data_mysql.sql';
|
||||
```
|
||||
|
||||
<!-- For more information about the syntax, see [LOAD MODULE DATA](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980607). -->
|
||||
|
||||
The following result indicates that the data file was successfully imported:
|
||||
|
||||
```shell
|
||||
Query OK, 0 rows affected
|
||||
```
|
||||
|
||||
## Examples
|
||||
|
||||
The following examples show how to create a spatial index on a regular column:
|
||||
|
||||
* Using `CREATE TABLE`:
|
||||
|
||||
```sql
|
||||
CREATE TABLE geom (g GEOMETRY NOT NULL SRID 4326, SPATIAL INDEX(g));
|
||||
```
|
||||
|
||||
* Using `ALTER TABLE`:
|
||||
|
||||
```sql
|
||||
CREATE TABLE geom (g GEOMETRY NOT NULL SRID 4326);
|
||||
ALTER TABLE geom ADD SPATIAL INDEX(g);
|
||||
```
|
||||
|
||||
* Using `CREATE INDEX`:
|
||||
|
||||
```sql
|
||||
CREATE TABLE geom (g GEOMETRY NOT NULL SRID 4326);
|
||||
CREATE SPATIAL INDEX g ON geom (g);
|
||||
```
|
||||
|
||||
The following examples show how to drop a spatial index:
|
||||
|
||||
* Using `ALTER TABLE`:
|
||||
|
||||
```sql
|
||||
ALTER TABLE geom DROP INDEX g;
|
||||
```
|
||||
|
||||
* Using `DROP INDEX`:
|
||||
|
||||
```sql
|
||||
DROP INDEX g ON geom;
|
||||
```
|
||||
@@ -0,0 +1,275 @@
|
||||
---
|
||||
|
||||
slug: /spatial-data-format
|
||||
---
|
||||
|
||||
# Spatial data formats
|
||||
|
||||
seekdb supports two standard spatial data formats for representing geometric objects in queries:
|
||||
|
||||
* Well-Known Text (WKT)
|
||||
|
||||
* Well-Known Binary (WKB)
|
||||
|
||||
## WKT
|
||||
|
||||
WKT is defined based on Extended Backus-Naur Form (EBNF). WKT can be used both as a data format (referred to as WKT-Data in this document) and for defining spatial reference systems (SRS) in Geographic Information System (GIS) (referred to as WKT-SRS in this document).
|
||||
|
||||
### Point
|
||||
|
||||
A point does not use commas as separators. Example format:
|
||||
|
||||
```sql
|
||||
POINT(15 20)
|
||||
```
|
||||
|
||||
The following example uses `ST_X()` to extract the `X` coordinate from a point object. The first example directly generates the object using the `Point()` function. The second example uses the WKT representation converted to point through `ST_GeomFromText()`.
|
||||
|
||||
```sql
|
||||
obclient> SELECT ST_X(Point(15, 20));
|
||||
+---------------------+
|
||||
| ST_X(Point(15, 20)) |
|
||||
+---------------------+
|
||||
| 15 |
|
||||
+---------------------+
|
||||
1 row in set
|
||||
|
||||
obclient> SELECT ST_X(ST_GeomFromText('POINT(15 20)'));
|
||||
+---------------------------------------+
|
||||
| ST_X(ST_GeomFromText('POINT(15 20)')) |
|
||||
+---------------------------------------+
|
||||
| 15 |
|
||||
+---------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
### Line
|
||||
|
||||
A line consists of multiple points separated by commas. Example format:
|
||||
|
||||
```sql
|
||||
LINESTRING(0 0, 10 10, 20 25, 50 60)
|
||||
```
|
||||
|
||||
### Polygon
|
||||
|
||||
A polygon consists of at least one exterior ring (closed line) and any number (can be 0) of interior rings (closed lines). Example format:
|
||||
|
||||
```sql
|
||||
POLYGON((0 0,10 0,10 10,0 10,0 0),(5 5,7 5,7 7,5 7, 5 5))
|
||||
```
|
||||
|
||||
### MultiPoint
|
||||
|
||||
A MultiPoint consists of multiple points, similar to a line but with different semantics. Multiple connected points form a line, while discrete multiple points form a MultiPoint. Example format:
|
||||
|
||||
```sql
|
||||
MULTIPOINT(0 0, 20 20, 60 60)
|
||||
```
|
||||
|
||||
In the functions `ST_MPointFromText()` and `ST_GeoFromText()`, it is also valid to enclose points in a MultiPoint with parentheses. Example format:
|
||||
|
||||
```sql
|
||||
ST_MPointFromText('MULTIPOINT (1 1, 2 2, 3 3)')
|
||||
ST_MPointFromText('MULTIPOINT ((1 1), (2 2), (3 3))')
|
||||
```
|
||||
|
||||
### MultiLineString
|
||||
|
||||
A MultiLineString is a collection of multiple lines. Example format:
|
||||
|
||||
```sql
|
||||
MULTILINESTRING((10 10, 20 20), (15 15, 30 15))
|
||||
```
|
||||
|
||||
### MultiPolygon
|
||||
|
||||
A MultiPolygon is a collection of multiple polygons. Example format:
|
||||
|
||||
```sql
|
||||
MULTIPOLYGON(((0 0,10 0,10 10,0 10,0 0)),((5 5,7 5,7 7,5 7, 5 5)))
|
||||
```
|
||||
|
||||
### GeometryCollection
|
||||
|
||||
A GeometryCollection can be a collection of multiple basic types and collection types.
|
||||
|
||||
```sql
|
||||
GEOMETRYCOLLECTION(POINT(10 10), POINT(30 30), LINESTRING(15 15, 20 20))
|
||||
```
|
||||
|
||||
## WKB
|
||||
|
||||
WKB is developed based on the OpenGIS specification and supports seven types (Point, LineString, Polygon, MultiPoint, MultiLineString, MultiPolygon, and Geometrycollection) with corresponding format definitions.
|
||||
|
||||
### Point
|
||||
|
||||
Using `POINT(1 -1)` as an example, the format definition is shown in the following table.
|
||||
|
||||
| **Component** | **Specification** | **Type** | **Value** |
|
||||
| --- | --- | --- | --- |
|
||||
| **Byte order** | 1 byte | unsigned int | 01 |
|
||||
| **WKB type** | 4 bytes | unsigned int | 01000000 |
|
||||
| **X coordinate** | 8 bytes | double-precision | 000000000000F03F |
|
||||
| **Y coordinate** | 8 bytes | double-precision | 000000000000F0BF |
|
||||
|
||||
### Linestring
|
||||
|
||||
Using `LINESTRING(1 -1, -1 1)` as an example, the format definition is shown in the following table. `Num points` must be greater than or equal to 2.
|
||||
|
||||
| **Component** | **Specification** | **Type** | **Value** |
|
||||
| --- | --- | --- | --- |
|
||||
| **Byte order** | 1 byte | unsigned int | 01 |
|
||||
| **WKB type** | 4 bytes | unsigned int | 02000000 |
|
||||
| **Num points** | 4 bytes | unsigned int | 02000000 |
|
||||
| **X coordinate** | 8 bytes | double-precision | 000000000000F03F |
|
||||
| **Y coordinate** | 8 bytes | double-precision | 000000000000F0BF |
|
||||
| **X coordinate** | 8 bytes | double-precision | 000000000000F0BF |
|
||||
| **Y coordinate** | 8 bytes | double-precision | 000000000000F03F |
|
||||
|
||||
### Polygon
|
||||
|
||||
| **Component** | **Specification** | **Type** | **Value** |
|
||||
| --- | --- | --- | --- |
|
||||
| **Byte order** | 1 byte | unsigned int | 01 |
|
||||
| **WKB type** | 4 bytes | unsigned int | 03000000 |
|
||||
| **Num rings** | 4 bytes | unsigned int | Greater than or equal to 1 |
|
||||
| **repeat ring** | - |- | - |
|
||||
|
||||
### MultiPoint
|
||||
|
||||
| **Component** | **Specification** | **Type** | **Value** |
|
||||
| --- | --- | --- | --- |
|
||||
| **Byte order** | 1 byte | unsigned int | 01 |
|
||||
| **WKB type** | 4 bytes | unsigned int | 04000000 |
|
||||
| **Num points** | 4 bytes | unsigned int | Num points >= 1 |
|
||||
| **repeat POINT** | - |- | - |
|
||||
|
||||
### MultiLineString
|
||||
|
||||
| **Component** | **Specification** | **Type** | **Value** |
|
||||
| --- | --- | --- | --- |
|
||||
| **Byte order** | 1 byte | unsigned int | 01 |
|
||||
| **WKB type** | 4 bytes | unsigned int | 05000000 |
|
||||
| **Num linestrings** | 4 bytes | unsigned int | Greater than or equal to 1 |
|
||||
| **repeat LINESTRING** | - | - | - |
|
||||
|
||||
### MultiPolygon
|
||||
|
||||
| **Component** | **Specification** | **Type** | **Value** |
|
||||
| --- | --- | --- | --- |
|
||||
| **Byte order** | 1 byte | unsigned int | 01 |
|
||||
| **WKB type** | 4 bytes | unsigned int | 06000000 |
|
||||
| **Num polygons** | 4 bytes | unsigned int | Greater than or equal to 1 |
|
||||
| **repeat POLYGON** | - | - | - |
|
||||
|
||||
### GeometryCollection
|
||||
|
||||
| **Component** | **Specification** | **Type** | **Value** |
|
||||
| --- | --- | --- | --- |
|
||||
| **Byte order** | 1 byte | unsigned int | 01 |
|
||||
| **WKB type** | 4 bytes | unsigned int | 07000000 |
|
||||
| **Num wkbs** | 4 bytes | unsigned int | - |
|
||||
| **repeat WKB** | - | - | - |
|
||||
|
||||
>Note:
|
||||
>
|
||||
>* Only GeometryCollection can be empty, indicating that 0 elements are stored. All other types cannot be empty.
|
||||
>* When `LENGTH()` is applied to a GIS object, it returns the length of the stored binary data.
|
||||
|
||||
```sql
|
||||
obclient [test]> SET @g = ST_GeomFromText('POINT(1 -1)');
|
||||
Query OK, 0 rows affected
|
||||
|
||||
obclient [test]> SELECT LENGTH(@g);
|
||||
+------------+
|
||||
| LENGTH(@g) |
|
||||
+------------+
|
||||
| 25 |
|
||||
+------------+
|
||||
1 row in set
|
||||
|
||||
obclient [test]> SELECT HEX(@g);
|
||||
+----------------------------------------------------+
|
||||
| HEX(@g) |
|
||||
+----------------------------------------------------+
|
||||
| 000000000101000000000000000000F03F000000000000F0BF |
|
||||
+----------------------------------------------------+
|
||||
1 row in set
|
||||
```
|
||||
|
||||
## Syntax and geometric validity
|
||||
|
||||
### Syntax validity
|
||||
|
||||
Syntax validity must satisfy the following conditions:
|
||||
|
||||
- A linestring must have at least two points.
|
||||
- A polygon must have at least one ring.
|
||||
- A polygon must be closed (the first and last points are the same).
|
||||
- A polygon's ring must have at least four points (the smallest polygon is a triangle, where the first and last points are the same).
|
||||
- Except for GeometryCollection, other collection types cannot be empty.
|
||||
|
||||
### Geometric validity
|
||||
|
||||
Geometric validity must satisfy the following conditions:
|
||||
|
||||
- A polygon cannot intersect with itself.
|
||||
- The exterior ring of a Polygon must be outside the interior rings.
|
||||
- Multipolygons cannot contain overlapping polygons.
|
||||
|
||||
You can explicitly check the geometric validity of a geometry object using the ST_IsValid() function.
|
||||
|
||||
## GIS Examples
|
||||
|
||||
### Insert data
|
||||
|
||||
```sql
|
||||
// Both conversion functions and WKT are included in the SQL statement.
|
||||
INSERT INTO geom VALUES (ST_GeomFromText('POINT(1 1)'));
|
||||
|
||||
// WKT is provided as a parameter.
|
||||
SET @g = 'POINT(1 1)';
|
||||
INSERT INTO geom VALUES (ST_GeomFromText(@g));
|
||||
|
||||
// Conversion expressions are directly embedded in the parameters.
|
||||
SET @g = ST_GeomFromText('POINT(1 1)');
|
||||
INSERT INTO geom VALUES (@g);
|
||||
|
||||
// A unified conversion function is used.
|
||||
SET @g = 'LINESTRING(0 0,1 1,2 2)';
|
||||
INSERT INTO geom VALUES (ST_GeomFromText(@g));
|
||||
|
||||
SET @g = 'POLYGON((0 0,10 0,10 10,0 10,0 0),(5 5,7 5,7 7,5 7, 5 5))';
|
||||
INSERT INTO geom VALUES (ST_GeomFromText(@g));
|
||||
|
||||
SET @g ='GEOMETRYCOLLECTION(POINT(1 1),LINESTRING(0 0,1 1,2 2,3 3,4 4))';
|
||||
INSERT INTO geom VALUES (ST_GeomFromText(@g));
|
||||
|
||||
// Type-specific conversion functions are employed.
|
||||
SET @g = 'POINT(1 1)';
|
||||
INSERT INTO geom VALUES (ST_PointFromText(@g));
|
||||
|
||||
SET @g = 'LINESTRING(0 0,1 1,2 2)';
|
||||
INSERT INTO geom VALUES (ST_LineStringFromText(@g));
|
||||
|
||||
SET @g = 'POLYGON((0 0,10 0,10 10,0 10,0 0),(5 5,7 5,7 7,5 7, 5 5))';
|
||||
INSERT INTO geom VALUES (ST_PolygonFromText(@g));
|
||||
|
||||
SET @g =
|
||||
'GEOMETRYCOLLECTION(POINT(1 1),LINESTRING(0 0,1 1,2 2,3 3,4 4))';
|
||||
INSERT INTO geom VALUES (ST_GeomCollFromText(@g));
|
||||
|
||||
// Data can also be inserted directly using WKB.
|
||||
INSERT INTO geom VALUES(ST_GeomFromWKB(X'0101000000000000000000F03F000000000000F03F'));
|
||||
```
|
||||
|
||||
### Query data
|
||||
|
||||
```sql
|
||||
// Query data and convert it to WKT format for output.
|
||||
SELECT ST_AsText(g) FROM geom;
|
||||
|
||||
// Query data and convert it to WKB format for output.
|
||||
SELECT ST_AsBinary(g) FROM geom;
|
||||
```
|
||||
@@ -0,0 +1,46 @@
|
||||
---
|
||||
|
||||
slug: /char-and-varchar
|
||||
---
|
||||
|
||||
# CHAR and VARCHAR
|
||||
|
||||
`CHAR` and `VARCHAR` types are similar, but differ in how they are stored and retrieved, their maximum length, and whether trailing spaces are preserved.
|
||||
|
||||
## CHAR
|
||||
|
||||
The declared length of the `CHAR` type is the maximum number of characters that can be stored. For example, `CHAR(30)` can contain up to 30 characters.
|
||||
|
||||
Syntax:
|
||||
|
||||
```sql
|
||||
[NATIONAL] CHAR[(M)] [CHARACTER SET charset_name] [COLLATE collation_name]
|
||||
```
|
||||
|
||||
`CHARACTER SET` is used to specify the character set. If needed, you can use the `COLLATE` attribute along with other attributes to specify the collation rules for the character set. If the binary attribute of `CHARACTER SET` is specified, the column will be created as the corresponding binary string data type, and `CHAR` becomes `BINARY`.
|
||||
|
||||
`CHAR` column length can be any value between 0 and 256. When storing `CHAR` values, they are right-padded with spaces to the specified length.
|
||||
|
||||
For `CHAR` columns, excess trailing spaces in inserted values are silently truncated regardless of the SQL mode. When retrieving `CHAR` values, trailing spaces are removed unless the `PAD_CHAR_TO_FULL_LENGTH` SQL mode is enabled.
|
||||
|
||||
## VARCHAR
|
||||
|
||||
The declared length `M` of the `VARCHAR` type is the maximum number of characters that can be stored. For example, `VARCHAR(50)` can contain up to 50 characters.
|
||||
|
||||
Syntax:
|
||||
|
||||
```sql
|
||||
[NATIONAL] VARCHAR(M) [CHARACTER SET charset_name] [COLLATE collation_name]
|
||||
```
|
||||
|
||||
`CHARACTER SET` is used to specify the character set. If needed, you can use the `COLLATE` attribute along with other attributes to specify the collation rules for the character set. If the binary attribute of `CHARACTER SET` is specified, the column will be created as the corresponding binary string data type, and `VARCHAR` becomes `VARBINARY`.
|
||||
|
||||
`VARCHAR` column length can be specified as any value between 0 and 262144.
|
||||
|
||||
Compared with `CHAR`, `VARCHAR` values are stored as a 1-byte or 2-byte length prefix plus the data. The length prefix indicates the number of bytes in the value. If the value does not exceed 255 bytes, the column uses one byte; if the value may exceed 255 bytes, it uses two bytes.
|
||||
|
||||
For `VARCHAR` columns, trailing spaces that exceed the column length are truncated before insertion and generate a warning, regardless of the SQL mode.
|
||||
|
||||
`VARCHAR` values are not padded when stored. According to standard SQL, trailing spaces are preserved during both storage and retrieval.
|
||||
|
||||
Additionally, seekdb also supports the extended type `CHARACTER VARYING(m)`, but `VARCHAR(m)` is recommended.
|
||||
@@ -0,0 +1,64 @@
|
||||
---
|
||||
|
||||
slug: /text
|
||||
---
|
||||
|
||||
# TEXT types
|
||||
|
||||
The `TEXT` type is used to store all types of text data.
|
||||
|
||||
There are four text types: `TINYTEXT`, `TEXT`, `MEDIUMTEXT`, and `LONGTEXT`. They correspond to the four `BLOB` types and have the same maximum length and storage requirements.
|
||||
|
||||
`TEXT` values are treated as non-binary strings. They have a character set other than binary, and values are sorted and compared according to the collation rules of the character set.
|
||||
|
||||
When strict SQL mode is not enabled, if a value assigned to a `TEXT` column exceeds the column's maximum length, the portion that exceeds the length is truncated and a warning is generated. When using strict SQL mode, an error occurs (rather than a warning) if non-space characters are truncated, and the value insertion is prohibited. Regardless of the SQL mode, truncating excess trailing spaces from values inserted into `TEXT` columns always generates a warning.
|
||||
|
||||
## TINYTEXT
|
||||
|
||||
`TINYTEXT` is a `TEXT` type with a maximum length of 255 bytes.
|
||||
|
||||
`TINYTEXT` syntax:
|
||||
|
||||
```sql
|
||||
TINYTEXT [CHARACTER SET charset_name] [COLLATE collation_name]
|
||||
```
|
||||
|
||||
`CHARACTER SET` is used to specify the character set. If needed, you can use the `COLLATE` attribute along with other attributes to specify the collation rules for the character set. If the binary attribute of `CHARACTER SET` is specified, the column will be created as the corresponding binary string data type, and `TEXT` becomes `BLOB`.
|
||||
|
||||
## TEXT
|
||||
|
||||
The maximum length of a `TEXT` column is 65,535 bytes.
|
||||
|
||||
An optional length `M` can be specified for the `TEXT` type. Syntax:
|
||||
|
||||
```sql
|
||||
TEXT[(M)] [CHARACTER SET charset_name] [COLLATE collation_name]
|
||||
```
|
||||
|
||||
`CHARACTER SET` is used to specify the character set. If needed, you can use the `COLLATE` attribute along with other attributes to specify the collation rules for the character set. If the binary attribute of `CHARACTER SET` is specified, the column will be created as the corresponding binary string data type, and `TEXT` becomes `BLOB`.
|
||||
|
||||
## MEDIUMTEXT
|
||||
|
||||
`MEDIUMTEXT` is a `TEXT` type with a maximum length of 16,777,215 bytes.
|
||||
|
||||
`MEDIUMTEXT` syntax:
|
||||
|
||||
```sql
|
||||
MEDIUMTEXT [CHARACTER SET charset_name] [COLLATE collation_name]
|
||||
```
|
||||
|
||||
`CHARACTER SET` is used to specify the character set. If needed, you can use the `COLLATE` attribute along with other attributes to specify the collation rules for the character set. If the binary attribute of `CHARACTER SET` is specified, the column will be created as the corresponding binary string data type, and `TEXT` becomes `BLOB`.
|
||||
|
||||
Additionally, seekdb also supports the extended type `LONG`, but `MEDIUMTEXT` is recommended.
|
||||
|
||||
## LONGTEXT
|
||||
|
||||
`LONGTEXT` is a `TEXT` type with a maximum length of 536,870,910 bytes. The effective maximum length of a `LONGTEXT` column also depends on the maximum packet size configured in the client/server protocol and available memory.
|
||||
|
||||
`LONGTEXT` syntax:
|
||||
|
||||
```sql
|
||||
LONGTEXT [CHARACTER SET charset_name] [COLLATE collation_name]
|
||||
```
|
||||
|
||||
`CHARACTER SET` is used to specify the character set. If needed, you can use the `COLLATE` attribute along with other attributes to specify the collation rules for the character set. If the binary attribute of `CHARACTER SET` is specified, the column will be created as the corresponding binary string data type, and `TEXT` becomes `BLOB`.
|
||||
@@ -0,0 +1,329 @@
|
||||
---
|
||||
|
||||
slug: /full-text-index
|
||||
---
|
||||
|
||||
# Full-text indexes
|
||||
|
||||
In seekdb, full-text indexes can be applied to columns of `CHAR`, `VARCHAR`, and `TEXT` types. Additionally, seekdb allows multiple full-text indexes to be created on the primary table, and multiple full-text indexes can also be created on the same column.
|
||||
|
||||
Full-text indexes can be created on both partitioned and non-partitioned tables, regardless of whether they have a primary key. The limitations for creating full-text indexes are as follows:
|
||||
|
||||
* Full-text indexes can only be applied to columns of `CHAR`, `VARCHAR`, and `TEXT` types.
|
||||
* The current version only supports creating local (`LOCAL`) full-text indexes.
|
||||
* The `UNIQUE` keyword cannot be specified when creating a full-text index.
|
||||
* If you want to create a full-text index involving multiple columns, you must ensure that these columns have the same character set.
|
||||
|
||||
By using these syntax rules and guidelines, seekdb's full-text indexing functionality provides efficient search and retrieval capabilities for text data.
|
||||
|
||||
## DML operations
|
||||
|
||||
For tables with full-text indexes, complex DML operations are supported, including `INSERT INTO ON DUPLICATE KEY`, `REPLACE INTO`, multi-table updates/deletes, and updatable views.
|
||||
|
||||
**Examples:**
|
||||
|
||||
* `INSERT INTO ON DUPLICATE KEY`:
|
||||
|
||||
```sql
|
||||
INSERT INTO articles VALUES ('OceanBase', 'Fulltext search index support insert into on duplicate key')
|
||||
ON DUPLICATE KEY UPDATE title = 'OceanBase 4.3.3';
|
||||
```
|
||||
|
||||
* `REPLACE INTO`:
|
||||
|
||||
```sql
|
||||
REPLACE INTO articles(title, context) VALUES ('Oceanbase 4.3.3', 'Fulltext search index support replace');
|
||||
```
|
||||
|
||||
* Multi-table updates and deletes.
|
||||
|
||||
1. Create table `tbl1`.
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl1 (a int PRIMARY KEY, b text, FULLTEXT INDEX(b));
|
||||
```
|
||||
|
||||
2. Create table `tbl2`.
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl2 (a int PRIMARY KEY, b text);
|
||||
```
|
||||
|
||||
3. Perform an update (`UPDATE`) operation on multiple tables.
|
||||
|
||||
```sql
|
||||
UPDATE tbl1 JOIN tbl2 ON tbl1.a = tbl2.a
|
||||
SET tbl1.b = 'dddd', tbl2.b = 'eeee';
|
||||
```
|
||||
|
||||
```sql
|
||||
UPDATE tbl1 JOIN tbl2 ON tbl1.a = tbl2.a SET tbl1.b = 'dddd';
|
||||
```
|
||||
|
||||
```sql
|
||||
UPDATE tbl1 JOIN tbl2 ON tbl1.a = tbl2.a SET tbl2.b = tbl1.b;
|
||||
```
|
||||
|
||||
4. Perform a delete (`DELETE`) operation on multiple tables.
|
||||
|
||||
```sql
|
||||
DELETE tbl1, tbl2 FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.a;
|
||||
```
|
||||
|
||||
```sql
|
||||
DELETE tbl1 FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.a;
|
||||
```
|
||||
|
||||
```sql
|
||||
DELETE tbl1 FROM tbl1 JOIN tbl2 ON tbl1.a = tbl2.a;
|
||||
```
|
||||
|
||||
* DML operations on updatable views.
|
||||
|
||||
1. Create view `fts_view`.
|
||||
|
||||
```sql
|
||||
CREATE VIEW fts_view AS SELECT * FROM tbl1;
|
||||
```
|
||||
|
||||
2. Perform an `INSERT` operation on the updatable view.
|
||||
|
||||
```sql
|
||||
INSERT INTO fts_view VALUES(3, 'cccc'), (4, 'dddd');
|
||||
```
|
||||
|
||||
3. Perform an `UPDATE` operation on the updatable view.
|
||||
|
||||
```sql
|
||||
UPDATE fts_view SET b = 'dddd';
|
||||
```
|
||||
|
||||
```sql
|
||||
UPDATE fts_view JOIN normal ON fts_view.a = tbl2.a
|
||||
SET fts_view.b = 'dddd', tbl2.b = 'eeee';
|
||||
```
|
||||
|
||||
4. Perform a `DELETE` operation on the updatable view.
|
||||
|
||||
```sql
|
||||
DELETE FROM fts_view WHERE b = 'dddd';
|
||||
```
|
||||
|
||||
```sql
|
||||
DELETE tbl1 FROM fts_view JOIN tbl1 ON fts_view.a = tbl1.a AND 1 = 0;
|
||||
```
|
||||
|
||||
## Full-text index tokenizer
|
||||
|
||||
seekdb's full-text index functionality supports multiple built-in tokenizers, helping users select the optimal text tokenization strategy based on their business scenarios. The default tokenizer is **Space**, while other tokenizers need to be explicitly specified using the `WITH PARSER` parameter.
|
||||
|
||||
**List of tokenizers**:
|
||||
|
||||
* **Space tokenizer**
|
||||
* **Basic English tokenizer**
|
||||
* **IK tokenizer**
|
||||
* **Ngram tokenizer**
|
||||
* **Jieba tokenizer**
|
||||
|
||||
**Configuration example**:
|
||||
|
||||
When creating or modifying a table, specify the tokenizer type for the full-text index by setting the `WITH PARSER tokenizer_option` parameter in the `CREATE TABLE/ALTER TABLE` statement.
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl2(id INT, name VARCHAR(18), doc TEXT,
|
||||
FULLTEXT INDEX full_idx1_tbl2(name, doc)
|
||||
WITH PARSER NGRAM
|
||||
PARSER_PROPERTIES=(ngram_token_size=3));
|
||||
|
||||
|
||||
-- Modify the full-text index tokenizer of an existing table.
|
||||
ALTER TABLE tbl2(id INT, name VARCHAR(18), doc TEXT,
|
||||
FULLTEXT INDEX full_idx1_tbl2(name, doc)
|
||||
WITH PARSER NGRAM
|
||||
PARSER_PROPERTIES=(ngram_token_size=3)); -- Ngram example
|
||||
```
|
||||
|
||||
### Space tokenizer (default)
|
||||
|
||||
**Concepts**:
|
||||
|
||||
* This tokenizer splits text using spaces, punctuation marks (such as commas, periods), or non-alphanumeric characters (except underscore `_`) as delimiters.
|
||||
* The tokenization results include only valid tokens with lengths between `min_token_size` (default 3) and `max_token_size` (default 84).
|
||||
* Chinese characters are treated as single tokens.
|
||||
|
||||
**Applicable scenarios**:
|
||||
|
||||
* Languages separated by spaces such as English (for example "apple watch series 9").
|
||||
* Chinese text with manually added delimiters (for example, "南京 长江大桥").
|
||||
|
||||
**Tokenization result**:
|
||||
|
||||
```shell
|
||||
OceanBase [(rooteoceanbase)]> select tokenize("南京市长江大桥有1千米长,详见www.XXX.COM, 邮箱xx@OB.COM,一平方公里也很小 hello-word h_name", 'space');
|
||||
+-------------------------------------------------------------------------------------------------------------+
|
||||
| tokenize("南京市长江大桥有1千米长,详见www.XXX.COM, 邮箱xx@OB.COM,一平方公里也很小 hello-word h_name", 'space') |
|
||||
+-------------------------------------------------------------------------------------------------------------+
|
||||
|["详见www", "一平方公里也很小", "xxx", "南京市长江大桥有1千米长", "邮箱xx", "word", "hello”, "h_name"] |
|
||||
+-------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
**Example explanation**:
|
||||
|
||||
* Spaces, commas, periods, and other symbols serve as delimiters, and consecutive Chinese characters are treated as words.
|
||||
|
||||
### Basic English (Beng) tokenizer
|
||||
|
||||
**Concepts**:
|
||||
|
||||
* Similar to the Space tokenizer, but treats underscores `_` as separators instead of preserving them.
|
||||
* Suitable for separating English phrases, but has limited effectiveness in splitting terms without spaces (such as "iPhone15").
|
||||
|
||||
**Applicable scenarios**:
|
||||
|
||||
* Basic retrieval of English documents (such as logs, comments).
|
||||
|
||||
**Tokenization result**:
|
||||
|
||||
```shell
|
||||
OceanBase [(rooteoceanbase)]> select tokenize("System log entry: server_status is active, visit www.EXAMPLE.COM, contact admin@DB.COM, response_time 150ms user_name", 'beng');
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| tokenize("System log entry: server_status is active, visit www.EXAMPLE.COM, contact admin@DB.COM, response_time 150ms user_name", 'beng') |
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| ["user", "log", "system", "admin", "contact", "server", "active", "visit", "status", "entry", "example", "name", "time", "response", "150ms"] |
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
**Example explanation**:
|
||||
|
||||
* Underscores `_` are split into separate tokens (for example, `server_status` -> `server`, `status`, and `user_name` -> `user`, `name`). The core difference from the Space tokenizer lies in how it handles underscores `_`.
|
||||
|
||||
### Ngram tokenizer
|
||||
|
||||
**Concepts**:
|
||||
|
||||
* **Fixed n-value tokenization**: By default, `n=2`. This tokenizer splits consecutive non-delimiter characters into subsequences of length `n`.
|
||||
* Delimiter rules follow the Space tokenizer (preserving `_`, digits, and letters).
|
||||
* **Does not support length limit parameters**, outputs all possible tokens of length `n`.
|
||||
|
||||
**Applicable scenarios**:
|
||||
|
||||
* Fuzzy matching for short text (such as user IDs, order numbers).
|
||||
* Scenarios requiring fixed-length feature extraction (such as password policy analysis).
|
||||
|
||||
**Tokenization result**:
|
||||
|
||||
```shell
|
||||
OceanBase [(rooteoceanbase)]> select tokenize("Order ID: ORD12345, user_account: john_doe, email support@example.com, tracking code ABC-XYZ-789", 'ngram');
|
||||
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| tokenize("Order ID: ORD12345, user_account: john_doe, email support@example.com, tracking code ABC-XYZ-789", 'ngram') |
|
||||
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| ["ab", "hn", "am", "r_", "em", "le", "po", "ma", "ou", "xy", "jo", "pl", "_d", "89", "yz", "xa", "ck", "in", "se", "tr", "oh", "12", "d1", "il", "oe", "45", "un", "ac", "co", "ex", "us", "23", "34", "or", "er", "mp", "up", "de", "su", "rt", "pp", "n_", "nt", "ki", "rd", "_a", "bc", "ng", "cc", "od", "om", "78", "ra", "ai", "do", "id"] |
|
||||
+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
**Example explanation**:
|
||||
|
||||
* With the default setting `n=2`, this tokenizer outputs all consecutive 2-character tokens, including overlapping ones (for example, `ORD12345` -> `OR`, `RD`, `D1`, `12`, `23`, `34`, `45`;` user_account` -> `us`, `se`, `er`, `r_`, `_a`, `ac`, `cc`, `co`, `ou`, `un`, `nt`).
|
||||
|
||||
### Ngram2 tokenizer
|
||||
|
||||
**Concepts**:
|
||||
|
||||
* Supports **dynamic n-value range**: Sets token length range through `min_ngram_size` and `max_ngram_size` parameters.
|
||||
* Suitable for scenarios requiring multi-length token coverage.
|
||||
|
||||
**Applicable scenarios**: Scenarios that require multiple fixed-length tokens simultaneously.
|
||||
|
||||
:::info
|
||||
When using the ngram2 tokenizer, be aware of its high memory consumption. For example, setting a large range for <code>min_ngram_size</code> and <code>max_ngram_size</code> parameters will generate a large number of token combinations, which may lead to excessive resource consumption.
|
||||
:::
|
||||
|
||||
**Tokenization result**:
|
||||
|
||||
```sql
|
||||
OceanBase [(rooteoceanbase)]> select tokenize("user_login_session_2024", 'ngram2', '[{"additional_args":[{"min_ngram_size": 2},{"max_ngram_size": 4}]}]');
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| tokenize("user_login_session_2024", 'ngram2', '[{"additional_args":[{"min_ngram_size": 2},{"max_ngram_size": 4}]}]') |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| ["io", "lo", "r_lo", "_ses", "_l", "r_", "ss", "user", "ses", "_s", "ogin", "sion", "on", "ess", "20", "logi", "er_", "on_", "use", "essi", "in", "se", "sio", "log", "202", "gin_", "_2", "ssi", "ogi", "us", "n_se", "r_l", "er", "024", "es", "n_2", "og", "_lo", "n_", "_log", "2024", "n_20", "gi", "er_l", "ser", "24", "ssio", "n_s", "gin", "in_", "_se", "02", "_20", "si", "sess", "on_2", "ion_", "ser_", "ion", "_202", "in_s"] |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
**Example explanation**:
|
||||
|
||||
* This tokenizer outputs all consecutive subsequences with lengths between 2-4 characters, with overlapping tokens allowed (for example, `user_login_session_2024` generates tokens like `us`, `use`, `user`, `se`, `ser`, `ser_`, `er_`, `er_l`, `r_lo`, `log`, `logi`, `ogin`, etc.).
|
||||
|
||||
### IK tokenizer
|
||||
|
||||
**Concepts**:
|
||||
|
||||
* A Chinese tokenizer based on the open-source IK Analyzer tool, supporting two modes:
|
||||
|
||||
* **Smart mode**: Prioritizes outputting longer words, reducing the number of splits (for example, "南京市" is not split into "南京" and "市").
|
||||
* **Max Word mode**: Outputs all possible shorter words (for example, "南京市" is split into "南京" and "市").
|
||||
|
||||
* Automatically recognizes English words, email addresses, URLs (without `://`), IP addresses, and other formats.
|
||||
|
||||
**Applicable scenarios**: Chinese word segmentation
|
||||
|
||||
**Business scenarios**:
|
||||
|
||||
* E-commerce product description search (for example, precise matching for "华为Mate60").
|
||||
* Social media content analysis (for example, keyword extraction from user comments).
|
||||
|
||||
* **Smart mode**: Ensures that each character belongs to only one word with no overlap, and guarantees that individual words are as long as possible while minimizing the total number of words. Attempts to combine numerals and quantifiers into a single token.
|
||||
|
||||
```sql
|
||||
OceanBase [(rooteoceanbase)]> select tokenize("南京市长江大桥有1千米长,详见WWW.XXX.COM, 邮箱xx@OB.COM 192.168.1.1 http://www.baidu.com hello-word hello_word", 'IK', '[{"additional_args":[{"ik_mode": "smart"}]}]');
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| tokenize("南京市长江大桥有1千米长,详见WWW.XXX.COM, 邮箱xx@OB.COM 192.168.1.1 http://www.baidu.com hello-word hello_word", 'IK', '[{"additional_args":[{"ik_mode": "smart"}]}]') |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
|["邮箱", "hello_word", "192.168.1.1", "hello-word", "长江大桥", "www.baidu.com", "www.xxx.com", "xx@ob.com", "长", "http", "1千米", "详见", "南京市", "有"] |
|
||||
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
* **max_word mode**: Includes the same character in different tokens, providing as many possible words as possible.
|
||||
|
||||
```sql
|
||||
OceanBase [(rooteoceanbase)]> select select tokenize("The Nanjing Yangtze River Bridge is 1 kilometer long. For more information, see www.xxx.com. E-mail: xx@ob.com.", 'IK', '[{"additional_args":[{"ik_mode": "max_word"}]}]');
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
| tokenize("The Nanjing Yangtze River Bridge is 1 kilometer long. For more information, see www.xxx.com. E-mail: xx@ob.com.", 'IK', '[{"additional_args":[{"ik_mode": "max_word"}]}]') |
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
|["kilometer", "Yangtze River Bridge", "city", "dry", "Nanjing City", "Nanjing", "kilometers", "xx", "www.xxx.com", "long", "www", "xx@ob.com", "Yangtze River", "ob", "XXX", "com", "see", "l", "is", "Bridge", "E-mail"] |
|
||||
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------+
|
||||
```
|
||||
|
||||
### jieba tokenizer
|
||||
|
||||
**Concept**: A tokenizer based on the open-source `jieba` tool from the Python ecosystem, supporting precise mode, full mode, and search engine mode.
|
||||
|
||||
**Features**:
|
||||
|
||||
* **Precise mode**: Strictly segments words according to the dictionary (for example, "不能" is not segmented into "不" and "能").
|
||||
* **Full mode**: Lists all possible segmentation combinations.
|
||||
* **Search engine mode**: Balances precision and recall rate (for example, "南京市长江大桥" is segmented into "南京", "市长", and "长江大桥").
|
||||
* Supports custom dictionaries and new word discovery, and is compatible with multiple languages (Chinese, English, Japanese, etc.).
|
||||
|
||||
**Applicable scenarios**:
|
||||
|
||||
* Medical/technology domain terminology analysis (e.g., precise segmentation of "人工智能").
|
||||
* Multi-language mixed text processing (e.g., social media content with mixed Chinese and English).
|
||||
|
||||
To use the jieba tokenizer plugin, you need to install it yourself. For instructions on how to install it on the compiler, see [Tokenizer plugin](https://en.oceanbase.com/docs/common-oceanbase-database-10000000002414801).
|
||||
|
||||
:::tip
|
||||
The current tokenizer plugin is an experimental feature and is not recommended for use in production environments.
|
||||
:::
|
||||
|
||||
### Tokenizer selection strategy
|
||||
|
||||
| **Business scenario** | **Recommended tokenizer** | **Reason** |
|
||||
| --- | --- | --- |
|
||||
| Search for English product titles | **Space** or **Basic English** | Simple and efficient, aligns with English tokenization conventions. |
|
||||
| Retrieval of Chinese product descriptions | **IK tokenizer** | Accurately recognizes Chinese terminology, supports custom dictionaries. |
|
||||
| Fuzzy matching of logs (such as error codes) | **Ngram tokenizer** | No dictionary required, covers fuzzy query needs for text without spaces. |
|
||||
| Keyword extraction from technology papers | **jieba tokenizer** | Supports new word discovery and complex mode switching. |
|
||||
|
||||
## References
|
||||
|
||||
For more information about creating full-text indexes, see the **Create full-text indexes** section in [Create an index](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001971660).
|
||||
@@ -0,0 +1,60 @@
|
||||
---
|
||||
slug: /pyseekdb-sdk-get-started
|
||||
---
|
||||
|
||||
# Get started
|
||||
|
||||
## pyseekdb
|
||||
|
||||
pyseekdb is a Python client provided by OceanBase Database. It allows you to connect to seekdb in embedded mode or remote mode, and supports connecting to seekdb in server mode or OceanBase Database.
|
||||
|
||||
:::tip
|
||||
OceanBase Database is a fully self-developed, enterprise-level, native distributed database provided by OceanBase. It achieves financial-grade high availability on ordinary hardware and sets a new standard for automatic, lossless disaster recovery across cities with the "five IDCs across three regions" architecture. It also sets a new benchmark in the TPC-C standard test, with a single cluster scale exceeding 1,500 nodes. It is cloud-native, highly consistent, and highly compatible with Oracle and MySQL.
|
||||
:::
|
||||
|
||||
pyseekdb is supported on Linux, macOS, and Windows. The supported database connection modes vary by operating system. For more information, see the table below.
|
||||
|
||||
| System | Embedded seekdb | Server mode seekdb | Server mode OceanBase Database |
|
||||
|----|---|---|---|
|
||||
| Linux | Supported | Supported | Supported |
|
||||
| macOS | Not supported | Supported | Supported |
|
||||
| Windows | Not supported | Supported | Supported |
|
||||
|
||||
For Linux system, when you install this client, it will also install seekdb in embedded mode, allowing you to directly connect to it to perform operations such as creating a database. Alternatively, you can choose to connect to a deployed seekdb or OceanBase Database in client/server mode.
|
||||
|
||||
## Install pyseekdb
|
||||
|
||||
### Prerequisites
|
||||
|
||||
Make sure that your environment meets the following requirements:
|
||||
|
||||
* Operating system: Linux (glibc >= 2.28), macOS or Windows
|
||||
* Python version: Python 3.11 and later
|
||||
* System architecture: x86_64 or aarch64
|
||||
|
||||
### Procedure
|
||||
|
||||
Use pip to install pyseekdb. It will automatically detect the default Python version and platform.
|
||||
|
||||
```shell
|
||||
pip install pyseekdb
|
||||
```
|
||||
|
||||
If your pip version is outdated, upgrade it before installation.
|
||||
|
||||
```bash
|
||||
pip install --upgrade pip
|
||||
```
|
||||
|
||||
## What to do next
|
||||
|
||||
* After installing pyseekdb, you can connect to seekdb to perform operations. For information about the API interfaces supported by pyseekdb, see [API Reference](../50.apis/10.api-overview.md).
|
||||
|
||||
* You can also refer to the SDK samples provided to quickly experience pyseekdb.
|
||||
|
||||
* [Simple sample](50.sdk-samples/10.pyseekdb-simple-sample.md)
|
||||
|
||||
* [Complete sample](50.sdk-samples/50.pyseekdb-complete-sample.md)
|
||||
|
||||
* [Hybrid search sample](50.sdk-samples/100.pyseekdb-hybrid-search-sample.md)
|
||||
|
||||
@@ -0,0 +1,130 @@
|
||||
---
|
||||
slug: /pyseekdb-simple-sample
|
||||
---
|
||||
|
||||
# Simple Example
|
||||
|
||||
This example demonstrates the basic operations of Embedding Functions in embedded mode of seekdb to help you understand how to use Embedding Functions.
|
||||
|
||||
1. Connect to seekdb.
|
||||
2. Create a collection with Embedding Functions.
|
||||
3. Add data using documents (vectors will be automatically generated).
|
||||
4. Query using texts (vectors will be automatically generated).
|
||||
5. Print the query results.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
This example uses seekdb in embedded mode. Before using this example, make sure that you have deployed seekdb in server mode.
|
||||
|
||||
For information about how to deploy seekdb in embedded mode, see [Embedded Mode](../../../../400.guides/400.deploy/600.python-seekdb.md).
|
||||
|
||||
## Example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# ==================== Step 1: Create Client Connection ====================
|
||||
# You can use embedded mode, server mode, or OceanBase mode
|
||||
|
||||
# Embedded mode (local SeekDB)
|
||||
client = pyseekdb.Client()
|
||||
# Alternative: Server mode (connecting to remote SeekDB server)
|
||||
# client = pyseekdb.Client(
|
||||
# host="127.0.0.1",
|
||||
# port=2881,
|
||||
# database="test",
|
||||
# user="root",
|
||||
# password=""
|
||||
# )
|
||||
|
||||
# Alternative: Remote server mode (OceanBase Server)
|
||||
# client = pyseekdb.Client(
|
||||
# host="127.0.0.1",
|
||||
# port=2881,
|
||||
# tenant="test", # OceanBase default tenant
|
||||
# database="test",
|
||||
# user="root",
|
||||
# password=""
|
||||
# )
|
||||
|
||||
# ==================== Step 2: Create a Collection with Embedding Function ====================
|
||||
# A collection is like a table that stores documents with vector embeddings
|
||||
collection_name = "my_simple_collection"
|
||||
|
||||
# Create collection with default embedding function
|
||||
# The embedding function will automatically convert documents to embeddings
|
||||
collection = client.create_collection(
|
||||
name=collection_name,
|
||||
)
|
||||
|
||||
print(f"Created collection '{collection_name}' with dimension: {collection.dimension}")
|
||||
print(f"Embedding function: {collection.embedding_function}")
|
||||
|
||||
# ==================== Step 3: Add Data to Collection ====================
|
||||
# With embedding function, you can add documents directly without providing embeddings
|
||||
# The embedding function will automatically generate embeddings from documents
|
||||
|
||||
documents = [
|
||||
"Machine learning is a subset of artificial intelligence",
|
||||
"Python is a popular programming language",
|
||||
"Vector databases enable semantic search",
|
||||
"Neural networks are inspired by the human brain",
|
||||
"Natural language processing helps computers understand text"
|
||||
]
|
||||
|
||||
ids = ["id1", "id2", "id3", "id4", "id5"]
|
||||
|
||||
# Add data with documents only - embeddings will be auto-generated by embedding function
|
||||
collection.add(
|
||||
ids=ids,
|
||||
documents=documents, # embeddings will be automatically generated
|
||||
metadatas=[
|
||||
{"category": "AI", "index": 0},
|
||||
{"category": "Programming", "index": 1},
|
||||
{"category": "Database", "index": 2},
|
||||
{"category": "AI", "index": 3},
|
||||
{"category": "NLP", "index": 4}
|
||||
]
|
||||
)
|
||||
|
||||
print(f"\nAdded {len(documents)} documents to collection")
|
||||
print("Note: Embeddings were automatically generated from documents using the embedding function")
|
||||
|
||||
# ==================== Step 4: Query the Collection ====================
|
||||
# With embedding function, you can query using text directly
|
||||
# The embedding function will automatically convert query text to query vector
|
||||
|
||||
# Query using text - query vector will be auto-generated by embedding function
|
||||
query_text = "artificial intelligence and machine learning"
|
||||
|
||||
results = collection.query(
|
||||
query_texts=query_text, # Query text - will be embedded automatically
|
||||
n_results=3 # Return top 3 most similar documents
|
||||
)
|
||||
|
||||
print(f"\nQuery: '{query_text}'")
|
||||
print(f"Query results: {len(results['ids'][0])} items found")
|
||||
|
||||
# ==================== Step 5: Print Query Results ====================
|
||||
for i in range(len(results['ids'][0])):
|
||||
print(f"\nResult {i+1}:")
|
||||
print(f" ID: {results['ids'][0][i]}")
|
||||
print(f" Distance: {results['distances'][0][i]:.4f}")
|
||||
if results.get('documents'):
|
||||
print(f" Document: {results['documents'][0][i]}")
|
||||
if results.get('metadatas'):
|
||||
print(f" Metadata: {results['metadatas'][0][i]}")
|
||||
|
||||
# ==================== Step 6: Cleanup ====================
|
||||
# Delete the collection
|
||||
client.delete_collection(collection_name)
|
||||
print(f"\nDeleted collection '{collection_name}'")
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* For information about the APIs supported by pyseekdb, see [API Reference](../../50.apis/10.api-overview.md).
|
||||
|
||||
* [Complete Example](50.pyseekdb-complete-sample.md)
|
||||
|
||||
* [Hybrid Search Example](100.pyseekdb-hybrid-search-sample.md)
|
||||
@@ -0,0 +1,350 @@
|
||||
---
|
||||
slug: /pyseekdb-hybrid-search-sample
|
||||
---
|
||||
|
||||
# Hybrid search example
|
||||
|
||||
This example demonstrates the advantages of `hybrid_search()` over `query()`.
|
||||
|
||||
The main advantages of `hybrid_search()` are:
|
||||
|
||||
* Supports full-text search and vector similarity search simultaneously
|
||||
|
||||
* Allows separate filtering conditions for full-text and vector search
|
||||
|
||||
* Combines the ranked results of both searches using the Reciprocal Rank Fusion algorithm to improve relevance.
|
||||
|
||||
* Handles complex scenarios that `query()` cannot handle
|
||||
|
||||
## Example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Setup
|
||||
client = pyseekdb.Client()
|
||||
collection = client.get_or_create_collection(
|
||||
name="hybrid_search_demo"
|
||||
)
|
||||
|
||||
# Sample data
|
||||
documents = [
|
||||
"Machine learning is revolutionizing artificial intelligence and data science",
|
||||
"Python programming language is essential for machine learning developers",
|
||||
"Deep learning neural networks enable advanced AI applications",
|
||||
"Data science combines statistics, programming, and domain expertise",
|
||||
"Natural language processing uses machine learning to understand text",
|
||||
"Computer vision algorithms process images using deep learning techniques",
|
||||
"Reinforcement learning trains agents through reward-based feedback",
|
||||
"Python libraries like TensorFlow and PyTorch simplify machine learning",
|
||||
"Artificial intelligence systems can learn from large datasets",
|
||||
"Neural networks mimic the structure of biological brain connections"
|
||||
]
|
||||
|
||||
metadatas = [
|
||||
{"category": "AI", "topic": "machine learning", "year": 2023, "popularity": 95},
|
||||
{"category": "Programming", "topic": "python", "year": 2023, "popularity": 88},
|
||||
{"category": "AI", "topic": "deep learning", "year": 2024, "popularity": 92},
|
||||
{"category": "Data Science", "topic": "data analysis", "year": 2023, "popularity": 85},
|
||||
{"category": "AI", "topic": "nlp", "year": 2024, "popularity": 90},
|
||||
{"category": "AI", "topic": "computer vision", "year": 2023, "popularity": 87},
|
||||
{"category": "AI", "topic": "reinforcement learning", "year": 2024, "popularity": 89},
|
||||
{"category": "Programming", "topic": "python", "year": 2023, "popularity": 91},
|
||||
{"category": "AI", "topic": "general ai", "year": 2023, "popularity": 93},
|
||||
{"category": "AI", "topic": "neural networks", "year": 2024, "popularity": 94}
|
||||
]
|
||||
|
||||
ids = [f"doc_{i+1}" for i in range(len(documents))]
|
||||
collection.add(ids=ids, documents=documents, metadatas=metadatas)
|
||||
|
||||
print("=" * 100)
|
||||
print("SCENARIO 1: Keyword + Semantic Search")
|
||||
print("=" * 100)
|
||||
print("Goal: Find documents similar to 'AI research' AND containing 'machine learning'\n")
|
||||
|
||||
# query() approach
|
||||
query_result1 = collection.query(
|
||||
query_texts=["AI research"],
|
||||
where_document={"$contains": "machine learning"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# hybrid_search() approach
|
||||
hybrid_result1 = collection.hybrid_search(
|
||||
query={"where_document": {"$contains": "machine learning"}, "n_results": 10},
|
||||
knn={"query_texts": ["AI research"], "n_results": 10},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
print("query() Results:")
|
||||
for i, doc_id in enumerate(query_result1['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
|
||||
print("\nhybrid_search() Results:")
|
||||
for i, doc_id in enumerate(hybrid_result1['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
|
||||
print("\nAnalysis:")
|
||||
print(" query() ranks 'Deep learning neural networks...' first because it's semantically similar to 'AI research',")
|
||||
print(" but 'machine learning' is not its primary focus. hybrid_search() correctly prioritizes documents that")
|
||||
print(" explicitly contain 'machine learning' (from full-text search) while also being semantically relevant")
|
||||
print(" to 'AI research' (from vector search). The RRF fusion ensures documents matching both criteria rank higher.")
|
||||
|
||||
print("\n" + "=" * 100)
|
||||
print("SCENARIO 2: Independent Filters for Different Search Types")
|
||||
print("=" * 100)
|
||||
print("Goal: Full-text='neural' (year=2024) + Vector='deep learning' (popularity>=90)\n")
|
||||
|
||||
# query() - same filter applies to both conditions
|
||||
query_result2 = collection.query(
|
||||
query_texts=["deep learning"],
|
||||
where={"year": {"$eq": 2024}, "popularity": {"$gte": 90}},
|
||||
where_document={"$contains": "neural"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# hybrid_search() - different filters for each search type
|
||||
hybrid_result2 = collection.hybrid_search(
|
||||
query={"where_document": {"$contains": "neural"}, "where": {"year": {"$eq": 2024}}, "n_results": 10},
|
||||
knn={"query_texts": ["deep learning"], "where": {"popularity": {"$gte": 90}}, "n_results": 10},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
print("query() Results (same filter for both):")
|
||||
for i, doc_id in enumerate(query_result2['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
print(f" {metadatas[idx]}")
|
||||
|
||||
print("\nhybrid_search() Results (independent filters):")
|
||||
for i, doc_id in enumerate(hybrid_result2['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
print(f" {metadatas[idx]}")
|
||||
|
||||
print("\nAnalysis:")
|
||||
print(" query() only returns 2 results because it requires documents to satisfy BOTH year=2024 AND popularity>=90")
|
||||
print(" simultaneously. hybrid_search() returns 5 results by applying year=2024 filter to full-text search")
|
||||
print(" and popularity>=90 filter to vector search independently, then fusing the results. This approach")
|
||||
print(" captures more relevant documents that might satisfy one criterion strongly while meeting the other")
|
||||
|
||||
print("\n" + "=" * 100)
|
||||
print("SCENARIO 3: Combining Multiple Search Strategies")
|
||||
print("=" * 100)
|
||||
print("Goal: Find documents about 'machine learning algorithms'\n")
|
||||
|
||||
# query() - vector search only
|
||||
query_result3 = collection.query(
|
||||
query_texts=["machine learning algorithms"],
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# hybrid_search() - combines full-text and vector
|
||||
hybrid_result3 = collection.hybrid_search(
|
||||
query={"where_document": {"$contains": "machine learning"}, "n_results": 10},
|
||||
knn={"query_texts": ["machine learning algorithms"], "n_results": 10},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
print("query() Results (vector similarity only):")
|
||||
for i, doc_id in enumerate(query_result3['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
|
||||
print("\nhybrid_search() Results (full-text + vector fusion):")
|
||||
for i, doc_id in enumerate(hybrid_result3['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
|
||||
print("\nAnalysis:")
|
||||
print(" query() returns 'Artificial intelligence systems...' as the result, which doesn't explicitly")
|
||||
print(" mention 'machine learning'. hybrid_search() combines full-text search (for 'machine learning')")
|
||||
print(" with vector search (for semantic similarity to 'machine learning algorithms'), ensuring that")
|
||||
print(" documents containing the exact keyword rank higher while still capturing semantically relevant content.")
|
||||
|
||||
print("\n" + "=" * 100)
|
||||
print("SCENARIO 4: Complex Multi-Criteria Search")
|
||||
print("=" * 100)
|
||||
print("Goal: Full-text='learning' (category=AI) + Vector='artificial intelligence' (year>=2023)\n")
|
||||
|
||||
# query() - limited to single search with combined filters
|
||||
query_result4 = collection.query(
|
||||
query_texts=["artificial intelligence"],
|
||||
where={"category": {"$eq": "AI"}, "year": {"$gte": 2023}},
|
||||
where_document={"$contains": "learning"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# hybrid_search() - separate criteria for each search type
|
||||
hybrid_result4 = collection.hybrid_search(
|
||||
query={"where_document": {"$contains": "learning"}, "where": {"category": {"$eq": "AI"}}, "n_results": 10},
|
||||
knn={"query_texts": ["artificial intelligence"], "where": {"year": {"$gte": 2023}}, "n_results": 10},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
print("query() Results:")
|
||||
for i, doc_id in enumerate(query_result4['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
print(f" {metadatas[idx]}")
|
||||
|
||||
print("\nhybrid_search() Results:")
|
||||
for i, doc_id in enumerate(hybrid_result4['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
print(f" {metadatas[idx]}")
|
||||
|
||||
print("\nAnalysis:")
|
||||
print(" While both methods return similar documents, hybrid_search() provides better ranking by prioritizing")
|
||||
print(" documents that score highly in both full-text search (containing 'learning' with category=AI) and")
|
||||
print(" vector search (semantically similar to 'artificial intelligence' with year>=2023). The RRF fusion")
|
||||
print(" algorithm ensures that 'Deep learning neural networks...' ranks first because it strongly matches")
|
||||
print(" both search criteria, whereas query() applies filters sequentially which may not optimize ranking.")
|
||||
|
||||
print("\n" + "=" * 100)
|
||||
print("SCENARIO 5: Result Quality - RRF Fusion")
|
||||
print("=" * 100)
|
||||
print("Goal: Search for 'Python machine learning'\n")
|
||||
|
||||
# query() - single ranking
|
||||
query_result5 = collection.query(
|
||||
query_texts=["Python machine learning"],
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# hybrid_search() - RRF fusion of multiple rankings
|
||||
hybrid_result5 = collection.hybrid_search(
|
||||
query={"where_document": {"$contains": "Python"}, "n_results": 10},
|
||||
knn={"query_texts": ["Python machine learning"], "n_results": 10},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
print("query() Results (single ranking):")
|
||||
for i, doc_id in enumerate(query_result5['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
|
||||
print("\nhybrid_search() Results (RRF fusion):")
|
||||
for i, doc_id in enumerate(hybrid_result5['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
|
||||
print("\nAnalysis:")
|
||||
print(" Both methods return identical results in this case, but hybrid_search() achieves this through RRF")
|
||||
print(" (Reciprocal Rank Fusion) which combines rankings from full-text search (for 'Python') and vector")
|
||||
print(" search (for 'Python machine learning'). RRF provides more stable and robust ranking by considering")
|
||||
print(" multiple signals, making it less sensitive to variations in individual search algorithms and ensuring")
|
||||
print(" consistent high-quality results across different query formulations.")
|
||||
|
||||
print("\n" + "=" * 100)
|
||||
print("SCENARIO 6: Different Filter Criteria for Each Search")
|
||||
print("=" * 100)
|
||||
print("Goal: Full-text='neural' (high popularity) + Vector='deep learning' (recent year)\n")
|
||||
|
||||
# query() - cannot separate filters for keyword vs semantic
|
||||
query_result6 = collection.query(
|
||||
query_texts=["deep learning"],
|
||||
where={"popularity": {"$gte": 90}, "year": {"$gte": 2023}},
|
||||
where_document={"$contains": "neural"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# hybrid_search() - different filters for keyword search vs semantic search
|
||||
hybrid_result6 = collection.hybrid_search(
|
||||
query={"where_document": {"$contains": "neural"}, "where": {"popularity": {"$gte": 90}}, "n_results": 10},
|
||||
knn={"query_texts": ["deep learning"], "where": {"year": {"$gte": 2023}}, "n_results": 10},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
print("query() Results:")
|
||||
for i, doc_id in enumerate(query_result6['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
print(f" {metadatas[idx]}")
|
||||
|
||||
print("\nhybrid_search() Results:")
|
||||
for i, doc_id in enumerate(hybrid_result6['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
print(f" {metadatas[idx]}")
|
||||
|
||||
print("\nAnalysis:")
|
||||
print(" query() only returns 2 results because it requires documents to satisfy BOTH popularity>=90 AND")
|
||||
print(" year>=2023 simultaneously, along with containing 'neural' and being semantically similar to")
|
||||
print(" 'deep learning'. hybrid_search() returns 5 results by applying popularity>=90 filter to full-text")
|
||||
print(" search (for 'neural') and year>=2023 filter to vector search (for 'deep learning') independently.")
|
||||
print(" The fusion then combines results from both searches, capturing documents that strongly match either")
|
||||
print(" criterion while still being relevant to the overall query intent.")
|
||||
|
||||
print("\n" + "=" * 100)
|
||||
print("SCENARIO 7: Partial Keyword Match + Semantic Similarity")
|
||||
print("=" * 100)
|
||||
print("Goal: Documents containing 'Python' + Semantically similar to 'data science'\n")
|
||||
|
||||
# query() - filter applied after vector search
|
||||
query_result7 = collection.query(
|
||||
query_texts=["data science"],
|
||||
where_document={"$contains": "Python"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# hybrid_search() - parallel searches then fusion
|
||||
hybrid_result7 = collection.hybrid_search(
|
||||
query={"where_document": {"$contains": "Python"}, "n_results": 10},
|
||||
knn={"query_texts": ["data science"], "n_results": 10},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
print("query() Results:")
|
||||
for i, doc_id in enumerate(query_result7['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
|
||||
print("\nhybrid_search() Results:")
|
||||
for i, doc_id in enumerate(hybrid_result7['ids'][0]):
|
||||
idx = ids.index(doc_id)
|
||||
print(f" {i+1}. {documents[idx]}")
|
||||
|
||||
print("\nAnalysis:")
|
||||
print(" query() only returns 2 results because it first performs vector search for 'data science', then")
|
||||
print(" filters to documents containing 'Python', which severely limits the result set. hybrid_search()")
|
||||
print(" returns 5 results by running full-text search (for 'Python') and vector search (for 'data science')")
|
||||
print(" in parallel, then fusing the results. This captures documents that contain 'Python' (even if not")
|
||||
print(" semantically closest to 'data science') and documents semantically similar to 'data science' (even")
|
||||
print(" if they don't contain 'Python'), providing better recall and more comprehensive results.")
|
||||
|
||||
print("\n" + "=" * 100)
|
||||
print("SUMMARY")
|
||||
print("=" * 100)
|
||||
print("""
|
||||
query() limitations:
|
||||
- Single search type (vector similarity)
|
||||
- Filters applied after search (may miss relevant docs)
|
||||
- Cannot combine full-text and vector search results
|
||||
- Same filter criteria for all conditions
|
||||
|
||||
hybrid_search() advantages:
|
||||
- Simultaneous full-text + vector search
|
||||
- Independent filters for each search type
|
||||
- Intelligent result fusion using RRF
|
||||
- Better recall for complex queries
|
||||
- Handles scenarios requiring both keyword and semantic matching
|
||||
""")
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* For information about the APIs supported by pyseekdb, see [API Reference](../../50.apis/10.api-overview.md).
|
||||
|
||||
* [Simple example](10.pyseekdb-simple-sample.md)
|
||||
|
||||
* [Complete example](50.pyseekdb-complete-sample.md)
|
||||
@@ -0,0 +1,440 @@
|
||||
---
|
||||
slug: /pyseekdb-complete-sample
|
||||
---
|
||||
|
||||
# Complete Example
|
||||
|
||||
This example demonstrates the full capabilities of pyseekdb.
|
||||
|
||||
The example includes the following operations:
|
||||
|
||||
1. Connection, including all connection modes
|
||||
2. Collection management
|
||||
3. DML operations, including add, update, upsert, and delete
|
||||
4. DQL operations, including query, get, and hybrid_search
|
||||
5. Filter operators
|
||||
6. Collection information methods
|
||||
|
||||
## Example
|
||||
|
||||
```python
|
||||
import uuid
|
||||
import random
|
||||
import pyseekdb
|
||||
|
||||
# ============================================================================
|
||||
# PART 1: CLIENT CONNECTION
|
||||
# ============================================================================
|
||||
|
||||
# Option 1: Embedded mode (local SeekDB)
|
||||
client = pyseekdb.Client(
|
||||
#path="./seekdb",
|
||||
#database="test"
|
||||
)
|
||||
|
||||
# Option 2: Server mode (remote SeekDB server)
|
||||
# client = pyseekdb.Client(
|
||||
# host="127.0.0.1",
|
||||
# port=2881,
|
||||
# database="test",
|
||||
# user="root",
|
||||
# password=""
|
||||
# )
|
||||
|
||||
# Option 3: Remote server mode (OceanBase Server)
|
||||
# client = pyseekdb.Client(
|
||||
# host="127.0.0.1",
|
||||
# port=2881,
|
||||
# tenant="test", # OceanBase default tenant
|
||||
# database="test",
|
||||
# user="root",
|
||||
# password=""
|
||||
# )
|
||||
|
||||
# ============================================================================
|
||||
# PART 2: COLLECTION MANAGEMENT
|
||||
# ============================================================================
|
||||
|
||||
collection_name = "comprehensive_example"
|
||||
dimension = 128
|
||||
|
||||
# 2.1 Create a collection
|
||||
from pyseekdb import HNSWConfiguration
|
||||
config = HNSWConfiguration(dimension=dimension, distance='cosine')
|
||||
collection = client.get_or_create_collection(
|
||||
name=collection_name,
|
||||
configuration=config,
|
||||
embedding_function=None # Explicitly set to None since we're using custom 128-dim embeddings
|
||||
)
|
||||
|
||||
# 2.2 Check if collection exists
|
||||
exists = client.has_collection(collection_name)
|
||||
|
||||
# 2.3 Get collection object
|
||||
retrieved_collection = client.get_collection(collection_name, embedding_function=None)
|
||||
|
||||
# 2.4 List all collections
|
||||
all_collections = client.list_collections()
|
||||
|
||||
# 2.5 Get or create collection (creates if doesn't exist)
|
||||
config2 = HNSWConfiguration(dimension=64, distance='cosine')
|
||||
collection2 = client.get_or_create_collection(
|
||||
name="another_collection",
|
||||
configuration=config2,
|
||||
embedding_function=None # Explicitly set to None since we're using custom 64-dim embeddings
|
||||
)
|
||||
|
||||
# ============================================================================
|
||||
# PART 3: DML OPERATIONS - ADD DATA
|
||||
# ============================================================================
|
||||
|
||||
# Generate sample data
|
||||
random.seed(42)
|
||||
documents = [
|
||||
"Machine learning is transforming the way we solve problems",
|
||||
"Python programming language is widely used in data science",
|
||||
"Vector databases enable efficient similarity search",
|
||||
"Neural networks mimic the structure of the human brain",
|
||||
"Natural language processing helps computers understand human language",
|
||||
"Deep learning requires large amounts of training data",
|
||||
"Reinforcement learning agents learn through trial and error",
|
||||
"Computer vision enables machines to interpret visual information"
|
||||
]
|
||||
|
||||
# Generate embeddings (in real usage, use an embedding model)
|
||||
embeddings = []
|
||||
for i in range(len(documents)):
|
||||
vector = [random.random() for _ in range(dimension)]
|
||||
embeddings.append(vector)
|
||||
|
||||
ids = [str(uuid.uuid4()) for _ in documents]
|
||||
|
||||
# 3.1 Add single item
|
||||
single_id = str(uuid.uuid4())
|
||||
collection.add(
|
||||
ids=single_id,
|
||||
documents="This is a single document",
|
||||
embeddings=[random.random() for _ in range(dimension)],
|
||||
metadatas={"type": "single", "category": "test"}
|
||||
)
|
||||
|
||||
# 3.2 Add multiple items
|
||||
collection.add(
|
||||
ids=ids,
|
||||
documents=documents,
|
||||
embeddings=embeddings,
|
||||
metadatas=[
|
||||
{"category": "AI", "score": 95, "tag": "ml", "year": 2023},
|
||||
{"category": "Programming", "score": 88, "tag": "python", "year": 2022},
|
||||
{"category": "Database", "score": 92, "tag": "vector", "year": 2023},
|
||||
{"category": "AI", "score": 90, "tag": "neural", "year": 2022},
|
||||
{"category": "NLP", "score": 87, "tag": "language", "year": 2023},
|
||||
{"category": "AI", "score": 93, "tag": "deep", "year": 2023},
|
||||
{"category": "AI", "score": 85, "tag": "reinforcement", "year": 2022},
|
||||
{"category": "CV", "score": 91, "tag": "vision", "year": 2023}
|
||||
]
|
||||
)
|
||||
|
||||
# 3.3 Add with only embeddings (no documents)
|
||||
vector_only_ids = [str(uuid.uuid4()) for _ in range(2)]
|
||||
collection.add(
|
||||
ids=vector_only_ids,
|
||||
embeddings=[[random.random() for _ in range(dimension)] for _ in range(2)],
|
||||
metadatas=[{"type": "vector_only"}, {"type": "vector_only"}]
|
||||
)
|
||||
|
||||
# ============================================================================
|
||||
# PART 4: DML OPERATIONS - UPDATE DATA
|
||||
# ============================================================================
|
||||
|
||||
# 4.1 Update single item
|
||||
collection.update(
|
||||
ids=ids[0],
|
||||
metadatas={"category": "AI", "score": 98, "tag": "ml", "year": 2024, "updated": True}
|
||||
)
|
||||
|
||||
# 4.2 Update multiple items
|
||||
collection.update(
|
||||
ids=ids[1:3],
|
||||
documents=["Updated document 1", "Updated document 2"],
|
||||
embeddings=[[random.random() for _ in range(dimension)] for _ in range(2)],
|
||||
metadatas=[
|
||||
{"category": "Programming", "score": 95, "updated": True},
|
||||
{"category": "Database", "score": 97, "updated": True}
|
||||
]
|
||||
)
|
||||
|
||||
# 4.3 Update embeddings
|
||||
new_embeddings = [[random.random() for _ in range(dimension)] for _ in range(2)]
|
||||
collection.update(
|
||||
ids=ids[2:4],
|
||||
embeddings=new_embeddings
|
||||
)
|
||||
|
||||
# ============================================================================
|
||||
# PART 5: DML OPERATIONS - UPSERT DATA
|
||||
# ============================================================================
|
||||
|
||||
# 5.1 Upsert existing item (will update)
|
||||
collection.upsert(
|
||||
ids=ids[0],
|
||||
documents="Upserted document (was updated)",
|
||||
embeddings=[random.random() for _ in range(dimension)],
|
||||
metadatas={"category": "AI", "upserted": True}
|
||||
)
|
||||
|
||||
# 5.2 Upsert new item (will insert)
|
||||
new_id = str(uuid.uuid4())
|
||||
collection.upsert(
|
||||
ids=new_id,
|
||||
documents="This is a new document from upsert",
|
||||
embeddings=[random.random() for _ in range(dimension)],
|
||||
metadatas={"category": "New", "upserted": True}
|
||||
)
|
||||
|
||||
# 5.3 Upsert multiple items
|
||||
upsert_ids = [ids[4], str(uuid.uuid4())] # One existing, one new
|
||||
collection.upsert(
|
||||
ids=upsert_ids,
|
||||
documents=["Upserted doc 1", "Upserted doc 2"],
|
||||
embeddings=[[random.random() for _ in range(dimension)] for _ in range(2)],
|
||||
metadatas=[{"upserted": True}, {"upserted": True}]
|
||||
)
|
||||
|
||||
# ============================================================================
|
||||
# PART 6: DQL OPERATIONS - QUERY (VECTOR SIMILARITY SEARCH)
|
||||
# ============================================================================
|
||||
|
||||
# 6.1 Basic vector similarity query
|
||||
query_vector = embeddings[0] # Query with first document's vector
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
n_results=3
|
||||
)
|
||||
print(f"Query results: {len(results['ids'][0])} items")
|
||||
|
||||
# 6.2 Query with metadata filter (simplified equality)
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
where={"category": "AI"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# 6.3 Query with comparison operators
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
where={"score": {"$gte": 90}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# 6.4 Query with $in operator
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
where={"tag": {"$in": ["ml", "python", "neural"]}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# 6.5 Query with logical operators ($or) - simplified equality
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
where={
|
||||
"$or": [
|
||||
{"category": "AI"},
|
||||
{"tag": "python"}
|
||||
]
|
||||
},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# 6.6 Query with logical operators ($and) - simplified equality
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
where={
|
||||
"$and": [
|
||||
{"category": "AI"},
|
||||
{"score": {"$gte": 90}}
|
||||
]
|
||||
},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# 6.7 Query with document filter
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
where_document={"$contains": "machine learning"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# 6.8 Query with combined filters (simplified equality)
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
where={"category": "AI", "year": {"$gte": 2023}},
|
||||
where_document={"$contains": "learning"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# 6.9 Query with multiple embeddings (batch query)
|
||||
batch_embeddings = [embeddings[0], embeddings[1]]
|
||||
batch_results = collection.query(
|
||||
query_embeddings=batch_embeddings,
|
||||
n_results=2
|
||||
)
|
||||
# batch_results["ids"][0] contains results for first query
|
||||
# batch_results["ids"][1] contains results for second query
|
||||
|
||||
# 6.10 Query with specific fields
|
||||
results = collection.query(
|
||||
query_embeddings=query_vector,
|
||||
include=["documents", "metadatas", "embeddings"],
|
||||
n_results=2
|
||||
)
|
||||
|
||||
# ============================================================================
|
||||
# PART 7: DQL OPERATIONS - GET (RETRIEVE BY IDS OR FILTERS)
|
||||
# ============================================================================
|
||||
|
||||
# 7.1 Get by single ID
|
||||
result = collection.get(ids=ids[0])
|
||||
# result["ids"] contains [ids[0]]
|
||||
# result["documents"] contains document for ids[0]
|
||||
|
||||
# 7.2 Get by multiple IDs
|
||||
results = collection.get(ids=ids[:3])
|
||||
# results["ids"] contains ids[:3]
|
||||
# results["documents"] contains documents for all IDs
|
||||
|
||||
# 7.3 Get by metadata filter (simplified equality)
|
||||
results = collection.get(
|
||||
where={"category": "AI"},
|
||||
limit=5
|
||||
)
|
||||
|
||||
# 7.4 Get with comparison operators
|
||||
results = collection.get(
|
||||
where={"score": {"$gte": 90}},
|
||||
limit=5
|
||||
)
|
||||
|
||||
# 7.5 Get with $in operator
|
||||
results = collection.get(
|
||||
where={"tag": {"$in": ["ml", "python"]}},
|
||||
limit=5
|
||||
)
|
||||
|
||||
# 7.6 Get with logical operators (simplified equality)
|
||||
results = collection.get(
|
||||
where={
|
||||
"$or": [
|
||||
{"category": "AI"},
|
||||
{"category": "Programming"}
|
||||
]
|
||||
},
|
||||
limit=5
|
||||
)
|
||||
|
||||
# 7.7 Get by document filter
|
||||
results = collection.get(
|
||||
where_document={"$contains": "Python"},
|
||||
limit=5
|
||||
)
|
||||
|
||||
# 7.8 Get with pagination
|
||||
results_page1 = collection.get(limit=2, offset=0)
|
||||
results_page2 = collection.get(limit=2, offset=2)
|
||||
|
||||
# 7.9 Get with specific fields
|
||||
results = collection.get(
|
||||
ids=ids[:2],
|
||||
include=["documents", "metadatas", "embeddings"]
|
||||
)
|
||||
|
||||
# 7.10 Get all data
|
||||
all_results = collection.get(limit=100)
|
||||
|
||||
# ============================================================================
|
||||
# PART 8: DQL OPERATIONS - HYBRID SEARCH
|
||||
# ============================================================================
|
||||
|
||||
# 8.1 Hybrid search with full-text and vector search
|
||||
# Note: This requires query_embeddings to be provided directly
|
||||
# In real usage, you might have an embedding function
|
||||
hybrid_results = collection.hybrid_search(
|
||||
query={
|
||||
"where_document": {"$contains": "machine learning"},
|
||||
"where": {"category": "AI"}, # Simplified equality
|
||||
"n_results": 10
|
||||
},
|
||||
knn={
|
||||
"query_embeddings": [embeddings[0]],
|
||||
"where": {"year": {"$gte": 2022}},
|
||||
"n_results": 10
|
||||
},
|
||||
rank={"rrf": {}}, # Reciprocal Rank Fusion
|
||||
n_results=5,
|
||||
include=["documents", "metadatas"]
|
||||
)
|
||||
# hybrid_results["ids"][0] contains IDs for the hybrid search
|
||||
# hybrid_results["documents"][0] contains documents for the hybrid search
|
||||
print(f"Hybrid search: {len(hybrid_results.get('ids', [[]])[0])} results")
|
||||
|
||||
# ============================================================================
|
||||
# PART 9: DML OPERATIONS - DELETE DATA
|
||||
# ============================================================================
|
||||
|
||||
# 9.1 Delete by IDs
|
||||
delete_ids = [vector_only_ids[0], new_id]
|
||||
collection.delete(ids=delete_ids)
|
||||
|
||||
# 9.2 Delete by metadata filter
|
||||
collection.delete(where={"type": {"$eq": "vector_only"}})
|
||||
|
||||
# 9.3 Delete by document filter
|
||||
collection.delete(where_document={"$contains": "Updated document"})
|
||||
|
||||
# 9.4 Delete with combined filters
|
||||
collection.delete(
|
||||
where={"category": {"$eq": "CV"}},
|
||||
where_document={"$contains": "vision"}
|
||||
)
|
||||
|
||||
# ============================================================================
|
||||
# PART 10: COLLECTION INFORMATION
|
||||
# ============================================================================
|
||||
|
||||
# 10.1 Get collection count
|
||||
count = collection.count()
|
||||
print(f"Collection count: {count} items")
|
||||
|
||||
|
||||
# 10.3 Preview first few items in collection (returns all columns by default)
|
||||
preview = collection.peek(limit=5)
|
||||
print(f"Preview: {len(preview['ids'])} items")
|
||||
for i in range(len(preview['ids'])):
|
||||
print(f" ID: {preview['ids'][i]}, Document: {preview['documents'][i]}")
|
||||
print(f" Metadata: {preview['metadatas'][i]}, Embedding dim: {len(preview['embeddings'][i]) if preview['embeddings'][i] else 0}")
|
||||
|
||||
# 10.4 Count collections in database
|
||||
collection_count = client.count_collection()
|
||||
print(f"Database has {collection_count} collections")
|
||||
|
||||
# ============================================================================
|
||||
# PART 11: CLEANUP
|
||||
# ============================================================================
|
||||
|
||||
# Delete test collections
|
||||
try:
|
||||
client.delete_collection("another_collection")
|
||||
except Exception as e:
|
||||
print(f"Could not delete 'another_collection': {e}")
|
||||
|
||||
# Uncomment to delete main collection
|
||||
client.delete_collection(collection_name)
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* For information about the API interfaces supported by pyseekdb, see [API Reference](../../50.apis/10.api-overview.md).
|
||||
|
||||
* [Simple Example](../50.sdk-samples/10.pyseekdb-simple-sample.md)
|
||||
|
||||
* [Hybrid Search Example](../50.sdk-samples/100.pyseekdb-hybrid-search-sample.md)
|
||||
@@ -0,0 +1,66 @@
|
||||
---
|
||||
slug: /api-overview
|
||||
---
|
||||
|
||||
# API Reference
|
||||
|
||||
seekdb allows you to use seekdb through APIs.
|
||||
|
||||
## APIs
|
||||
|
||||
The following APIs are supported.
|
||||
|
||||
### Database
|
||||
|
||||
:::info
|
||||
You can use this API only when you connect to seekdb by using the `AdminClient`. For more information about the `AdminClient`, see [Admin Client](../50.apis/100.admin-client.md).
|
||||
:::
|
||||
|
||||
| API | Description | Documentation |
|
||||
|---|---|---|
|
||||
| `create_database()` | Creates a database. | [Documentation](110.database/200.create-database-of-api.md) |
|
||||
| `get_database()` | Retrieves a specified database. |[Documentation](110.database/300.get-database-of-api.md)|
|
||||
| `list_databases()` | Retrieves a list of databases in an instance. |[Documentation](110.database/400.list-database-of-api.md)|
|
||||
| `delete_database()` | Deletes a specified database.|[Documentation](110.database/500.delete-database-of-api.md)|
|
||||
|
||||
|
||||
### Collection
|
||||
|
||||
:::info
|
||||
You can use this API only when you connect to seekdb by using the `Client`. For more information about the `Client`, see [Client](../50.apis/50.client.md).
|
||||
:::
|
||||
|
||||
| API | Description | Documentation |
|
||||
|---|---|---|
|
||||
| `create_collection()` | Creates a collection. | [Documentation](200.collection/100.create-collection-of-api.md) |
|
||||
| `get_collection()` | Retrieves a specified collection. |[Documentation](200.collection/200.get-collection-of-api.md)|
|
||||
| `get_or_create_collection()` | Creates or queries a collection. If the collection does not exist in the database, it is created. If the collection exists, the corresponding result is obtained. |[Documentation](200.collection/250.get-or-create-collection-of-api.md)|
|
||||
| `list_collections()` | Retrieves the collection list in a database. |[Documentation](200.collection/300.list-collection-of-api.md)|
|
||||
| `count_collection()` | Counts the number of collections in a database. |[Documentation](200.collection/350.count-collection-of-api.md)|
|
||||
| `delete_collection()` | Deletes a specified collection.|[Documentation](200.collection/400.delete-collection-of-api.md)|
|
||||
|
||||
|
||||
### DML
|
||||
|
||||
:::info
|
||||
You can use this API only when you connect to seekdb by using the `Client`. For more information about the `Client`, see [Client](../50.apis/50.client.md).
|
||||
:::
|
||||
|
||||
| API | Description | Documentation |
|
||||
|---|---|---|
|
||||
| `add()` | Inserts a new record into a collection. | [Documentation](300.dml/200.add-data-of-api.md) |
|
||||
| `update()` | Updates an existing record in a collection. |[Documentation](300.dml/300.update-data-of-api.md)|
|
||||
| `upsert()` | Inserts a new record or updates an existing record. |[Documentation](300.dml/400.upsert-data-of-api.md)|
|
||||
| `delete()` | Deletes a record from a collection.|[Documentation](300.dml/500.delete-data-of-api.md)|
|
||||
|
||||
### DQL
|
||||
|
||||
:::info
|
||||
You can use this API only when you connect to seekdb by using the `Client`. For more information about the `Client`, see [Client](../50.apis/50.client.md).
|
||||
:::
|
||||
|
||||
| API | Description | Documentation |
|
||||
|---|---|---|
|
||||
| `query()` | Performs vector similarity search. | [Documentation](400.dql/200.query-interfaces-of-api.md) |
|
||||
| `get()` | Queries specific data from a table by using the ID, document, and metadata (non-vector). |[Documentation](400.dql/300.get-interfaces-of-api.md)|
|
||||
| `hybrid_search()` | Performs full-text search and vector similarity search by using ranking. |[Documentation](400.dql/400.hybrid-search-of-api.md)|
|
||||
@@ -0,0 +1,93 @@
|
||||
---
|
||||
slug: /admin-client
|
||||
---
|
||||
|
||||
# Admin Client
|
||||
|
||||
`AdminClient` provides database management operations. It uses the same database connection mode as `Client`, but only supports database management-related operations.
|
||||
|
||||
## Connect to an embedded seekdb instance
|
||||
|
||||
Connect to a local embedded seekdb instance by using `AdminClient`.
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Embedded mode - Database management
|
||||
admin = pyseekdb.AdminClient(path="./seekdb")
|
||||
```
|
||||
|
||||
Parameter description:
|
||||
|
||||
| Parameter | Value Type | Required | Description | Example Value |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| `path` | string | Optional | The path of the seekdb data directory. seekdb stores database files in this directory and loads them when it starts. | `./seekdb` |
|
||||
|
||||
## Connect to a remote server
|
||||
|
||||
Connect to a remote server by using `AdminClient`. This way, you can connect to a seekdb instance or an OceanBase Database instance.
|
||||
|
||||
:::tip
|
||||
|
||||
Before you connect to a remote server, make sure that you have deployed a server mode seekdb instance or an OceanBase Database instance.<br/>For information about how to deploy a server mode seekdb instance, see [Overview](../../../400.guides/400.deploy/50.deploy-overview.md).<br/>For information about how to deploy an OceanBase Database instance, see [Overview](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003976427).
|
||||
|
||||
:::
|
||||
|
||||
Example: Connect to a server mode seekdb instance
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Remote server mode - Database management
|
||||
admin = pyseekdb.AdminClient(
|
||||
host="127.0.0.1",
|
||||
port=2881,
|
||||
user="root",
|
||||
password="" # Can be retrieved from SEEKDB_PASSWORD environment variable
|
||||
)
|
||||
```
|
||||
|
||||
Parameter description:
|
||||
|
||||
| Parameter | Value Type | Required | Description | Example Value |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| `host` | string | Yes | The IP address of the server where the instance resides. | `127.0.0.1` |
|
||||
| `prot` | string | Yes | The port of the instance. The default value is 2881. | `2881` |
|
||||
| `user` | string | Yes | The username. The default value is root. | `root` |
|
||||
| `password` | string | Yes | The password corresponding to the username. If you do not specify `password` or specify an empty string, the system retrieves the password from the `SEEKDB_PASSWORD` environment variable. | |
|
||||
|
||||
Example: Connect to an OceanBase Database instance
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Remote server mode - Database management
|
||||
admin = pyseekdb.AdminClient(
|
||||
host="127.0.0.1",
|
||||
port=2881,
|
||||
tenant="test"
|
||||
user="root",
|
||||
password="" # Can be retrieved from SEEKDB_PASSWORD environment variable
|
||||
)
|
||||
```
|
||||
|
||||
Parameter description:
|
||||
|
||||
| Parameter | Value Type | Required | Description | Example Value |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| `host` | string | Yes | The IP address of the server where the database resides. | `127.0.0.1` |
|
||||
| `prot` | string | Yes | The port of the OceanBase Database instance. The default value is 2881. | `2881` |
|
||||
| `tenant` | string | No | The name of the tenant. This parameter is not required for a server mode seekdb instance, but is required for an OceanBase Database instance. The default value is sys. | `test` |
|
||||
| `user` | string | Yes | The username corresponding to the tenant. The default value is root. | `root` |
|
||||
| `password` | string | Yes | The password corresponding to the username. If you do not specify `password` or specify an empty string, the system retrieves the password from the `SEEKDB_PASSWORD` environment variable. | |
|
||||
|
||||
## APIs supported when you use AdminClient to connect to a database
|
||||
|
||||
The following APIs are supported when you use `AdminClient` to connect to a database.
|
||||
|
||||
| API | Description | Documentation Link |
|
||||
| --- | --- | --- |
|
||||
| `create_database` | Creates a new database. |[Documentation](110.database/200.create-database-of-api.md)|
|
||||
| `get_database` | Queries a specified database. |[Documentation](110.database/300.get-database-of-api.md)|
|
||||
| `delete_database` | Deletes a specified database. |[Documentation](110.database/400.list-database-of-api.md)|
|
||||
| `list_databases` | Lists all databases. |[Documentation](110.database/500.delete-database-of-api.md)|
|
||||
@@ -0,0 +1,16 @@
|
||||
---
|
||||
slug: /database-overview-of-api
|
||||
---
|
||||
|
||||
# Database Management
|
||||
|
||||
A database contains tables, indexes, and metadata of database objects. You can create, query, and delete databases as needed.
|
||||
|
||||
The following APIs are available for database operations.
|
||||
|
||||
| API | Description | Documentation |
|
||||
|---|---|---|
|
||||
| `create_database()` | Creates a database. | [Documentation](200.create-database-of-api.md) |
|
||||
| `get_database()` | Gets a specified database. |[Documentation](300.get-database-of-api.md)|
|
||||
| `list_databases()` | Gets the list of databases in the instance. |[Documentation](400.list-database-of-api.md)|
|
||||
| `delete_database()` | Deletes a specified database.|[Documentation](500.delete-database-of-api.md)|
|
||||
@@ -0,0 +1,76 @@
|
||||
---
|
||||
slug: /create-database-of-api
|
||||
---
|
||||
|
||||
# create_database - Create a database
|
||||
|
||||
The `create_database()` function is used to create a new database.
|
||||
|
||||
:::info
|
||||
* This interface can only be used when you are connected to the database using `AdminClient`. For more information about `AdminClient`, see [Admin Client](../100.admin-client.md).
|
||||
|
||||
* Currently, when you use `create_database` to create a database, you cannot specify the database properties. The database will be created based on the default values of the properties. If you want to create a database with specific properties, you can try to create it using SQL. For more information about how to create a database using SQL, see [Create a database](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003977077).
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Get Started](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You are connected to the database. For more information about how to connect to the database, see [Admin Client](../100.admin-client.md).
|
||||
|
||||
* If you are using server mode of seekdb or OceanBase Database, make sure that the connected user has the `CREATE` privilege. For more information about how to check the privileges of the current user, see [View user privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980135). If the user does not have this privilege, contact the administrator to grant it. For more information about how to directly grant privileges, see [Directly grant privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980140).
|
||||
|
||||
## Limitations
|
||||
|
||||
* In a seekdb instance or OceanBase Database, the name of each database must be globally unique.
|
||||
|
||||
* The maximum length of a database name is 128 characters.
|
||||
|
||||
* The name can contain only uppercase and lowercase letters, digits, underscores, dollar signs, and Chinese characters.
|
||||
|
||||
* Avoid using reserved keywords as database names.
|
||||
|
||||
For more information about reserved keywords, see [Reserved keywords](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003976774).
|
||||
|
||||
## Recommendations
|
||||
|
||||
* We recommend that you give the database a meaningful name that reflects its purpose and content. For example, you can use `Application Identifier_Sub-application name (optional)_db` as the database name.
|
||||
|
||||
* We recommend that you create the database and related users using the root user and assign only the necessary privileges to ensure the security and controllability of the database.
|
||||
|
||||
* You can create a database with a name consisting only of digits by enclosing the name in backticks (`), but this is not recommended. This is because names consisting only of digits have no clear meaning, and queries require the use of backticks (`), which can lead to unnecessary complexity and confusion.
|
||||
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
create_database(name, tenant=DEFAULT_TENANT)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the database to be created. |`my_database`|
|
||||
|`tenant`|string|No<ul><li>When using embedded seekdb or server mode of seekdb, this parameter is not required.</li><li>When using OceanBase Database, this parameter is required.</li></ul>|The tenant to which the database belongs. |`test_tenant`|
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Embedded mode
|
||||
admin = pyseekdb.AdminClient(path="./seekdb")
|
||||
|
||||
# Create database
|
||||
admin.create_database("my_database")
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
|
||||
## References
|
||||
|
||||
* [Get a specific database](300.get-database-of-api.md)
|
||||
* [Delete a database](500.delete-database-of-api.md)
|
||||
* [List databases](400.list-database-of-api.md)
|
||||
@@ -0,0 +1,65 @@
|
||||
---
|
||||
slug: /get-database-of-api
|
||||
---
|
||||
|
||||
# get_database - Get the specified database
|
||||
|
||||
The `get_database()` method is used to obtain the information of the specified database.
|
||||
|
||||
:::info
|
||||
|
||||
This method can be used only when you connect to the database by using the `AdminClient`. For more information about the `AdminClient`, see [Admin Client](../100.admin-client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect to the database, see [Admin Client](../100.admin-client.md).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
get_database(name, tenant=DEFAULT_TENANT)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the database to be queried. |`my_database`|
|
||||
|`tenant`|string|No<ul><li>When you use embedded seekdb and server mode seekdb, you do not need to specify this parameter.</li><li>When you use OceanBase Database, you must specify this parameter.</li></ul>|The tenant to which the database belongs. |test_tenant|
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Embedded mode
|
||||
admin = pyseekdb.AdminClient(path="./seekdb")
|
||||
|
||||
# Get database
|
||||
db = admin.get_database("my_database")
|
||||
# print(f"Database: {db.name}, Charset: {db.charset}, collation:{db.collation}, metadata:{db.metadata}")
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the queried database. |`my_database`|
|
||||
|`tenant`|string|No<br/>When you use embedded seekdb and server mode SeekDB, this parameter does not exist. |The tenant to which the queried database belongs. |`test_tenant`|
|
||||
|`charset`|string|No|The character set used by the queried database. |`utf8mb4`|
|
||||
|`collation`|string|No|The collation used by the queried database. |`utf8mb4_general_ci`|
|
||||
|`metadata`|dict|No|Reserved field. | {} |
|
||||
|
||||
## Response example
|
||||
|
||||
```python
|
||||
Database: my_database, Charset: utf8mb4, collation:utf8mb4_general_ci, metadata:{}
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Create a database](200.create-database-of-api.md)
|
||||
* [Delete a database](500.delete-database-of-api.md)
|
||||
* [Get the database list](400.list-database-of-api.md)
|
||||
@@ -0,0 +1,70 @@
|
||||
---
|
||||
slug: /list-database-of-api
|
||||
---
|
||||
|
||||
# list_databases - Get the database list
|
||||
|
||||
The `list_databases()` method is used to retrieve the database list in the instance.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when using the `AdminClient`. For more information about the `AdminClient`, see [Admin Client](../100.admin-client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect to the database, see [Admin Client](../100.admin-client.md).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
list_databases(limit=None, offset=None, tenant=DEFAULT_TENANT)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`limit`|int|Optional|The maximum number of databases to return. |2|
|
||||
|`offset`|int|Optional|The number of databases to skip. |3|
|
||||
|`tenant`|string|Optional<ul><li>When using embedded seekdb and server mode seekdb, this parameter is not required.</li><li>When using OceanBase Database, this parameter is required. The default value is `sys`.</li></ul>|The tenant to which the queried database belongs. |test_tenant|
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
# List all databases
|
||||
import pyseekdb
|
||||
|
||||
# Embedded mode
|
||||
admin = pyseekdb.AdminClient(path="./seekdb")
|
||||
|
||||
# list database
|
||||
databases = admin.list_databases(2,3)
|
||||
for db in databases:
|
||||
print(f"Database: {db.name}, Charset: {db.charset}, collation:{db.collation}, metadata:{db.metadata}")
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the queried database. |`my_database`|
|
||||
|`tenant`|string|Optional<br/>When using embedded seekdb and server mode SeekDB, this parameter is not available. |The tenant to which the queried database belongs. |`test_tenant`|
|
||||
|`charset`|string|Optional|The character set of the queried database. |`utf8mb4`|
|
||||
|`collation`|string|Optional|The collation of the queried database. |`utf8mb4_general_ci`|
|
||||
|`metadata`|dict|Optional|Reserved field. No data is returned. | {} |
|
||||
|
||||
|
||||
## Response example
|
||||
|
||||
```python
|
||||
Database: test, Charset: utf8mb4, collation:utf8mb4_general_ci, metadata:{}
|
||||
Database: my_database, Charset: utf8mb4, collation:utf8mb4_general_ci, metadata:{}
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Create a database](200.create-database-of-api.md)
|
||||
* [Delete a database](500.delete-database-of-api.md)
|
||||
* [Get a specific database](300.get-database-of-api.md)
|
||||
@@ -0,0 +1,54 @@
|
||||
---
|
||||
slug: /delete-database-of-api
|
||||
---
|
||||
|
||||
# delete_database - Delete a database
|
||||
|
||||
The `delete_database()` method is used to delete a database.
|
||||
|
||||
:::info
|
||||
|
||||
This method is only available when using the `AdminClient`. For more information about the `AdminClient`, see [Admin Client](../100.admin-client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect to the database, see [Admin Client](../100.admin-client.md).
|
||||
|
||||
* If you are using server mode of seekdb or OceanBase Database, ensure that the user has the `DROP` privilege. For more information about how to view the privileges of the current user, see [View User Privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980135). If the user does not have the privilege, contact the administrator to grant the privilege. For more information about how to directly grant privileges, see [Directly Grant Privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980140).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
delete_database(name,tenant=DEFAULT_TENANT)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example Value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the database to be deleted. |my_database|
|
||||
|`tenant`|string|No<ul><li>If you are using embedded seekdb or server mode of seekdb, you do not need to specify this parameter.</li><li>If you are using OceanBase Database, this parameter is required. The default value is `sys`.</li></ul>|The tenant to which the database belongs. |test_tenant|
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Embedded mode
|
||||
admin = pyseekdb.AdminClient(path="./seekdb")
|
||||
|
||||
# Delete database
|
||||
admin.delete_database("my_database")
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
## References
|
||||
|
||||
* [Create a database](200.create-database-of-api.md)
|
||||
* [Get a specific database](300.get-database-of-api.md)
|
||||
* [Obtain a database list](400.list-database-of-api.md)
|
||||
@@ -0,0 +1,93 @@
|
||||
---
|
||||
slug: /create-collection-of-api
|
||||
---
|
||||
|
||||
# create_collection - Create a collection
|
||||
|
||||
`create_collection()` is used to create a new collection, which is a table in the database.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when you are connected to the database using a client. For more information about the client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You are connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
* If you are using seekdb in server mode or OceanBase Database, make sure that the user has the `CREATE` privilege. For more information about how to view the privileges of the current user, see [View user privileges](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001971368). If the user does not have the privilege, contact the administrator to grant it. For more information about how to directly grant privileges, see [Directly grant privileges](https://en.oceanbase.com/docs/common-oceanbase-database-10000000001974754).
|
||||
|
||||
## Define the table name
|
||||
|
||||
When creating a table, you must first define its name. The following requirements apply when defining the table name:
|
||||
|
||||
* In seekdb, each table name must be unique within the database.
|
||||
|
||||
* The table name cannot exceed 64 characters.
|
||||
|
||||
* We recommend that you give the table a meaningful name instead of using generic names such as t1 or table1. For more information about table naming conventions, see [Table naming conventions](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003977289).
|
||||
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
create_collection(name = name,configuration = configuration, embedding_function = embedding_function )
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the collection to be created. |my_collection|
|
||||
|`configuration`|HNSWConfiguration|No|The index configuration, which specifies the dimension and distance metric. If not provided, the default values `dimension=384` and `distance='cosine'` are used. If set to `None`, the dimension is calculated from the `embedding_function` value. |HNSWConfiguration(dimension=384, distance='cosine')|
|
||||
|`embedding_function`|EmbeddingFunction|No|The function to convert data into vectors. If not provided, `DefaultEmbeddingFunction()(384 dimensions)` is used. If set to `None`, the collection will not include embedding functionality, and if provided, it will be calculated based on `configuration.dimension`.|DefaultEmbeddingFunction()|
|
||||
|
||||
:::info
|
||||
|
||||
When you provide `embedding_function`, the system will automatically calculate the vector dimension by calling this function. If you also provide `configuration.dimension`, it must match the dimension of `embedding_function`. Otherwise, a ValueError will be raised.
|
||||
|
||||
:::
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
from pyseekdb import DefaultEmbeddingFunction, HNSWConfiguration
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
# Create a collection with default embedding function (auto-calculates dimension)
|
||||
collection = client.create_collection(
|
||||
name="my_collection"
|
||||
)
|
||||
|
||||
# Create a collection with custom embedding function
|
||||
ef = UserDefinedEmbeddingFunction() // define your own Embedding function, See section.6
|
||||
config = HNSWConfiguration(dimension=384, distance='cosine') # Must match EF dimension
|
||||
collection = client.create_collection(
|
||||
name="my_collection2",
|
||||
configuration=config,
|
||||
embedding_function=ef
|
||||
)
|
||||
|
||||
# Create a collection without embedding function (vectors must be provided manually)
|
||||
collection = client.create_collection(
|
||||
name="my_collection3",
|
||||
configuration=HNSWConfiguration(dimension=384, distance='cosine'),
|
||||
embedding_function=None # Explicitly disable embedding function
|
||||
)
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
## References
|
||||
|
||||
* [Query a collection](200.get-collection-of-api.md)
|
||||
* [Create or query a collection](250.get-or-create-collection-of-api.md)
|
||||
* [Get a collection list](300.list-collection-of-api.md)
|
||||
* [Count the number of collections](350.count-collection-of-api.md)
|
||||
* [Delete a collection](400.delete-collection-of-api.md)
|
||||
@@ -0,0 +1,89 @@
|
||||
---
|
||||
slug: /get-collection-of-api
|
||||
---
|
||||
|
||||
# get_collection - Get a collection
|
||||
|
||||
The `get_collection()` function is used to retrieve a specified collection.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when connected using a Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect, see [Client](../50.client.md).
|
||||
|
||||
* The collection you want to retrieve exists. If the collection does not exist, an error will be returned.
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
client.get_collection(name,configuration = configuration,embedding_function = embedding_function)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the collection to retrieve. |my_collection|
|
||||
|`configuration`|HNSWConfiguration|No|The index configuration, which specifies the dimension and distance metric. If not provided, the default value `dimension=384, distance='cosine'` will be used. If set to `None`, the dimension will be calculated from the `embedding_function` value. |HNSWConfiguration(dimension=384, distance='cosine')|
|
||||
|`embedding_function`|EmbeddingFunction|No|The function used to convert text to vectors. If not provided, `DefaultEmbeddingFunction()(384 dimensions)` will be used. If set to `None`, the collection will not contain an embedding function. If an embedding function is provided, it will be calculated based on `configuration.dimension`.|DefaultEmbeddingFunction()|
|
||||
|
||||
:::info
|
||||
|
||||
When vectors are not provided for documents/texts, the embedding function set here will be used for all operations on this collection, including add, upsert, update, query, and hybrid_search.
|
||||
|
||||
:::
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
# Get an existing collection (uses default embedding function if collection doesn't have one)
|
||||
collection = client.get_collection("my_collection")
|
||||
print(f"Database: {collection.name}, dimension: {collection.dimension}, embedding_function:{collection.embedding_function}, distance:{collection.distance}, metadata:{collection.metadata}")
|
||||
|
||||
# Get collection with specific embedding function
|
||||
ef = UserDefinedEmbeddingFunction() // define your own Embedding function, See section.6
|
||||
collection = client.get_collection("my_collection", embedding_function=ef)
|
||||
print(f"Database: {collection.name}, dimension: {collection.dimension}, embedding_function:{collection.embedding_function}, distance:{collection.distance}, metadata:{collection.metadata}")
|
||||
|
||||
# Get collection without embedding function
|
||||
collection = client.get_collection("my_collection", embedding_function=None)
|
||||
# Check if collection exists
|
||||
if client.has_collection("my_collection"):
|
||||
collection = client.get_collection("my_collection")
|
||||
print(f"Database: {collection.name}, dimension: {collection.dimension}, embedding_function:{collection.embedding_function}, distance:{collection.distance}, metadata:{collection.metadata}")
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the collection to query. |my_collection|
|
||||
|`dimension`|int|No| |384|
|
||||
|`embedding_function`|EmbeddingFunction|No|DefaultEmbeddingFunction(model_name='all-MiniLM-L6-v2')|
|
||||
|`distance`|string|No| |cosine|
|
||||
|`metadata`|dict|No|Reserved field, currently no data| {} |
|
||||
|
||||
## Response example
|
||||
|
||||
```python
|
||||
Database: my_collection, dimension: 384, embedding_function:DefaultEmbeddingFunction(model_name='all-MiniLM-L6-v2'), distance:cosine, metadata:{}
|
||||
Database: my_collection1, dimension: 384, embedding_function:DefaultEmbeddingFunction(model_name='all-MiniLM-L6-v2'), distance:cosine, metadata:{}
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Create a collection](100.create-collection-of-api.md)
|
||||
* [Create or query a collection](250.get-or-create-collection-of-api.md)
|
||||
* [Get a list of collections](300.list-collection-of-api.md)
|
||||
* [Count the number of collections](350.count-collection-of-api.md)
|
||||
* [Delete a collection](400.delete-collection-of-api.md)
|
||||
@@ -0,0 +1,79 @@
|
||||
---
|
||||
slug: /get-or-create-collection-of-api
|
||||
---
|
||||
|
||||
# get_or_create_collection - Create or query a collection
|
||||
|
||||
The `get_or_create_collection()` function creates or queries a collection. If the collection does not exist in the database, it is created. If it exists, the corresponding result is obtained.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when using a client. For more information about the client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect, see [Client](../50.client.md).
|
||||
|
||||
* If you are using seekdb in server mode or OceanBase Database, ensure that the connected user has the `CREATE` privilege. For more information about how to check the privileges of the current user, see [Check User Privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980135). If the user does not have this privilege, contact the administrator to grant it. For more information about how to directly grant privileges, see [Directly Grant Privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980140).
|
||||
|
||||
## Define a table name
|
||||
|
||||
When creating a table, you need to define a table name. The following requirements must be met:
|
||||
|
||||
* In seekdb, each table name must be unique within the database.
|
||||
|
||||
* The table name must be no longer than 64 characters.
|
||||
|
||||
* It is recommended to use meaningful names for tables instead of generic names like t1 or table1. For more information about table naming conventions, see [Table Naming Conventions](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003977289).
|
||||
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
create_collection(name = name,configuration = configuration, embedding_function = embedding_function )
|
||||
```
|
||||
|
||||
|Parameter|Value Type|Required|Description|Example Value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the collection to be created. |my_collection|
|
||||
|`configuration`|HNSWConfiguration|No|The index configuration with dimension and distance metric. If not provided, the default value is used, which is `dimension=384, distance='cosine'`. If set to `None`, the dimension will be calculated from the `embedding_function` value. |HNSWConfiguration(dimension=384, distance='cosine')|
|
||||
|`embedding_function`|EmbeddingFunction|No|The function to convert to vectors. If not provided, `DefaultEmbeddingFunction()(384 dimensions)` is used. If set to `None`, the collection will not include embedding functionality. If embedding functionality is provided, it will be automatically calculated based on `configuration.dimension`. |DefaultEmbeddingFunction()|
|
||||
|
||||
:::info
|
||||
|
||||
When `embedding_function` is provided, the system will automatically calculate the vector dimension by calling the function. If `configuration.dimension` is also provided, it must match the dimension of `embedding_function`, otherwise a ValueError will be raised.
|
||||
|
||||
:::
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
from pyseekdb import DefaultEmbeddingFunction, HNSWConfiguration
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
# Get or create collection (creates if doesn't exist)
|
||||
collection = client.get_or_create_collection(
|
||||
name="my_collection4",
|
||||
configuration=HNSWConfiguration(dimension=384, distance='cosine'),
|
||||
embedding_function=DefaultEmbeddingFunction()
|
||||
)
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
## References
|
||||
|
||||
* [Create a collection](100.create-collection-of-api.md)
|
||||
* [Query a collection](200.get-collection-of-api.md)
|
||||
* [Get a list of collections](300.list-collection-of-api.md)
|
||||
* [Count collections](350.count-collection-of-api.md)
|
||||
* [Delete a collection](400.delete-collection-of-api.md)
|
||||
@@ -0,0 +1,65 @@
|
||||
---
|
||||
slug: /list-collection-of-api
|
||||
---
|
||||
|
||||
|
||||
# list_collections - Get a list of collections
|
||||
|
||||
The `list_collections()` API is used to obtain all collections.
|
||||
|
||||
:::info
|
||||
|
||||
This API is supported only when you use a Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
client.list_collections()
|
||||
```
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
# List all collections
|
||||
collections = client.list_collections()
|
||||
for coll in collections:
|
||||
print(f"Collection: {coll.name}, Dimension: {coll.dimension}, embedding_function: {coll.embedding_function}, distance: {coll.distance}, metadata: {coll.metadata}")
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the queried collection. |my_collection|
|
||||
|`dimension`|int|No| | 384 |
|
||||
|`embedding_function`|EmbeddingFunction|No|DefaultEmbeddingFunction(model_name='all-MiniLM-L6-v2')|
|
||||
|`distance`|string|No| |cosine|
|
||||
|`metadata`|dict|No|Reserved field. No data is returned. | {} |
|
||||
|
||||
## Response example
|
||||
|
||||
```pyhton
|
||||
Collection: my_collection, Dimension: 384, embedding_function: DefaultEmbeddingFunction(model_name='all-MiniLM-L6-v2'), distance: cosine, metadata: {}
|
||||
Database has 1 collections
|
||||
```
|
||||
|
||||
## References
|
||||
|
||||
* [Create a collection](100.create-collection-of-api.md)
|
||||
* [Query a collection](200.get-collection-of-api.md)
|
||||
* [Create or query a collection](250.get-or-create-collection-of-api.md)
|
||||
* [Count collections](350.count-collection-of-api.md)
|
||||
* [Delete a collection](400.delete-collection-of-api.md)
|
||||
@@ -0,0 +1,56 @@
|
||||
---
|
||||
slug: /count-collection-of-api
|
||||
---
|
||||
|
||||
# count_collection - Count the number of collections
|
||||
|
||||
The `count_collection()` method is used to count the number of collections in the database.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when you are connected to the database using a Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You are connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
client.count_collection()
|
||||
```
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
# Count collections in database
|
||||
collection_count = client.count_collection()
|
||||
print(f"Database has {collection_count} collections")
|
||||
```
|
||||
|
||||
## Return parameters
|
||||
|
||||
None
|
||||
|
||||
## Return example
|
||||
|
||||
```pyhton
|
||||
Database has 1 collections
|
||||
```
|
||||
|
||||
## Related operations
|
||||
|
||||
* [Create a collection](100.create-collection-of-api.md)
|
||||
* [Query a collection](200.get-collection-of-api.md)
|
||||
* [Create or query a collection](250.get-or-create-collection-of-api.md)
|
||||
* [Get a collection list](300.list-collection-of-api.md)
|
||||
* [Delete a collection](400.delete-collection-of-api.md)
|
||||
@@ -0,0 +1,55 @@
|
||||
---
|
||||
slug: /delete-collection-of-api
|
||||
---
|
||||
|
||||
# delete_collection - Delete a Collection
|
||||
|
||||
The `delete_collection()` method is used to delete a specified Collection.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when you are connected to the database using a client. For more information about the client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Get Started](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You are connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
* The Collection you want to delete exists. If the Collection does not exist, an error will be returned.
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
client.delete_collection(name)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`name`|string|Yes|The name of the Collection to be deleted. |my_collection|
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
# Delete a collection
|
||||
client.delete_collection("my_collection")
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
## References
|
||||
|
||||
* [Create a collection](100.create-collection-of-api.md)
|
||||
* [Query a collection](200.get-collection-of-api.md)
|
||||
* [Create or query a collection](250.get-or-create-collection-of-api.md)
|
||||
* [Get a collection list](300.list-collection-of-api.md)
|
||||
* [Count the number of collections](350.count-collection-of-api.md)
|
||||
@@ -0,0 +1,18 @@
|
||||
---
|
||||
slug: /collection-overview-of-api
|
||||
---
|
||||
|
||||
# Manage collections
|
||||
|
||||
In pyseekdb, a collection is a set similar to a table in a database. You can create, query, and delete collections.
|
||||
|
||||
The following API interfaces are supported for managing collections.
|
||||
|
||||
| API interface | Description | Documentation |
|
||||
|---|---|---|
|
||||
| `create_collection()` | Creates a collection. | [Documentation](100.create-collection-of-api.md) |
|
||||
| `get_collection()` | Gets a specified collection. |[Documentation](200.get-collection-of-api.md)|
|
||||
| `get_or_create_collection()` | Creates or queries a collection. If the collection does not exist in the database, it is created. If the collection exists, the corresponding result is obtained. |[Documentation](250.get-or-create-collection-of-api.md)|
|
||||
| `list_collections()` | Gets the collection list of a database. |[Documentation](300.list-collection-of-api.md)|
|
||||
| `count_collection()` | Counts the number of collections in a database |[Documentation](350.count-collection-of-api.md)|
|
||||
| `delete_collection()` | Deletes a specified collection.|[Documentation](400.delete-collection-of-api.md)|
|
||||
@@ -0,0 +1,16 @@
|
||||
---
|
||||
slug: /dml-overview-of-api
|
||||
---
|
||||
|
||||
# DML operations
|
||||
|
||||
DML (Data Manipulation Language) operations allow you to insert, update, and delete data in a collection.
|
||||
|
||||
For DML operations, you can use the following APIs.
|
||||
|
||||
| API | Description | Documentation |
|
||||
|---|---|---|
|
||||
| `add()` | Inserts a new record into a collection. | [Documentation](200.add-data-of-api.md) |
|
||||
| `update()` | Updates an existing record in a collection. |[Documentation](300.update-data-of-api.md)|
|
||||
| `upsert()` | Inserts a new record or updates an existing record. |[Documentation](400.upsert-data-of-api.md)|
|
||||
| `delete()` | Deletes a record from a collection.|[Documentation](500.delete-data-of-api.md)|
|
||||
@@ -0,0 +1,117 @@
|
||||
---
|
||||
slug: /add-data-of-api
|
||||
---
|
||||
|
||||
# add - Insert data
|
||||
|
||||
The `add()` method inserts new data into a collection. If a record with the same ID already exists, an error is returned.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when using a Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
* If you are using seekdb or OceanBase Database in client mode, make sure that the user to which you are connected has the `INSERT` privilege on the table to be operated. For more information about how to view the privileges of the current user, see [View user privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980135). If you do not have the required privilege, contact the administrator to grant you the privilege. For more information about how to directly grant a privilege, see [Directly grant a privilege](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980140).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
add(
|
||||
ids=ids,
|
||||
embeddings=embeddings,
|
||||
documents=documents,
|
||||
metadatas=metadatas
|
||||
)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`ids`|string or List[str]|Yes|The ID of the data to be inserted. You can specify a single ID or an array of IDs.|item1|
|
||||
|`embeddings`|List[float] or List[List[float]]|No|The vector or vectors of the data to be inserted. If you specify this parameter, the value of `embedding_function` is ignored. If you do not specify this parameter, you must specify `documents`, and the `collection` must have an `embedding_function`.|[0.1, 0.2, 0.3]|
|
||||
|`documents`|string or List[str]|No|The document or documents to be inserted. If you do not specify `vectors`, `documents` will be converted to vectors using the `embedding_function` of the `collection`.|"This is a document"|
|
||||
|`metadatas`|dict or List[dict]|No|The metadata or metadata list of the data to be inserted. |`{"category": "AI", "score": 95}`|
|
||||
|
||||
:::info
|
||||
|
||||
The `embedding_function` associated with the collection is set during `create_collection()` or `get_collection()`. You cannot override it for each operation.
|
||||
|
||||
:::
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
from pyseekdb import DefaultEmbeddingFunction, HNSWConfiguration
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
collection = client.create_collection(
|
||||
name="my_collection",
|
||||
configuration=HNSWConfiguration(dimension=3, distance='cosine'),
|
||||
embedding_function=None
|
||||
)
|
||||
|
||||
# Add single item
|
||||
collection.add(
|
||||
ids="item1",
|
||||
embeddings=[0.1, 0.2, 0.3],
|
||||
documents="This is a document",
|
||||
metadatas={"category": "AI", "score": 95}
|
||||
)
|
||||
|
||||
# Add multiple items
|
||||
collection.add(
|
||||
ids=["item4", "item2", "item3"],
|
||||
embeddings=[
|
||||
[0.1, 0.2, 0.4],
|
||||
[0.4, 0.5, 0.6],
|
||||
[0.7, 0.8, 0.9]
|
||||
],
|
||||
documents=[
|
||||
"Document 1",
|
||||
"Document 2",
|
||||
"Document 3"
|
||||
],
|
||||
metadatas=[
|
||||
{"category": "AI", "score": 95},
|
||||
{"category": "ML", "score": 88},
|
||||
{"category": "DL", "score": 92}
|
||||
]
|
||||
)
|
||||
|
||||
# Add with only embeddings
|
||||
collection.add(
|
||||
ids=["vec1", "vec2"],
|
||||
embeddings=[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]]
|
||||
)
|
||||
|
||||
collection1 = client.create_collection(
|
||||
name="my_collection1"
|
||||
)
|
||||
|
||||
# Add with only documents - embeddings auto-generated by embedding_function
|
||||
# Requires: collection must have embedding_function set
|
||||
collection1.add(
|
||||
ids=["doc1", "doc2"],
|
||||
documents=["Text document 1", "Text document 2"],
|
||||
metadatas=[{"tag": "A"}, {"tag": "B"}]
|
||||
)
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
## References
|
||||
|
||||
* [Update data](300.update-data-of-api.md)
|
||||
* [Update or insert data](400.upsert-data-of-api.md)
|
||||
* [Delete data](500.delete-data-of-api.md)
|
||||
@@ -0,0 +1,88 @@
|
||||
---
|
||||
slug: /update-data-of-api
|
||||
---
|
||||
|
||||
# update - Update data
|
||||
|
||||
The `update()` method is used to update existing records in a collection. The record must exist, otherwise an error will be raised.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when using a Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Get Started](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect, see [Client](../50.client.md).
|
||||
|
||||
* If you are using seekdb in client mode or OceanBase Database, make sure that the user to which you have connected has the `UPDATE` privilege on the table to be operated. For more information about how to view the privileges of the current user, see [View User Privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980135). If you do not have this privilege, contact the administrator to grant it to you. For more information about how to directly grant privileges, see [Directly Grant Privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980140).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
update(
|
||||
ids=ids,
|
||||
embeddings=embeddings,
|
||||
documents=documents,
|
||||
metadatas=metadatas
|
||||
)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`ids`|string or List[str]|Yes|The ID to be modified. It can be a single ID or an array of IDs.|item1|
|
||||
|`embeddings`|List[float] or List[List[float]]|No|The new vectors. If provided, they will be used directly (ignoring `embedding_function`). If not provided, you can provide `documents` to automatically generate vectors.|[[0.9, 0.8, 0.7], [0.6, 0.5, 0.4]]|
|
||||
|`documents`|string or List[str]|No|The new documents. If `vectors` are not provided, `documents` will be converted to vectors using the collection's `embedding_function`.|"New document text"|
|
||||
|`metadatas`|dict or List[dict]|No|The new metadata.|`{"category": "AI"}`|
|
||||
|
||||
:::info
|
||||
|
||||
You can update only the `metadatas`. The `embedding_function` used must be associated with the collection.
|
||||
|
||||
:::
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
collection = client.get_collection("my_collection")
|
||||
collection1 = client.get_collection("my_collection1")
|
||||
|
||||
# Update single item
|
||||
collection.update(
|
||||
ids="item1",
|
||||
metadatas={"category": "AI", "score": 98} # Update metadata only
|
||||
)
|
||||
|
||||
# Update multiple items
|
||||
collection.update(
|
||||
ids=["item1", "item2"],
|
||||
embeddings=[[0.9, 0.8, 0.7], [0.6, 0.5, 0.4]], # Update embeddings
|
||||
documents=["Updated document 1", "Updated document 2"] # Update documents
|
||||
)
|
||||
|
||||
# Update with documents only - embeddings auto-generated by embedding_function
|
||||
# Requires: collection must have embedding_function set
|
||||
collection1.update(
|
||||
ids="doc1",
|
||||
documents="New document text", # Embeddings will be auto-generated
|
||||
metadatas={"category": "AI"}
|
||||
)
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
## References
|
||||
|
||||
* [Insert data](200.add-data-of-api.md)
|
||||
* [Update or insert data](400.upsert-data-of-api.md)
|
||||
* [Delete data](500.delete-data-of-api.md)
|
||||
@@ -0,0 +1,93 @@
|
||||
---
|
||||
slug: /upsert-data-of-api
|
||||
---
|
||||
|
||||
# upsert - Update or insert data
|
||||
|
||||
The `upsert()` method is used to insert new records or update existing records. If a record with the given ID already exists, it will be updated; otherwise, a new record will be inserted.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when using a Client connection. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Get Started](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect, see [Client](../50.client.md).
|
||||
|
||||
* If you are using seekdb or OceanBase Database in client mode, ensure that the connected user has the `INSERT` and `UPDATE` privileges on the target table. For more information about how to view the current user privileges, see [View user privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980135). If the user does not have the required privileges, contact the administrator to grant them. For more information about how to directly grant privileges, see [Directly grant privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980140).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
Upsert(
|
||||
ids=ids,
|
||||
embeddings=embeddings,
|
||||
documents=documents,
|
||||
metadatas=metadatas
|
||||
)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`ids`|string or List[str]|Yes|The ID to be added or modified. It can be a single ID or an array of IDs.|item1|
|
||||
|`embeddings`|List[float] or List[List[float]]|No|The vectors. If provided, they will be used directly (ignoring `embedding_function`). If not provided, you can provide `documents` to automatically generate vectors.|[0.1, 0.2, 0.3]|
|
||||
|`documents`|string or List[str]|No|The documents. If `vectors` are not provided, `documents` will be converted to vectors using the collection's `embedding_function`.|"Document text"|
|
||||
|`metadatas`|dict or List[dict]|No|The metadata. |`{"category": "AI"}`|
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
collection = client.get_collection("my_collection")
|
||||
collection1 = client.get_collection("my_collection1")
|
||||
|
||||
# Upsert single item (insert or update)
|
||||
collection.upsert(
|
||||
ids="item1",
|
||||
embeddings=[0.1, 0.2, 0.3],
|
||||
documents="Document text",
|
||||
metadatas={"category": "AI", "score": 95}
|
||||
)
|
||||
|
||||
# Upsert multiple items
|
||||
collection.upsert(
|
||||
ids=["item1", "item2", "item3"],
|
||||
embeddings=[
|
||||
[0.1, 0.2, 0.3],
|
||||
[0.4, 0.5, 0.6],
|
||||
[0.7, 0.8, 0.9]
|
||||
],
|
||||
documents=["Doc 1", "Doc 2", "Doc 3"],
|
||||
metadatas=[
|
||||
{"category": "AI"},
|
||||
{"category": "ML"},
|
||||
{"category": "DL"}
|
||||
]
|
||||
)
|
||||
|
||||
# Upsert with documents only - embeddings auto-generated by embedding_function
|
||||
# Requires: collection must have embedding_function set
|
||||
collection1.upsert(
|
||||
ids=["item1", "item2"],
|
||||
documents=["Document 1", "Document 2"],
|
||||
metadatas=[{"category": "AI"}, {"category": "ML"}]
|
||||
)
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
## References
|
||||
|
||||
* [Insert data](200.add-data-of-api.md)
|
||||
* [Update data](300.update-data-of-api.md)
|
||||
* [Delete data](400.upsert-data-of-api.md)
|
||||
@@ -0,0 +1,87 @@
|
||||
---
|
||||
slug: /delete-data-of-api
|
||||
---
|
||||
|
||||
# delete - Delete data
|
||||
|
||||
`delete()` is used to delete records from a collection. You can delete records by ID, metadata filter, or document filter.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when you are connected to the database using a Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Quick Start](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You are connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
* If you are using seekdb or OceanBase Database in client mode, make sure that the user to whom you are connected has the `DELETE` privilege on the table to be operated. For more information about how to view the privileges of the current user, see [View user privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980135). If you do not have this privilege, contact the administrator to grant it to you. For more information about how to directly grant privileges, see [Directly grant privileges](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003980140).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
Upsert(
|
||||
ids=ids,
|
||||
embeddings=embeddings,
|
||||
documents=documents,
|
||||
metadatas=metadatas
|
||||
)
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`ids`|string or List[str]|Optional|The ID of the record to be deleted. You can specify a single ID or an array of IDs.|item1|
|
||||
|`where`|dict|Optional|The metadata filter.|`{"category": {"$eq": "AI"}}`|
|
||||
|`where_document`|dict|Optional|The document filter.|`{"$contains": "obsolete"}`|
|
||||
|
||||
:::info
|
||||
|
||||
At least one of the `id`, `where`, or `where_document` parameters must be specified.
|
||||
|
||||
:::
|
||||
|
||||
## Request examples
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
collection = client.get_collection("my_collection")
|
||||
|
||||
# Delete by IDs
|
||||
collection.delete(ids=["item1", "item2", "item3"])
|
||||
|
||||
# Delete by single ID
|
||||
collection.delete(ids="item1")
|
||||
|
||||
# Delete by metadata filter
|
||||
collection.delete(where={"category": {"$eq": "AI"}})
|
||||
|
||||
# Delete by comparison operator
|
||||
collection.delete(where={"score": {"$lt": 50}})
|
||||
|
||||
# Delete by document filter
|
||||
collection.delete(where_document={"$contains": "obsolete"})
|
||||
|
||||
# Delete with combined filters
|
||||
collection.delete(
|
||||
where={"category": {"$eq": "AI"}},
|
||||
where_document={"$contains": "deprecated"}
|
||||
)
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
None
|
||||
|
||||
## References
|
||||
|
||||
* [Insert data](200.add-data-of-api.md)
|
||||
* [Update data](300.update-data-of-api.md)
|
||||
* [Update or insert data](400.upsert-data-of-api.md)
|
||||
@@ -0,0 +1,15 @@
|
||||
---
|
||||
slug: /dql-overview-of-api
|
||||
---
|
||||
|
||||
# Overview of DQL
|
||||
|
||||
DQL (Data Query Language) operations allow you to retrieve data from collections using various query methods.
|
||||
|
||||
For DQL operations, the following API interfaces are supported.
|
||||
|
||||
| API Interface | Description | Documentation Link |
|
||||
|---|---|---|
|
||||
| `query()` | A vector similarity search method. | [Documentation](200.query-interfaces-of-api.md) |
|
||||
| `get()` | Queries specific data from a table using an ID, document, or metadata (excluding vectors). | [Documentation](300.get-interfaces-of-api.md) |
|
||||
| `hybrid_search()` | Combines full-text search and vector similarity search using a ranking method. | [Documentation](400.hybrid-search-of-api.md) |
|
||||
@@ -0,0 +1,161 @@
|
||||
---
|
||||
slug: /query-interfaces-of-api
|
||||
---
|
||||
|
||||
# query - vector query
|
||||
|
||||
The `query()` method is used to perform vector similarity search to find the most similar documents to the query vector.
|
||||
|
||||
:::info
|
||||
|
||||
This interface is only available when using the Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Get Started](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
* You have created a collection and inserted data. For more information about how to create a collection and insert data, see [create_collection - Create a collection](../200.collection/100.create-collection-of-api.md) and [add - Insert data](../300.dml/200.add-data-of-api.md).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
query()
|
||||
```
|
||||
|
||||
|Parameter|Value type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`query_embeddings`|List[float] or List[List[float]] |Yes|A single vector or a list of vectors for batch queries; if provided, it will be used directly (ignoring `embedding_function`); if not provided, `query_text` must be provided, and the `collection` must have an `embedding_function`|[1.0, 2.0, 3.0]|
|
||||
|`query_texts`|str or List[str]|No|A single text or a list of texts for query; if provided, it will be used directly (ignoring `embedding_function`); if not provided, `documents` must be provided, and the `collection` must have an `embedding_function`|["my query text"]|
|
||||
|`n_results`|int|Yes|The number of similar results to return, default is 10|3|
|
||||
|`where`|dict |No|Metadata filter conditions.|`{"category": {"$eq": "AI"}}`|
|
||||
|`where_document`|dict|No|Document filter conditions.|`{"$contains": "machine"}`|
|
||||
|`include`|List[str]|No|List of fields to include: `["documents", "metadatas", "embeddings"]`|["documents", "metadatas", "embeddings"]|
|
||||
|
||||
:::info
|
||||
|
||||
The `embedding_function` used is associated with the collection (set during `create_collection()` or `get_collection()`). You cannot override it for each operation.
|
||||
|
||||
:::
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
collection = client.get_collection("my_collection")
|
||||
collection1 = client.get_collection("my_collection1")
|
||||
|
||||
# Basic vector similarity query (embedding_function not used)
|
||||
results = collection.query(
|
||||
query_embeddings=[1.0, 2.0, 3.0],
|
||||
n_results=3
|
||||
)
|
||||
|
||||
# Iterate over results
|
||||
for i in range(len(results["ids"][0])):
|
||||
print(f"ID: {results['ids'][0][i]}, Distance: {results['distances'][0][i]}")
|
||||
if results.get("documents"):
|
||||
print(f"Document: {results['documents'][0][i]}")
|
||||
if results.get("metadatas"):
|
||||
print(f"Metadata: {results['metadatas'][0][i]}")
|
||||
|
||||
# Query by texts - vectors auto-generated by embedding_function
|
||||
# Requires: collection must have embedding_function set
|
||||
results = collection1.query(
|
||||
query_texts=["my query text"],
|
||||
n_results=10
|
||||
)
|
||||
# The collection's embedding_function will automatically convert query_texts to query_embeddings
|
||||
|
||||
# Query by multiple texts (batch query)
|
||||
results = collection1.query(
|
||||
query_texts=["query text 1", "query text 2"],
|
||||
n_results=5
|
||||
)
|
||||
# Returns dict with lists of lists, one list per query text
|
||||
for i in range(len(results["ids"])):
|
||||
print(f"Query {i}: {len(results['ids'][i])} results")
|
||||
|
||||
# Query with metadata filter (using query_texts)
|
||||
results = collection1.query(
|
||||
query_texts=["AI research"],
|
||||
where={"category": {"$eq": "AI"}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# Query with comparison operator (using query_texts)
|
||||
results = collection1.query(
|
||||
query_texts=["machine learning"],
|
||||
where={"score": {"$gte": 90}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# Query with document filter (using query_texts)
|
||||
results = collection1.query(
|
||||
query_texts=["neural networks"],
|
||||
where_document={"$contains": "machine learning"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# Query with combined filters (using query_texts)
|
||||
results = collection1.query(
|
||||
query_texts=["AI research"],
|
||||
where={"category": {"$eq": "AI"}, "score": {"$gte": 90}},
|
||||
where_document={"$contains": "machine"},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# Query with multiple vectors (batch query)
|
||||
results = collection.query(
|
||||
query_embeddings=[[1.0, 2.0, 3.0], [2.0, 3.0, 4.0]],
|
||||
n_results=2
|
||||
)
|
||||
# Returns dict with lists of lists, one list per query vector
|
||||
for i in range(len(results["ids"])):
|
||||
print(f"Query {i}: {len(results['ids'][i])} results")
|
||||
|
||||
# Query with specific fields
|
||||
results = collection.query(
|
||||
query_embeddings=[1.0, 2.0, 3.0],
|
||||
include=["documents", "metadatas", "embeddings"],
|
||||
n_results=3
|
||||
)
|
||||
```
|
||||
|
||||
## Return parameters
|
||||
|
||||
|Parameter|Value type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`ids`|List[List[str]] |Yes|The IDs to add or modify. It can be a single ID or an array of IDs.|item1|
|
||||
|`embeddings`|[List[List[List[float]]]]|No|The vectors; if provided, it will be used directly (ignoring `embedding_function`), if not provided, `documents` can be provided to generate vectors automatically.|[0.1, 0.2, 0.3]|
|
||||
|`documents`|[List[List[Dict]]]|No|The documents. If `vectors` are not provided, `documents` will be converted to vectors using the `embedding_function` of the collection.| "Document text"|
|
||||
|`metadatas`|[List[List[Dict]]]|No|The metadata.|`{"category": "AI"}`|
|
||||
|`distances`|[List[List[Dict]]]|No| |`{"category": "AI"}`|
|
||||
|
||||
## Return example
|
||||
|
||||
```python
|
||||
ID: vec1, Distance: 0.0
|
||||
Document: None
|
||||
Metadata: {}
|
||||
ID: vec2, Distance: 0.025368153802923787
|
||||
Document: None
|
||||
Metadata: {}
|
||||
Query 0: 4 results
|
||||
Query 1: 4 results
|
||||
Query 0: 2 results
|
||||
Query 1: 2 results
|
||||
```
|
||||
|
||||
## Related operations
|
||||
|
||||
* [get - Retrieve](300.get-interfaces-of-api.md)
|
||||
* [Hybrid search](400.hybrid-search-of-api.md)
|
||||
* [Operators](500.filter-operators-of-api.md)
|
||||
@@ -0,0 +1,127 @@
|
||||
---
|
||||
slug: /get-interfaces-of-api
|
||||
---
|
||||
|
||||
# get - Retrieve
|
||||
|
||||
`get()` is used to retrieve documents from a collection without performing vector similarity search.
|
||||
|
||||
It supports filtering by IDs, metadata, and documents.
|
||||
|
||||
:::info
|
||||
|
||||
This interface is only available when using the Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Get Started](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
* You have created a collection and inserted data. For more information about how to create a collection and insert data, see [create_collection - Create a collection](../200.collection/100.create-collection-of-api.md) and [add - Insert data](../300.dml/200.add-data-of-api.md).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
get()
|
||||
```
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`ids`|List[float] or List[List[float]] |Yes|The ID or list of IDs to retrieve.|[1.0, 2.0, 3.0]|
|
||||
|`where`|dict |No|The metadata filter. |`{"category": {"$eq": "AI"}}`|
|
||||
|`where_document`|dict|No|The document filter. |`{"$contains": "machine"}`|
|
||||
|`limit`|dict |No|The maximum number of results to return. |`{"category": {"$eq": "AI"}}`|
|
||||
|`offset`|dict|No|The number of results to skip for pagination. |`{"$contains": "machine"}`|
|
||||
|`include`|List[str]|No|The list of fields to include: `["documents", "metadatas", "embeddings"]`. |["documents", "metadatas", "embeddings"]|
|
||||
|
||||
:::info
|
||||
|
||||
If no parameters are provided, all data is returned.
|
||||
|
||||
:::
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
collection = client.get_collection("my_collection")
|
||||
|
||||
# Get by single ID
|
||||
results = collection.get(ids="123")
|
||||
|
||||
# Get by multiple IDs
|
||||
results = collection.get(ids=["1", "2", "3"])
|
||||
|
||||
# Get by metadata filter
|
||||
results = collection.get(
|
||||
where={"category": {"$eq": "AI"}},
|
||||
limit=10
|
||||
)
|
||||
|
||||
# Get by comparison operator
|
||||
results = collection.get(
|
||||
where={"score": {"$gte": 90}},
|
||||
limit=10
|
||||
)
|
||||
|
||||
# Get by $in operator
|
||||
results = collection.get(
|
||||
where={"tag": {"$in": ["ml", "python"]}},
|
||||
limit=10
|
||||
)
|
||||
|
||||
# Get by logical operators ($or)
|
||||
results = collection.get(
|
||||
where={
|
||||
"$or": [
|
||||
{"category": {"$eq": "AI"}},
|
||||
{"tag": {"$eq": "python"}}
|
||||
]
|
||||
},
|
||||
limit=10
|
||||
)
|
||||
|
||||
# Get by document content filter
|
||||
results = collection.get(
|
||||
where_document={"$contains": "machine learning"},
|
||||
limit=10
|
||||
)
|
||||
|
||||
# Get with combined filters
|
||||
results = collection.get(
|
||||
where={"category": {"$eq": "AI"}},
|
||||
where_document={"$contains": "machine"},
|
||||
limit=10
|
||||
)
|
||||
|
||||
# Get with pagination
|
||||
results = collection.get(limit=2, offset=1)
|
||||
|
||||
# Get with specific fields
|
||||
results = collection.get(
|
||||
ids=["1", "2"],
|
||||
include=["documents", "metadatas", "embeddings"]
|
||||
)
|
||||
|
||||
# Get all data (up to limit)
|
||||
results = collection.get(limit=100)
|
||||
```
|
||||
|
||||
## Response parameters
|
||||
|
||||
* If a single ID is provided: The result contains the get object for that ID.
|
||||
* If multiple IDs are provided: A list of QueryResult objects, one for each ID.
|
||||
* If filters are provided: A QueryResult object containing all matching results.
|
||||
|
||||
## Related operations
|
||||
|
||||
* [Vector query](200.query-interfaces-of-api.md)
|
||||
* [Hybrid search](400.hybrid-search-of-api.md)
|
||||
* [Operators](500.filter-operators-of-api.md)
|
||||
@@ -0,0 +1,140 @@
|
||||
---
|
||||
slug: /hybrid-search-of-api
|
||||
---
|
||||
|
||||
# hybrid_search - Hybrid search
|
||||
|
||||
`hybrid_search()` combines full-text search and vector similarity search with ranking.
|
||||
|
||||
:::info
|
||||
|
||||
This API is only available when using the Client. For more information about the Client, see [Client](../50.client.md).
|
||||
|
||||
:::
|
||||
|
||||
## Prerequisites
|
||||
|
||||
* You have installed pyseekdb. For more information about how to install pyseekdb, see [Get Started](../../10.pyseekdb-sdk/10.pyseekdb-sdk-get-started.md).
|
||||
|
||||
* You have connected to the database. For more information about how to connect to the database, see [Client](../50.client.md).
|
||||
|
||||
* You have created a collection and inserted data. For more information about how to create a collection and insert data, see [create_collection - Create a collection](../200.collection/100.create-collection-of-api.md) and [add - Insert Data](../300.dml/200.add-data-of-api.md).
|
||||
|
||||
## Request parameters
|
||||
|
||||
```python
|
||||
hybrid_search(
|
||||
query={
|
||||
"where_document": ,
|
||||
"where": ,
|
||||
"n_results":
|
||||
},
|
||||
knn={
|
||||
"query_texts":
|
||||
"where":
|
||||
"n_results":
|
||||
},
|
||||
rank=,
|
||||
n_results=,
|
||||
include=
|
||||
)
|
||||
```
|
||||
|
||||
|
||||
* query: full-text search configuration, including the following parameters:
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`where`|dict |Optional|Metadata filter conditions. |`{"category": {"$eq": "AI"}}`|
|
||||
|`where_document`|dict|Optional|Document filter conditions. |`{"$contains": "machine"}`|
|
||||
|`n_results`|int|Yes|Number of results for full-text search.||
|
||||
|
||||
* knn: vector search configuration, including the following parameters:
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|---|---|---|---|---|
|
||||
|`query_embeddings`|List[float] or List[List[float]] |Yes|A single vector or list of vectors for batch queries; if provided, it will be used directly (ignoring `embedding_function`); if not provided, `query_text` must be provided, and the `collection` must have an `embedding_function`|[1.0, 2.0, 3.0]|
|
||||
|`query_texts`|str or List[str]|Optional|A single vector or list of vectors; if provided, it will be used directly (ignoring `embedding_function`); if not provided, `documents` must be provided, and the `collection` must have an `embedding_function`|["my query text"]|
|
||||
|`where`|dict |Optional|Metadata filter conditions. |`{"category": {"$eq": "AI"}}`|
|
||||
|`n_results`|int|Yes|Number of results for vector search.||
|
||||
|
||||
* Other parameters are as follows:
|
||||
|
||||
|Parameter|Type|Required|Description|Example value|
|
||||
|`rank`|dict |Optional|Ranking configuration, for example: `{"rrf": {"rank_window_size": 60, "rank_constant": 60}}`|`{"category": {"$eq": "AI"}}`|
|
||||
|`n_results`|int|Yes|Number of similar results to return. Default value is 10|3|
|
||||
|`include`|List[str]|Optional|List of fields to include: `["documents", "metadatas", "embeddings"]`.|["documents", "metadatas", "embeddings"]|
|
||||
|
||||
|
||||
:::info
|
||||
|
||||
The `embedding_function` used is associated with the collection (set during `create_collection()` or `get_collection()`). You cannot override it for each operation.
|
||||
|
||||
:::
|
||||
|
||||
## Request example
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
collection = client.get_collection("my_collection")
|
||||
collection1 = client.get_collection("my_collection1")
|
||||
|
||||
# Hybrid search with query_embeddings (embedding_function not used)
|
||||
results = collection.hybrid_search(
|
||||
query={
|
||||
"where_document": {"$contains": "machine learning"},
|
||||
"n_results": 10
|
||||
},
|
||||
knn={
|
||||
"query_embeddings": [[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]], # Used directly
|
||||
"n_results": 10
|
||||
},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
|
||||
# Hybrid search with both full-text and vector search (using query_texts)
|
||||
results = collection1.hybrid_search(
|
||||
query={
|
||||
"where_document": {"$contains": "machine learning"},
|
||||
"where": {"category": {"$eq": "science"}},
|
||||
"n_results": 10
|
||||
},
|
||||
knn={
|
||||
"query_texts": ["AI research"], # Will be embedded automatically
|
||||
"where": {"year": {"$gte": 2020}},
|
||||
"n_results": 10
|
||||
},
|
||||
rank={"rrf": {}}, # Reciprocal Rank Fusion
|
||||
n_results=5,
|
||||
include=["documents", "metadatas", "embeddings"]
|
||||
)
|
||||
|
||||
# Hybrid search with multiple query texts (batch)
|
||||
results = collection1.hybrid_search(
|
||||
query={
|
||||
"where_document": {"$contains": "AI"},
|
||||
"n_results": 10
|
||||
},
|
||||
knn={
|
||||
"query_texts": ["machine learning", "neural networks"], # Multiple queries
|
||||
"n_results": 10
|
||||
},
|
||||
rank={"rrf": {}},
|
||||
n_results=5
|
||||
)
|
||||
```
|
||||
|
||||
## Return parameters
|
||||
|
||||
A dictionary containing search results, including ID, distances, metadatas, document, etc.
|
||||
|
||||
## Related operations
|
||||
|
||||
* [Vector query](200.query-interfaces-of-api.md)
|
||||
* [get - Retrieve](300.get-interfaces-of-api.md)
|
||||
* [Operators](500.filter-operators-of-api.md)
|
||||
@@ -0,0 +1,151 @@
|
||||
---
|
||||
slug: /filter-operators-of-api
|
||||
---
|
||||
|
||||
# Operators
|
||||
|
||||
Operators are used to connect operands or parameters and return results. In terms of syntax, operators can appear before, after, or between operands.
|
||||
|
||||
## Operator examples
|
||||
|
||||
### Data filtering (where)
|
||||
|
||||
#### Equal to
|
||||
|
||||
Use `$eq` to indicate equal to, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={"category": {"$eq": "AI"}}
|
||||
```
|
||||
|
||||
#### Not equal to
|
||||
|
||||
Use `$ne` to indicate not equal to, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={"status": {"$ne": "deleted"}}
|
||||
```
|
||||
|
||||
#### Greater than
|
||||
|
||||
Use `$gt` to indicate greater than, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={"score": {"$gt": 90}}
|
||||
```
|
||||
|
||||
#### Greater than or equal to
|
||||
|
||||
Use `$gte` to indicate greater than or equal to, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={"score": {"$gte": 90}}
|
||||
```
|
||||
|
||||
#### Less than
|
||||
|
||||
Use `$lt` to indicate less than, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={"score": {"$lt": 50}}
|
||||
```
|
||||
|
||||
#### Less than or equal to
|
||||
|
||||
Use `$lte` to indicate less than or equal to, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={"score": {"$lte": 50}}
|
||||
```
|
||||
|
||||
#### Contains
|
||||
|
||||
Use `$in` to indicate contains, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={"tag": {"$in": ["ml", "python", "ai"]}}
|
||||
```
|
||||
|
||||
#### Does not contain
|
||||
|
||||
Use `$nin` to indicate does not contain, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={"tag": {"$nin": ["deprecated", "old"]}}
|
||||
```
|
||||
|
||||
#### Logical OR
|
||||
|
||||
Use `$or` to indicate logical OR, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={
|
||||
"$or": [
|
||||
{"category": {"$eq": "AI"}},
|
||||
{"tag": {"$eq": "python"}}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
#### Logical AND
|
||||
|
||||
Use `$and` to indicate logical AND, as shown in the following example:
|
||||
|
||||
```python
|
||||
where={
|
||||
"$and": [
|
||||
{"category": {"$eq": "AI"}},
|
||||
{"score": {"$gte": 90}}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
### Text filtering (where_document)
|
||||
|
||||
#### Full-text search (contains substring)
|
||||
|
||||
Use `$contains` to indicate full-text search, as shown in the following example:
|
||||
|
||||
```python
|
||||
where_document={"$contains": "machine learning"}
|
||||
```
|
||||
|
||||
#### Regular expression
|
||||
|
||||
Use `$regex` to indicate regular expression, as shown in the following example:
|
||||
|
||||
```python
|
||||
where_document={"$regex": "pattern.*"}
|
||||
```
|
||||
|
||||
#### Logical OR
|
||||
|
||||
Use `$or` to indicate logical OR, as shown in the following example:
|
||||
|
||||
```python
|
||||
where_document={
|
||||
"$or": [
|
||||
{"$contains": "machine learning"},
|
||||
{"$contains": "artificial intelligence"}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
#### Logical AND
|
||||
|
||||
Use `$and` to indicate logical AND, as shown in the following example:
|
||||
|
||||
```python
|
||||
where_document={
|
||||
"$and": [
|
||||
{"$contains": "machine"},
|
||||
{"$contains": "learning"}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
## Related operations
|
||||
|
||||
* [Vector query](200.query-interfaces-of-api.md)
|
||||
* [get - Retrieve](300.get-interfaces-of-api.md)
|
||||
* [Hybrid search](400.hybrid-search-of-api.md)
|
||||
@@ -0,0 +1,107 @@
|
||||
---
|
||||
slug: /client
|
||||
---
|
||||
|
||||
# Client
|
||||
|
||||
The `Client` class is used to connect to a database in either embedded mode or server mode. It automatically selects the appropriate connection mode based on the provided parameters.
|
||||
|
||||
:::tip
|
||||
OceanBase Database is a fully self-developed, enterprise-level, native distributed database developed by OceanBase. It achieves financial-grade high availability on ordinary hardware and sets a new standard for automatic, lossless disaster recovery across five IDCs in three regions. It also sets a new benchmark in the TPC-C benchmark test, with a single cluster size exceeding 1,500 nodes. OceanBase Database is cloud-native, highly consistent, and highly compatible with Oracle and MySQL. For more information about OceanBase Database, see [OceanBase Database](https://www.oceanbase.com/docs/oceanbase-database-cn).
|
||||
:::
|
||||
|
||||
## Connect to an embedded seekdb instance
|
||||
|
||||
Use the `Client` class to connect to a local embedded seekdb instance.
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create embedded client
|
||||
client = pyseekdb.Client(
|
||||
#path="./seekdb", # Path to SeekDB data directory
|
||||
#database="test" # Database name
|
||||
)
|
||||
```
|
||||
|
||||
The following table describes the parameters.
|
||||
|
||||
| Parameter | Value type | Required | Description | Example value |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| `path` | string | No | The path to the seekdb data directory. seekdb stores database files in this directory and loads them when it starts. | `./seekdb` |
|
||||
| `database` | string | No | The name of the database. | `test` |
|
||||
|
||||
## Connect to a remote server
|
||||
|
||||
Use the `Client` class to connect to a remote server, which runs seekdb or OceanBase Database.
|
||||
|
||||
:::tip
|
||||
|
||||
Before you connect to a remote server, make sure that you have deployed a server instance of seekdb or OceanBase Database. <br/>For information about how to deploy a server instance of seekdb, see [Overview](../../../400.guides/400.deploy/50.deploy-overview.md).<br/>For information about how to deploy OceanBase Database, see [Overview](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000003976427).
|
||||
|
||||
:::
|
||||
|
||||
Example: Connect to a server instance of seekdb
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create remote server client (SeekDB Server)
|
||||
client = pyseekdb.Client(
|
||||
host="127.0.0.1", # Server host
|
||||
port=2881, # Server port
|
||||
database="test", # Database name
|
||||
user="root", # Username
|
||||
password="" # Password (can be retrieved from SEEKDB_PASSWORD environment variable)
|
||||
)
|
||||
```
|
||||
|
||||
The following table describes the parameters.
|
||||
|
||||
| Parameter | Value type | Required | Description | Example value |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| `host` | string | Yes | The IP address of the server where the instance is located. | `127.0.0.1` |
|
||||
| `prot` | string | Yes | The port number of the instance. The default value is 2881. | `2881` |
|
||||
| `database` | string | Yes | The name of the database. | `test` |
|
||||
| `user` | string | Yes | The username. The default value is root. | `root` |
|
||||
| `password` | string | Yes | The password corresponding to the user. If you do not provide the `password` parameter or specify an empty string, the system retrieves the password from the `SEEKDB_PASSWORD` environment variable. ||
|
||||
|
||||
Example: Connect to OceanBase Database
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
|
||||
# Create remote server client (OceanBase Server)
|
||||
client = pyseekdb.Client(
|
||||
host="127.0.0.1", # Server host
|
||||
port=2881, # Server port (default: 2881)
|
||||
tenant="test", # Tenant name
|
||||
database="test", # Database name
|
||||
user="root", # Username (default: "root")
|
||||
password="" # Password (can be retrieved from SEEKDB_PASSWORD environment variable)
|
||||
)
|
||||
```
|
||||
|
||||
The following table describes the parameters.
|
||||
|
||||
| Parameter | Value type | Required | Description | Example value |
|
||||
| --- | --- | --- | --- | --- |
|
||||
| `host` | string | Yes | The IP address of the server where the database is located. | `127.0.0.1` |
|
||||
| `prot` | string | Yes | The port number of OceanBase Database. The default value is 2881. | `2881` |
|
||||
| `tenant` | string | No | The name of the tenant. This parameter is not required for seekdb. For OceanBase Database, the default value is sys. | `test` |
|
||||
| `database` | string | Yes | The name of the database. | `test` |
|
||||
| `user` | string | Yes | The username corresponding to the tenant. The default value is root. | `root` |
|
||||
| `password` | string | Yes | The password corresponding to the user. If you do not provide the `password` parameter or specify an empty string, the system retrieves the password from the `SEEKDB_PASSWORD` environment variable. ||
|
||||
|
||||
## APIs supported when you use the Client class to connect to a database
|
||||
|
||||
When you use the `Client` class to connect to a database, you can call the following APIs.
|
||||
|
||||
| API | Description | Document link |
|
||||
| --- | --- | --- |
|
||||
| `create_collection()` | Creates a new collection. | [Document](200.collection/100.create-collection-of-api.md) |
|
||||
| `get_collection()` | Queries a specified collection. |[Document](200.collection/200.get-collection-of-api.md)|
|
||||
| `delete_collection()` | Deletes a specified collection. |[Document](200.collection/400.delete-collection-of-api.md)|
|
||||
| `list_collections()` | Lists all collections in the current database.|[Document](200.collection/300.list-collection-of-api.md)|
|
||||
| `get_or_create_collection()` | Queries a specified collection. If the collection does not exist, it is created.|[Document](200.collection/250.get-or-create-collection-of-api.md)|
|
||||
| `count_collection()` | Queries the number of collections in the current database. |[Document](200.collection/350.count-collection-of-api.md)|
|
||||
@@ -0,0 +1,35 @@
|
||||
---
|
||||
slug: /default-embedding-function-of-api
|
||||
---
|
||||
|
||||
# Default embedding function
|
||||
|
||||
An embedding function converts text documents into vector embeddings for similarity search. pyseekdb supports built-in and custom embedding functions.
|
||||
|
||||
The `DefaultEmbeddingFunction` is the default embedding function if none is specified. This function is already available in seekdb and does not need to be created separately.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```python
|
||||
from pyseekdb import DefaultEmbeddingFunction
|
||||
|
||||
# Use default model (all-MiniLM-L6-v2, 384 dimensions)
|
||||
ef = DefaultEmbeddingFunction()
|
||||
|
||||
# Use custom model
|
||||
ef = DefaultEmbeddingFunction()
|
||||
|
||||
# Get embedding dimension
|
||||
print(f"Dimension: {ef.dimension}") # 384
|
||||
|
||||
# Generate embeddings
|
||||
embeddings = ef(["Hello world", "How are you?"])
|
||||
print(f"Generated {len(embeddings)} embeddings, each with {len(embeddings[0])} dimensions")
|
||||
```
|
||||
|
||||
## Related operations
|
||||
|
||||
If you want to use a custom function, you can refer to the following topics to create and use a custom function:
|
||||
|
||||
* [Create a custom embedding function](200.create-custim-embedding-functions-of-api.md)
|
||||
* [Use a custom embedding function](300.using-custom-embedding-functions-of-api.md)
|
||||
@@ -0,0 +1,271 @@
|
||||
---
|
||||
slug: /create-custim-embedding-functions-of-api
|
||||
---
|
||||
|
||||
# Create a custom embedding function
|
||||
|
||||
You can create a custom embedding function by implementing the `EmbeddedFunction` protocol. This function includes the following features:
|
||||
|
||||
* Execute the `__call__` method, which accepts `Documents (str or List[str])` and returns `Embeddings (List[List[float]])`.
|
||||
|
||||
* Optionally implement a dimension attribute to return the vector dimension.
|
||||
|
||||
## Prerequisites
|
||||
|
||||
Before creating a custom embedding function, ensure the following:
|
||||
|
||||
* Implement the `__call__` method:
|
||||
|
||||
* Each vector must have the same dimension.
|
||||
* Input: The type of a single or multiple documents is str or List[str].
|
||||
* Output: The field type of the embedded vectors is `List[List[float]]`.
|
||||
|
||||
* (Recommended) Implement the dimension attribute:
|
||||
* Output: The type of the vectors generated by this function is `int`.
|
||||
* Creating collections helps verify uniqueness.
|
||||
|
||||
* Handle special cases
|
||||
* Convert a single string input to a list.
|
||||
* Return an empty list for empty inputs.
|
||||
* All vectors in the output must have the same dimension.
|
||||
|
||||
## Example 1: Sentence Transformer custom embedding function
|
||||
|
||||
```python
|
||||
from typing import List, Union
|
||||
from pyseekdb import EmbeddingFunction, Client, HNSWConfiguration
|
||||
|
||||
Documents = Union[str, List[str]]
|
||||
Embeddings = List[List[float]]
|
||||
|
||||
class SentenceTransformerCustomEmbeddingFunction(EmbeddingFunction[Documents]):
|
||||
"""
|
||||
A custom embedding function using sentence-transformers with a specific model.
|
||||
"""
|
||||
|
||||
def __init__(self, model_name: str = "all-mpnet-base-v2", device: str = "cpu"): # TODO: your own model name and device
|
||||
"""
|
||||
Initialize the sentence-transformer embedding function.
|
||||
|
||||
Args:
|
||||
model_name: Name of the sentence-transformers model to use
|
||||
device: Device to run the model on ('cpu' or 'cuda')
|
||||
"""
|
||||
self.model_name = model_name
|
||||
self.device = device
|
||||
self._model = None
|
||||
self._dimension = None
|
||||
|
||||
def _ensure_model_loaded(self):
|
||||
"""Lazy load the embedding model"""
|
||||
if self._model is None:
|
||||
try:
|
||||
from sentence_transformers import SentenceTransformer
|
||||
self._model = SentenceTransformer(self.model_name, device=self.device)
|
||||
# Get dimension from model
|
||||
test_embedding = self._model.encode(["test"], convert_to_numpy=True)
|
||||
self._dimension = len(test_embedding[0])
|
||||
except ImportError:
|
||||
raise ImportError(
|
||||
"sentence-transformers is not installed. "
|
||||
"Please install it with: pip install sentence-transformers"
|
||||
)
|
||||
|
||||
@property
|
||||
def dimension(self) -> int:
|
||||
"""Get the dimension of embeddings produced by this function"""
|
||||
self._ensure_model_loaded()
|
||||
return self._dimension
|
||||
|
||||
def __call__(self, input: Documents) -> Embeddings:
|
||||
"""
|
||||
Generate embeddings for the given documents.
|
||||
|
||||
Args:
|
||||
input: Single document (str) or list of documents (List[str])
|
||||
|
||||
Returns:
|
||||
List of embedding vectors
|
||||
"""
|
||||
self._ensure_model_loaded()
|
||||
|
||||
# Handle single string input
|
||||
if isinstance(input, str):
|
||||
input = [input]
|
||||
|
||||
# Handle empty input
|
||||
if not input:
|
||||
return []
|
||||
|
||||
# Generate embeddings
|
||||
embeddings = self._model.encode(
|
||||
input,
|
||||
convert_to_numpy=True,
|
||||
show_progress_bar=False
|
||||
)
|
||||
|
||||
# Convert numpy arrays to lists
|
||||
return [embedding.tolist() for embedding in embeddings]
|
||||
|
||||
# Use the custom embedding function
|
||||
client = Client()
|
||||
|
||||
# Initialize embedding function with all-mpnet-base-v2 model (768 dimensions)
|
||||
ef = SentenceTransformerCustomEmbeddingFunction(
|
||||
model_name='all-mpnet-base-v2', # TODO: your own model name
|
||||
device='cpu' # TODO: your own device
|
||||
)
|
||||
|
||||
# Get the dimension from the embedding function
|
||||
dimension = ef.dimension
|
||||
print(f"Embedding dimension: {dimension}")
|
||||
|
||||
# Create collection with matching dimension
|
||||
collection_name = "my_collection"
|
||||
if client.has_collection(collection_name):
|
||||
client.delete_collection(collection_name)
|
||||
|
||||
collection = client.create_collection(
|
||||
name=collection_name,
|
||||
configuration=HNSWConfiguration(dimension=dimension, distance='cosine'),
|
||||
embedding_function=ef
|
||||
)
|
||||
|
||||
# Test the embedding function
|
||||
print("\nTesting embedding function...")
|
||||
test_documents = ["Hello world", "This is a test", "Sentence transformers are great"]
|
||||
embeddings = ef(test_documents)
|
||||
print(f"Generated {len(embeddings)} embeddings")
|
||||
print(f"Each embedding has {len(embeddings[0])} dimensions")
|
||||
|
||||
# Add some documents to the collection
|
||||
print("\nAdding documents to collection...")
|
||||
collection.add(
|
||||
ids=["1", "2", "3"],
|
||||
documents=test_documents,
|
||||
metadatas=[{"source": "test1"}, {"source": "test2"}, {"source": "test3"}]
|
||||
)
|
||||
|
||||
# Query the collection
|
||||
print("\nQuerying collection...")
|
||||
results = collection.query(
|
||||
query_texts="Hello",
|
||||
n_results=2
|
||||
)
|
||||
|
||||
print("\nQuery results:")
|
||||
for i in range(len(results['ids'][0])):
|
||||
print(f"ID: {results['ids'][0][i]}")
|
||||
print(f"Document: {results['documents'][0][i]}")
|
||||
print(f"Distance: {results['distances'][0][i]}")
|
||||
print()
|
||||
|
||||
# Clean up
|
||||
client.delete_collection(name=collection_name)
|
||||
print("Test completed successfully!")
|
||||
```
|
||||
|
||||
## Example 2: OpenAI embedding function
|
||||
|
||||
```python
|
||||
from typing import List, Union
|
||||
import os
|
||||
from openai import OpenAI
|
||||
from pyseekdb import EmbeddingFunction
|
||||
import pyseekdb
|
||||
|
||||
Documents = Union[str, List[str]]
|
||||
Embeddings = List[List[float]]
|
||||
|
||||
class QWenEmbeddingFunction(EmbeddingFunction[Documents]):
|
||||
"""
|
||||
A custom embedding function using OpenAI's embedding API.
|
||||
"""
|
||||
|
||||
def __init__(self, model_name: str = "", api_key: str = ""): # TODO: your own model name and api key
|
||||
"""
|
||||
Initialize the OpenAI embedding function.
|
||||
|
||||
Args:
|
||||
model_name: Name of the OpenAI embedding model
|
||||
api_key: OpenAI API key (if not provided, uses OPENAI_API_KEY env var)
|
||||
"""
|
||||
self.model_name = model_name
|
||||
self.api_key = api_key or os.environ.get('OPENAI_API_KEY') # TODO: your own api key
|
||||
if not self.api_key:
|
||||
raise ValueError("OpenAI API key is required")
|
||||
|
||||
self._dimension = 1024 # TODO: your own dimension
|
||||
|
||||
@property
|
||||
def dimension(self) -> int:
|
||||
"""Get the dimension of embeddings produced by this function"""
|
||||
if self._dimension is None:
|
||||
# Call API to get dimension (or use known values)
|
||||
raise ValueError("Dimension not set for this model")
|
||||
return self._dimension
|
||||
|
||||
def __call__(self, input: Documents) -> Embeddings:
|
||||
"""
|
||||
Generate embeddings using OpenAI API.
|
||||
|
||||
Args:
|
||||
input: Single document (str) or list of documents (List[str])
|
||||
|
||||
Returns:
|
||||
List of embedding vectors
|
||||
"""
|
||||
# Handle single string input
|
||||
if isinstance(input, str):
|
||||
input = [input]
|
||||
|
||||
# Handle empty input
|
||||
if not input:
|
||||
return []
|
||||
|
||||
# Call OpenAI API
|
||||
client = OpenAI(
|
||||
api_key=self.api_key,
|
||||
base_url="" # TODO: your own base url
|
||||
)
|
||||
response = client.embeddings.create(
|
||||
model=self.model_name,
|
||||
input=input
|
||||
)
|
||||
|
||||
# Extract embeddings
|
||||
embeddings = [item.embedding for item in response.data]
|
||||
return embeddings
|
||||
|
||||
# Use the custom embedding function
|
||||
collection_name = "my_collection"
|
||||
ef = QWenEmbeddingFunction()
|
||||
client = pyseekdb.Client()
|
||||
|
||||
if client.has_collection(collection_name):
|
||||
client.delete_collection(collection_name)
|
||||
|
||||
collection = client.create_collection(
|
||||
name=collection_name,
|
||||
embedding_function=ef
|
||||
)
|
||||
|
||||
collection.add(
|
||||
ids=["1", "2", "3"],
|
||||
documents=["Hello", "World", "Hello World"],
|
||||
metadatas=[{"tag": "A"}, {"tag": "B"}, {"tag": "C"}]
|
||||
)
|
||||
|
||||
results = collection.query(
|
||||
query_texts="Hello",
|
||||
n_results=2
|
||||
)
|
||||
for i in range(len(results['ids'][0])):
|
||||
print(results['ids'][0][i])
|
||||
print(results['documents'][0][i])
|
||||
print(results['metadatas'][0][i])
|
||||
print(results['distances'][0][i])
|
||||
print()
|
||||
|
||||
client.delete_collection(name=collection_name)
|
||||
```
|
||||
@@ -0,0 +1,41 @@
|
||||
---
|
||||
slug: /using-custom-embedding-functions-of-api
|
||||
---
|
||||
|
||||
# Use a custom embedding function
|
||||
|
||||
After you create a custom embedding function, you can use it when you create or get a collection.
|
||||
|
||||
Here is an example:
|
||||
|
||||
```python
|
||||
import pyseekdb
|
||||
from pyseekdb import HNSWConfiguration
|
||||
|
||||
# Create a client
|
||||
client = pyseekdb.Client()
|
||||
|
||||
# Create collection with custom embedding function
|
||||
ef = SentenceTransformerCustomEmbeddingFunction()
|
||||
collection = client.create_collection(
|
||||
name="my_collection",
|
||||
configuration=HNSWConfiguration(dimension=ef.dimension, distance='cosine'),
|
||||
embedding_function=ef
|
||||
)
|
||||
|
||||
# Get collection with custom embedding function
|
||||
collection = client.get_collection("my_collection", embedding_function=ef)
|
||||
|
||||
# Use the collection - documents will be automatically embedded
|
||||
collection.add(
|
||||
ids=["doc1", "doc2"],
|
||||
documents=["Document 1", "Document 2"], # Vectors auto-generated
|
||||
metadatas=[{"tag": "A"}, {"tag": "B"}]
|
||||
)
|
||||
|
||||
# Query with texts - query vectors auto-generated
|
||||
results = collection.query(
|
||||
query_texts=["my query"],
|
||||
n_results=10
|
||||
)
|
||||
```
|
||||
Reference in New Issue
Block a user